
안녕하세요.
저번시간에는 아주 간단하지만 중요한 이야기를 했었죠? 저번시간에 이야기했던 Packing에 대해서 좀더 자세히 공부해 볼까 합니다. 우리가 어떤 어플리케이션을 개발하면서, 하나의 윈도우에 하나 이상의 버튼을 놓으려 할 것입니다. 우리의 첫번째 hello world 예제는 하나의 widget만 썼었죠. 그러나 우리가 하나의 윈도우에 더많은 widget을 놓으려 할 때, 어떻게 그들이 놓일 위치를 제어해야 할까? 여기서 바로 "packing"이란 것이 등장한죠!!
1. 박스 packing의 원리
대부분의 은 앞서의 예제에서처럼(저번주 강의) 박스를 만드는 것으로 이루어집니다. 이들은 우리의 widget을 수평 혹은 수직 방향으로 패킹해 넣을 수 있는, 보이지 않는 widget 컨테이너들이었죠. 수평 박스로의 패킹 widget인 경우, object는 호출 하는 방식에 따라 수평으로 왼쪽에서 오른쪽으로 혹은 오른쪽에서 왼쪽으로 삽입 됩니다. 수직 박스에서는 반대로 수직으로 삽입됩니다. 우리는 원하는 효과를 내기 위해 다른 박스들의 안팎에서 어떻게라도 조합해서 사용할 수 있겠죠?
새로운 수평박스를 만들기 위해 우리는 gtk_hbox_new()를, 그리고 수직박스를 위해서는 gtk_vbox_new()를 이용합니다. gtk_box_pack_start()와 gtk_box_pack_end ()는 이런 컨테이너의 내부에 object들을 위치시키기 위해 사용합니다. gtk_box_ pack_start()함수는 수직박스에서는 위에서 아래쪽으로, 그리고 수평박스에서는 왼쪽에서 오른쪽으로 패킹할 것입니다. 그리고 gtk_box_pack_end()는 이와 반대 방향으로 패킹합니다. 이 함수들을 이용함으로써 우리는 오른쪽 또는 왼쪽으로 widget을 정렬할 수 있고, 원하는 효과를 낼 수 있습니다. 우리는 대부분의 예제에서 gtk_box_pack_start()를 이용할 것입니다. Object는 또다른 컨테이너이거나 widget이 될 수 있습니다. 그리고 사실, 많은 widget들은 실제로 버튼을 포함하고 있는 widget 이지만, 우리는 보통 버튼 안의 라벨만을 이용할 것입니다.
이런 함수호출로써, GTK는 우리가 widget을 놓을 위치를 알게되고 따라서 자동적으로 크기를 조절한다든지 또다른 매력적인 일들을 할 수 있게 됩니다. 또한 우리의 widget이 어떻게 패킹되어야 하느냐에 따른 수많은 옵션들도 있습니다. 우리가 상상하듯이, 이런 방식은 widget을 놓고 만드는 데 있어서 상당한 유연성 을 제공해 줍니다. 매우 기특한 녀석이죠? ㅋㅋ
2. Box에 대해서 좀 더 알아볼까요?
이런 유연성 때문에, GTK에서 박스를 패킹하는 것은 처음엔 혼란스러울지 모릅니다. 많은 옵션들이 있으며, 그들이 어떻게 서로 꿰어 맞춰지는지 바로 알 수는 없을 것입니다. 그러나 결국, 우리는 다섯 가지의 기본적인 스타일을 가지게 됩니다.

각의 줄은 몇 개의 버튼을 가지고 있는 하나의 수평박스(hbox)를 포함합니다. 함수호출 gtk_box_pack은 이 수평박스에 각각의 버튼을 패킹하는 것을 단축한 것입니다. 각각의 버튼은 이 수평박스에 같은 방법으로 패킹됩니다.
이것은 gtk_box_pack_start함수의 선언이다.
void gtk_box_pack_start (GtkBox *box,
GtkWidget *child,
gint expand,
gint fill,
gint padding);
첫번째 인자는 object를 패킹할 박스고 두번째는 그 object입니다. Object는 여기서 모두 버튼이 될 것이고, 따라서 우리는 박스안에 버튼들을 패킹하게 됩니다.
gtk_box_pack_start() 또는 gtk_box_pack_end()에서의 expand라는 인자가 TRUE 일 때, widget은 여백공간을 가득 채우며 박스에 들어가게 될 것입니다. 그리고 그것이 FALSE라면 widget은 적절히 여백을 두게 된다. 이 expand를 FALSE로 두면 우리는widget의 좌우 정렬을 결정할 수 있습니다. 그렇지 않으면 그들은 박스에 가득차서 gtk_box_pack_start 또는 gtk_box_pack_end 어느 쪽을 이용하든지 같은 효과를 가지게 됩니다.
인자 fill은 TRUE일 때 object 자신의 여백공간을 제어합니다. 그리고 FALSE라면 object 자신의 여백공간을 두지 않습니다. 이것은 expand 인자가 TRUE일 때만 효과가 있어요.
새로운 수평박스를 만들 때는 이런 함수가 있습니다.
GtkWidget * gtk_hbox_new (gint homogeneous,
gint spacing);
여기서의 인자 homogeneous는 박스 안의 각 object들이 같은 크기를 가지도록 제어합니다. 즉 수평박스일 경우엔 같은 너비, 수직박스일 경우엔 같은 높이이겠죠? 이것이 세팅되면, gtk_box_pack함수의 expand 인자는 언제나 TRUE가 됩니다.
3. 패킹에 대한 예제 프로그램
/* packbox.c */
#include "gtk/gtk.h"
void
delete_event (GtkWidget *widget, GdkEvent *event, gpointer data)
{
gtk_main_quit ();
}
/* Button_label들로 이루어진 hbox를 만듭니다. */
GtkWidget *make_box (gint homogeneous, gint spacing,
gint expand, gint fill, gint padding)
{
GtkWidget *box;
GtkWidget *button;
char padstr[80];
/* 적당한 homogenous와 spacing을 가진 hbox를 만듭니다. */
box = gtk_hbox_new (homogeneous, spacing);
/* 적절히 세팅된 버튼들을 만듭니다. */
button = gtk_button_new_with_label ("gtk_box_pack");
gtk_box_pack_start (GTK_BOX (box), button, expand, fill, padding);
gtk_widget_show (button);
button = gtk_button_new_with_label ("(box,");
gtk_box_pack_start (GTK_BOX (box), button, expand, fill, padding);
gtk_widget_show (button);
button = gtk_button_new_with_label ("button,");
gtk_box_pack_start (GTK_BOX (box), button, expand, fill, padding);
gtk_widget_show (button);
/* expand의 값에 따르는 라벨을 가진 한 버튼을 만듭니다. */
if (expand == TRUE)
button = gtk_button_new_with_label ("TRUE,");
else
button = gtk_button_new_with_label ("FALSE,");
gtk_box_pack_start (GTK_BOX (box), button, expand, fill, padding);
gtk_widget_show (button);
button = gtk_button_new_with_label (fill ? "TRUE," : "FALSE,");
gtk_box_pack_start (GTK_BOX (box), button, expand, fill, padding);
gtk_widget_show (button);
sprintf (padstr, "%d);", padding);
button = gtk_button_new_with_label (padstr);
gtk_box_pack_start (GTK_BOX (box), button, expand, fill, padding);
gtk_widget_show (button);
return box;
}
int
main (int argc, char *argv[])
{
GtkWidget *window;
GtkWidget *button;
GtkWidget *box1;
GtkWidget *box2;
GtkWidget *separator;
GtkWidget *label;
GtkWidget *quitbox;
int which;
gtk_init (&argc, &argv);
if (argc != 2) {
fprintf (stderr, "usage: packbox num, where num is 1, 2, 3.\n");
/* GTK를 끝내는 부분이며, exit status는 1입니다. */
gtk_exit (1);
}
which = atoi (argv[1]);
/* 윈도우를 만듭니다. */
window = gtk_window_new (GTK_WINDOW_TOPLEVEL);
/* Main 윈도에 destroy 시그널을 연결시켜 줘야 합니다. 이것은 제대로 된 동작을 위해 매우 중요한 것입니다. */
gtk_signal_connect (GTK_OBJECT (window), "delete_event",
GTK_SIGNAL_FUNC (delete_event), NULL);
gtk_container_border_width (GTK_CONTAINER (window), 10);
/* 우리는 수평박스들을 패킹해 넣을 수직박스(vbox)를 만듭니다.저번시간에도 말씀 드렸듯이, 스택 구조를 생각하면 될 것입니다. */
box1 = gtk_vbox_new (FALSE, 0);
switch (which) {
case 1:
/* 새로운 라벨을 만듭니다. */
label = gtk_label_new ("gtk_hbox_new (FALSE, 0);");
/* 라벨들을 왼쪽으로 정렬시킵니다. */
gtk_misc_set_alignment (GTK_MISC (label), 0, 0);
/* 라벨을 수직박스(vbox box1)에 패킹합니다. */
gtk_box_pack_start (GTK_BOX (box1), label, FALSE, FALSE, 0);
/* 라벨을 보여줍니다. */
gtk_widget_show (label);
/* make_box 함수를 적절한 인자로써 호출합니다. */
box2 = make_box (FALSE, 0, FALSE, FALSE, 0);
gtk_box_pack_start (GTK_BOX (box1), box2, FALSE, FALSE, 0);
gtk_widget_show (box2);
box2 = make_box (FALSE, 0, TRUE, FALSE, 0);
gtk_box_pack_start (GTK_BOX (box1), box2, FALSE, FALSE, 0);
gtk_widget_show (box2);
box2 = make_box (FALSE, 0, TRUE, TRUE, 0);
gtk_box_pack_start (GTK_BOX (box1), box2, FALSE, FALSE, 0);
gtk_widget_show (box2);
/* 하나의 separator를 만듭니다 */
separator = gtk_hseparator_new ();
/* separator를 vbox 안으로 패킹합니다. 이들 각각의 widget은 vbox 안으로 패킹되므로, 수직 방향으로 쌓일 것입니다. */
gtk_box_pack_start (GTK_BOX (box1), separator, FALSE, TRUE, 5);
gtk_widget_show (separator);
/* 또다른 라벨을 만들어 그것을 보여줍니다. */
label = gtk_label_new ("gtk_hbox_new (TRUE, 0);");
gtk_misc_set_alignment (GTK_MISC (label), 0, 0);
gtk_box_pack_start (GTK_BOX (box1), label, FALSE, FALSE, 0);
gtk_widget_show (label);
/* 각 인자는 homogeneous, spacing, expand, fill, padding입니다. */
box2 = make_box (TRUE, 0, TRUE, FALSE, 0);
gtk_box_pack_start (GTK_BOX (box1), box2, FALSE, FALSE, 0);
gtk_widget_show (box2);
box2 = make_box (TRUE, 0, TRUE, TRUE, 0);
gtk_box_pack_start (GTK_BOX (box1), box2, FALSE, FALSE, 0);
gtk_widget_show (box2);
/* 또다른 separator */
separator = gtk_hseparator_new ();
/* gtk_box_pack_start 의 마지막 3가지 인자들은 expand, fill, padding 입니다. */
gtk_box_pack_start (GTK_BOX (box1), separator, FALSE, TRUE, 5);
gtk_widget_show (separator);
break;
case 2:
/* 라벨을 새로 만든다. box1은 main()의 시작부분에서 만들어진대로 vbox이다. */
label = gtk_label_new ("gtk_hbox_new (FALSE, 10);");
gtk_misc_set_alignment (GTK_MISC (label), 0, 0);
gtk_box_pack_start (GTK_BOX (box1), label, FALSE, FALSE, 0);
gtk_widget_show (label);
box2 = make_box (FALSE, 10, TRUE, FALSE, 0);
gtk_box_pack_start (GTK_BOX (box1), box2, FALSE, FALSE, 0);
gtk_widget_show (box2);
box2 = make_box (FALSE, 10, TRUE, TRUE, 0);
gtk_box_pack_start (GTK_BOX (box1), box2, FALSE, FALSE, 0);
gtk_widget_show (box2);
separator = gtk_hseparator_new ();
gtk_box_pack_start (GTK_BOX (box1), separator, FALSE, TRUE, 5);
gtk_widget_show (separator);
label = gtk_label_new ("gtk_hbox_new (FALSE, 0);");
gtk_misc_set_alignment (GTK_MISC (label), 0, 0);
gtk_box_pack_start (GTK_BOX (box1), label, FALSE, FALSE, 0);
gtk_widget_show (label);
box2 = make_box (FALSE, 0, TRUE, FALSE, 10);
gtk_box_pack_start (GTK_BOX (box1), box2, FALSE, FALSE, 0);
gtk_widget_show (box2);
box2 = make_box (FALSE, 0, TRUE, TRUE, 10);
gtk_box_pack_start (GTK_BOX (box1), box2, FALSE, FALSE, 0);
gtk_widget_show (box2);
separator = gtk_hseparator_new ();
gtk_box_pack_start (GTK_BOX (box1), separator, FALSE, TRUE, 5);
gtk_widget_show (separator);
break;
case 3:
/* 이것은 gtk_box_pack_end()를 이용하여 widget을 오른쪽 정렬하는 걸 보여줍니다. 먼저, 앞에서처럼 새로운 박스를 하나 만듭니다. */
box2 = make_box (FALSE, 0, FALSE, FALSE, 0);
/* 라벨을 하나 만듭니다. */
label = gtk_label_new ("end");
/* 그것을 gtk_box_pack_end()로써 패킹하므로, make_box()로 만들어진
* hbox의 오른쪽으로 놓여지게 됩니다.
gtk_box_pack_end (GTK_BOX (box2), label, FALSE, FALSE, 0);
/* 라벨을 보입니다. */
gtk_widget_show (label);
/* box2를 box1 안으로 packing합니다. */
gtk_box_pack_start (GTK_BOX (box1), box2, FALSE, FALSE, 0);
gtk_widget_show (box2);
/* bottom 쪽을 위한 separator. */
separator = gtk_hseparator_new ();
/* 이것은 400픽셀의 너비에 5픽셀의 높이(두께)로 separator를 세팅합니다. 이것은 우리가 만든 hbox가 또한 400픽셀의 너비이기 때문이고, "end" 라벨은 hbox의 다른 라벨들과 구분될(separated)것입니다. 그렇지 않으면, hbox 내부의 모든 widget들은 가능한만큼 서로 빽빽히 붙어서 패킹될 것입니다. */
gtk_widget_set_usize (separator, 400, 5);
/* main()함수의 시작부분에서 만들어진 vbox(box1)으로 separator를 패킹합니다. */
gtk_box_pack_start (GTK_BOX (box1), separator, FALSE, TRUE, 5);
gtk_widget_show (separator);
}
/* 또다른 hbox를 만듭니다. */
quitbox = gtk_hbox_new (FALSE, 0);
/* 우리의 quit 버튼입니다. */
button = gtk_button_new_with_label ("Quit");
/* 윈도를 파괴하기 시그널을 세팅합니다. 이것은 위에서 정의된 우리의 시그널 핸들러에 의해 포착될, "destroy"시그널을 윈도로 보내줍니다. */
gtk_signal_connect_object (GTK_OBJECT (button), "clicked",
GTK_SIGNAL_FUNC (gtk_widget_destroy),
GTK_OBJECT (window));
/* quitbox로 버튼을 패킹합니다. gtk_box_pack_start의 마지막 세 인자는 expand, fill, padding입니다. */
gtk_box_pack_start (GTK_BOX (quitbox), button, TRUE, FALSE, 0);
/* vbox(box1) 안으로 quitbox를 패킹합니다. */
gtk_box_pack_start (GTK_BOX (box1), quitbox, FALSE, FALSE, 0);
/* 우리의 모든 widget을 포함하게 된 이 vbox를, main윈도로 패킹. */
gtk_container_add (GTK_CONTAINER (window), box1);
/* 그리고 남아있는 모든 것을 보여줍니다. */
gtk_widget_show (button);
gtk_widget_show (quitbox);
gtk_widget_show (box1);
/* 마지막에 윈도를 보여줘서 모든 것이 한번에 튀어나오며 보입니다. */
gtk_widget_show (window);
gtk_main ();
/* gtk_main_quit()을 호출했다면 제어는 이곳으로 오게되고, gtk_exit()를 호출하면 그렇지 않습니다. */
return 0;
}
역시나도 재미있는것 같아요 ㅋ 저는 인터넷에서 boxpacking 예제를 참고하였어요 ^ ^ 보고 따라하기식으로 하면서 몇가지 추가하고 바꿨더니 위의 화면과는 조금 다른 것이 나오더라구요 ^ ^ 오늘 강의에 사용한 예제를 제대로 알고있다면 몇가지 바꿔보는건 매우 쉬운듯 해요 ^ ^ 아아아 ㅋㅋ 뭔가 긴 것 같지만, 반복적인 소스들, ㅋ (아! 간단하구나?)라는 생각이 들정도 ㅋ
점점 GTK+ 매력에 빠져들고 계신지요? ㅋㅋㅋㅋㅋ
ARM7TDMI 레퍼런스 매뉴얼을 살펴보면 다음과 같이 칩코어의 블럭다이어그램을 찾을 수 있다.

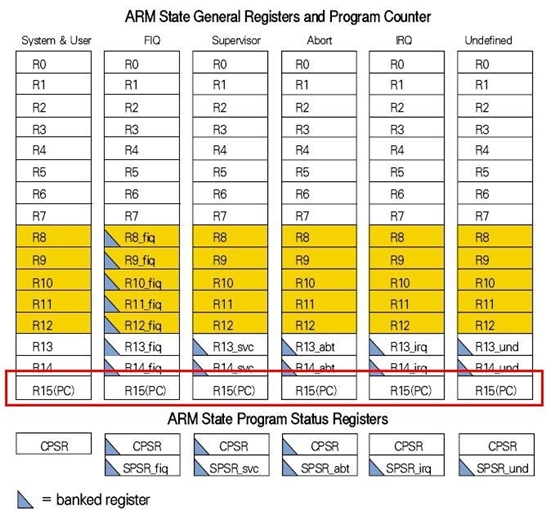
위 그림에서 좌측부분을 보면 디바이스가 프로그램메모리에 접근하기 위해 PC(프로그램 카운터) 정보를 레지스터로부터 가져옴을 볼 수 있는데, 이로부터 resolve하는 어드레스의 크기는 A31:0의 총 32비트임을 보여준다. 즉, SAM7S가 인식하는 메모리의 어드레스 공간은 총 32비트(약 4.3GB)로 구성됨을 알 수 있다. 또한, PC는 32비트의 주소값을 저장해야 하므로, 아래의 그림에서 ARM7TDMI 코어의 동작모드(총 7가지)에 관계없이 레지스터15(R15)를 PC를 위해 사용한다.
SAM7S는 폰노이만 구조로서, 코어에 내장된 물리적 메모리(플래시 및 SRAM)와 각종 I/O 주변장치등을 매모리맵 I/O 방식(Memory Mapped I/O)으로 맵핑시켜 두었다. (아래 그림 참고)

우선 위의 그림의 좌측에서와 같이, 32비트의 어드레스 공간은 크게 3개의 영역으로 나뉘어져 있다. 하위 256MB는 물리적 메모리를 위한 영역으로 할당되어 있고, 상위 256MB는 주변장치를 위한 I/O 공간으로 할당되어 있다. 이들 사이의 3.5GB 정도의 공간은 미정의상태로서 사용되지 않는다.
여기서 하위 256MB의 물리적메모리를 위한 공간을 다시 자세히 살펴보면, 3개의 1MB 영역과 253MB의 미사용영역으로 이루어져 있음을 알 수 있다.(위 그림에서 우측 참고) 여기서, SAM7S의 프로그램메모리(플래시)는 0x10_0000 번지부터 맵핑되어 있으며, 데이터메모리(SRAM)는 0x20_0000 번지부터 맵핑되어 있다. 플래시와 SRAM의 공간은 각각 1MB의 영역만큼 할당되어 있으나, 플래시메모리와 SRAM의 용량은 디바이스마다 그 크기가 정해져 있기 때문에 실제 사용되는 공간은 디바이스의 메모리 용량에 의해 결정된다. (예컨데, SAM7S256의 경우 플래시메모리의 크기가 256KB이므로 256KB의 공간만큼만 사용가능)
디바이스가 리셋이 되면 PC는 0x0000_0000 번지로 점프하므로 이 곳은 아무런 메모리도 할당되어 있지 않아 왠지 모순이 되는 것 같다. 그러나, SAM7S에는 메모리 리맵핑(Memory Re-mapping) 기능이 제공되고 있어, 디폴트로 0x10_0000 번지의 플래시영역이 0x00_0000 번지에 리맵핑되어 있다. 따라서, 리셋이 되면 SAM7S는 플래시메모리의 내용을 읽으면서 부팅이 된다. 반면에, MC_RCR이란 레지스터의 RCB비트를 1로 세팅하면 재배치 명령(Remmap Command)이 실행되어 0x20_0000 번지의 SRAM영역이 0x00_0000 번지로 리맵핑되어 SRAM의 내용을 읽으면서 부팅이된다.
SAM7S의 플래시메모리는 Single Plane으로 구성되어 있기 때문에, 플래시메모리의 내용을 실행하면서 플래시-라이트를 할 수는 없다. 때문에, SAMBA와 같은 경우 이 리맵핑 기능을 이용하여 SRAM영역으로 SAMBA 코드를 복사한 뒤 SRAM영역에서 부팅하여 플래시메모리에 펌웨어를 라이팅하게 된다.
--------------------------------------------------------------------------------------
요즘 떠오르는 MCU 중의 하나 ARM7의 메모리 구조 입니다.
이번에도 오실로 스코프를 하려 했다가, 오실로 스코프가 주제가 아닌데 너무 도배를 하는 것 같아서
ARM7을 블로깅 하게 되었습니다.
위 글 중에서 중요한 것은 그림 입니다.
첫번째 그림의 경우에는 기본적인 흐름도를 나타내주고요.
두번째 그림의 경우에는 시스템의 상태별 레지스터 구조도를 알려줍니다.
참고로 썸상태의 레지스터 구조도는 그림이 없어서 참조하지 못했습니다.
마지막 그림은 플래쉬 메모리의 구조입니다.
이 세가지 그림을 잘 이해하신다면 arm7의 큰 그림은 보실 줄 알게 되는 것 입니다.
자세한 사항은 데이터 시트를 보시면 알 수 있으실 겁니다.
혹, 데이터 시트를 찾으신다면 저에게 연락주세요.^^
드디어 프리유어마인드 프로젝트 관련 마지막 글이군요. 막판 스퍼트가 너무 빡쎠서 10월은 멤버십 출석률 2회를 기록할 정도로-_- 힘을 쏟아 부은 졸작입니다. 하고 나니 너무나 허탈 하더군요. 아무튼 글 들어갑니다.
길줄만 알았던 전시날짜는 정신차리고 보니 이미 지나가고 없었으며,
진정으로 즐겼던 작업은 이렇게 끝나고 돈만 쳐부은 증거(영수증)만이 남아있었다.
후회는 없지만 아쉬움만이 진하게 베어있는 느낌이 바로 이런것!
결과든 뭐든 사람들의 반응이야 어찌되었든 간에 인생의 큰 작업하나 해냈다고 생각한다.
단지...계속되는 아쉬움만이...으악!
실제 전시장의 디피 모습을 공개 해본다.

전시준비 당일날은 정말 미친듯이 패닉 상태였다. 특히 건반 라이트때문에 꽤나 고생했었다...
전시가 시작되고 사람들의 반응은 일단 '멋지다' 라는 것이었지만 뒤에서 보고 있어서 그런건지;; 망가지진 않을까 하는 걱정때문인지는 몰라도 무척 조심스럽게 건반을 누르는 사람들이 더러 있었다. (신나게 짓누르면서 즐기시라구요 ㅠㅠ)
일단은 전공교수님들 그리고 강사분들께서 좋은 평가를 내려주셔서 기분이 업되었으며, 기획서를 갖고 여기저기를 찾아가 보자는 분도 계셔서 일단 현재는 고민중이다. 조금 더 인터랙티브한 부분의 강화를 꾀해야 할듯 싶다.
하고 싶은말은 많지만 지금 코감기가 심해 제정신이 아니므로 작품의 스틸컷을 올리며 끝을 맺는다.( ㅜ_ㅜ// )









* 작품은 저에게 있으니 혹시나 궁금하신분은 언제든지 보여드릴수 있습니다.
작업내용 중 작품을 즐긴 사용자가 자신만의 티셔츠를 받는다는 시나리오가 있다.
실제로 티셔츠를 제작하여 보았는데 예상외로 좋은 퀄리티로 뽑아져 나와 티셔츠
디자인과 함께 실제 착용 모습을 올려본다. 주위 반응도 괜찮았고 '한번 팔아볼까...'
하는 생각도 조금...들긴했지만, 전시회를 축제의 장으로 만들기 위해 추첨을 통해
나눠줄 예정이다.
이제 남은 하나는 아크릴집에 의뢰한 건반부분인데...현재 가장 걱정이 되는 부분이다.
거금을 들인만큼 간지가 뿜어져 나와야 한다. 간지 안나면 끝이다. -_-


다음이 현재 나와있는 여러가지 배경용 무비클립들이다. 애프터 이펙트로 작업하고 있으며,
작업후에 플래시로 불러들여와 무비클립으로 만들어 버린다. 플래시가 워낙에 강력해져서
비트전송률을 9999로 만들어버리면 플래시임에도 불구하고 상당히 깔끔한 영상이 뽑혀나온다.
웹용이 아닌 오프라인 프로젝트이기 때문에 컴퓨터의 성능을 신경쓸 필요는 없다. 최고의 성능을
가진 컴퓨터로 돌려서 잘만 돌아가면 되는것이다. :)



아무튼 이번에는 5번째 이야기 기본 컴퓨터의 구조와 설계중 2번째 이야기 컴퓨터 레지스터에 대해서 이야기 하고자 합니다.
컴퓨터 명령어는 보통 연속적인 메모리상에 위치하고 이것들이 한 번에 하나씩 순차적으로 수행이 됩니다. 따라서 다음 수행될 명령의 주소를 알아낼 수 있는 카운터같은 장치가 필요하겠죠 또한 제어 장치내에는 메모리에서 읽어온 명령어 코드를 저장할 수 있는 레지스터와 데이터를 조작하기 위한 프로세서 레지스터, 그리고 메모리의 주소를 갖고 있는 레지스터가 필요할 것입니다.

위에 그림과 표에서 레지스터 구서오가 각 레지스터의 기능, 비트수를 확인할 수 있습니다.
메모리 장치는 4096워드로 구성되어 있으며, 각 워드는 16비트입닏. 즉 피연산자의 주소를 위해 12비트가 필요하고 3비트는 명령어 코드를 나타내며 나머지 1비트가 직접 주소, 간접 주소를 구별하는 데 사용됩니다. 데이타 레지스터(DR)는 메모리에서 읽어온 피연산자를 저장하며, 누산기(AC) 레지스터는 범용 처리 레지스터로서 사용이 됩니다. 메모리에서 읽어온 명령어는 명령어 레지스터(IR)에 저장되고 임시 레지스터(TR)는 계산 도중의 임시 데이타를 저장합니다. 메모리 주소 레지스터(AR)와 프로그램 카운터(PC)는 메모리의 주소를 나타내어야 하므로 12비트로 구성이 되어 있습니다. PC의 내용이 카운트 순서에 따라 증가함에 따라 명령어들은 분기 명령어를 만날 때까지 순차적으로 수행됩니다. 분기 명령가 수행될 때에는 주소 부분이 PC로 전송되어 다음 수행될 명령어의 주소를 지정하게 됩니다. 이 밖에 입출력 장치로부터 8비트 문자 정보를 송수신하기 위하여 입력 레지스터(INPR)와 출력 레지스터(OUTR)가 사용됩니다.
그렇다면 레지스터들 사이나 레지스터와 메모리 사이에 정보 전송을 어떻게 하는지 궁금해 지기 시작해지지요 기본 컴퓨터에는 정보 전송을 하기 위한 경로를 버스 시스템으로 구성을 합니다.

토요일, 일요일 앓아 누워 있어서 일요일에 블로그를 올리지 못했네여...감기들 조심하세요..(이래서 미리미리 올렸어야 했나...하지만 월요일에 옥상서...) 아무튼 지난 시간에도 이야기 했듯이 궂이 디지털 부속품과 데이터의 표현, 레지스터 전송과 마이크로 연산 부분은 건너뗘야 할거 같습니다. 일단은 너무 전자 회로쪽에 치우쳐도 있고 이대로 가서는 시그가 완료될 때까지 못 맡칠거 같기도 하고요 그럼 기본 컴퓨터의 구조와 설계로 넘어가도록 하겠습니다.
기본 컴퓨터의 구조와 설계(첫번째 명령어 코드)
컴퓨터의 구조는
1. 내부 레지스터
2. 타이밍과 제어구조
3. 명령어 집합
으로 되어지고 앞으로 얘기할 컴퓨터는 우리가 알고있는 pc에 비해 규모가 작지만 설계 과정을 단순하게 보여줄 수 있는 이점이 있습니다. ㅋㅋ(16비트 컴퓨터 정도지요)
디지털 시스템의 내부 조직은 레지스터 안에 저장된 데이처를 가지고 수행되는 마이크로 연산(레지스터에 저장된 데이타를 가지고 실행되는 동작 : 시프트, 카운트, 클리어, 로드)의 시퀀스에 의해 정의 되어집니다. 그렇다면 컴퓨터는 일반적인 용도의 시스템으로 다양한 마이크로 연산을 실행할 수 있고 수행할 연산의 특수한 시퀀스를 명령할 수 도 있습니다. 그리고 시스템의 사용자는 원하는 연산과 피연산자, 처리되는 순서를 기술한 명령어의 집합인 프로그램에 의해서 처리 과정을 제어할 수 있습니다.
그렇다면 명령어의 집합인 프로그램에서의 명령어 정확히 말하면 컴퓨터 명령어란 무엇일까요? 바로 컴퓨터에 대한 일련의 마이크로 연산을 기술한 이진 코드라고 할 수 있습니다. 또한 데이터와 함께 메모리에 저장이 되어있고 제어신호에 의해 제어 레지스터에 옮겨지고 해석되어 제어 함수를 발생함으로서 실행이 됩니다. 이와 같이 명령어를 저장하여 실행하는 개념을 내장 프로그램 이라고 하며 범용 컴퓨터의 가장 중요한 특성이기도 합니다.
앞서 설명한 내용으로 인해서 명령어란 곧 명령어 코드라는 것을 알게 되었습니다. 명령어 코드는 계속 반복되는 이야기지만 컴퓨터에게 어떤 특별한 동작을 수행할 것을 알리는 비트들의 집합으로서 여러 개의 부분으로 나뉘어지는데, 그 중 가장 기본적인 부분은 연산코드 부분입니다.
연산코드는 가감승제나 시프트, 보수 등과 같은 동작을 저의한 비트들의 집합으로서 이 연산 코드 부분이 n 비트로 구성되면 최대한 2^n개의 서로 다른 연산을 실행할 수 있습니다. 또한 하나의 연산코드는 마이크로 연산의 집합으로 볼 수 있기 때문에 때때로 매크로 연산이라고 불리기도 합니다.(햇갈리기 시작...)
명령어코드 이야기를 계속 하자면 명령어코드의 연산부는 실행될 연산을 기술하고 있는데 이러한 연산은 메모리 또는 프로세서 레지스터 안에 저장된 데이차를 가지고 실행되므로 명령어코드는 연산 뿐만 아니라 피연산자가 저장된 레지스터나 메모리 워드, 또한 연산 결과가 저장될 장소를 기술해야 합니다. 이와 같이 여러 개의 부분으로 구성된 명령어 코드의 구성형식은 컴퓨터의 구조 설계자에 의해 결정이 되어 집니다.

저장 프로그램 구조에 대해서 살표볼까요
컴퓨터의 가장 간단한 구성은 단 한 개의 프로세서 레지스터를 가짐으로서 두 개의 부분으로 구성된 명령어 코드를 사용하는 것입니다. 이때 한 부분은 실행할 연산을 그리고 다른 한 부분은 피연산자가 저장된 메모리내의 주소를 기술하게 되는데 메모리로 부터 읽혀진 피연산자 부분은 레지스터에 저장된 데이터와 연산을 실행하게 됩니다. 위의 그림에서 보듯이 4096워드를 가진 기억 장치에 대해서 12비트 주소가(2^12=4096)필요합니다. 16비트 워드를 사용한다면 4비트가 남음으로 총 16가지의 서로 다른 연산을 하게 됩니다. 여기서 한 개의 프로세스 레지스러를 누산기(accumulator 또는 AC)라고 하며 명령어 코드 구성 형식은 4비트로 이루어진 opcode(실행할 연산)와 address(피연산자가 저장된 메모리 주소)로 이루어져 있어서 Address에 의해 지정된 메모리에 데이터와 AC에 저장된 데이터사에에 opcode가 지정한 연산을 수행하게 됩니다.
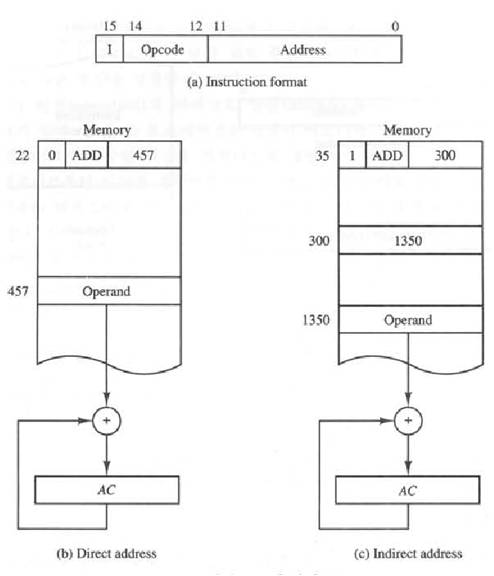
여기서 유효주소라는 개념이 등장하게 되는데 아주 중요하죠 유효주소란 계산형 명령어에서의 피연산자의 주소와 분기형 명령어에서 목적주소를 뜻합니다.
다음에는 5번째 이야기 part2 컴퓨터 레지스터에 대해서 이야기 하도록 하겠습니다.
지금까지 포인트 단위의 산술연산에 관한 포스팅을 하였습니다.
어렵지 않은 내용이라 모두들 쉽게 이해하셨으리라 생각합니다.
실제로도 많이 사용되는 내용이기도 하고 구현 내용도 어렵지 않기 때문에,,
사람이 생각하기에는 크게 느리지 않은 연산이라고 생각하기 쉽지만..
사실 컴퓨터 입장에서는 각 포인트마다 연산을 다 해주어야 하기 때문에,, 많은 연산을 거쳐야 하는 함수임에 틀림 없습니다.
물론 지금 구현된 내용처럼 이미지가 작거나 (저번포스팅들에서 사용된 이미지는 512*512,256*256 이였습니다.)
하면 크게 속도차이가 보이지 않는것은 사실이지만,,,
사람이 살다보면 작은 해상도의 이미지만을 다루는 것이 아니기 때문에 좀 더 고속으로 연산할 수 있는 방법이 필요합니다.
이를 위해 나온것이 바로 LookUp Table연산 방식입니다.
이번포스팅에서는 저번 포스팅에서 다솜돌이 님께서 언급하셨던 고속 연산방식인 룩업테이블에 대하여 이야기하겠습니다.
(다솜돌이님 ㅋ 포스팅 순서가 있었어요 ㅋㅋㅋ 일부로 안쓴거라고요 ㅋㅋ)
1. 기존의 연산방법
 |
| 그렇게 느리다고 생각되지 않습니다만,, 이는 이미지의 크기가 작아서 라고 보시면 됩니다. (때마다 달랐지만..13ms) |
| 코드 보기 |
| public void Mul(int Const) { int TempNum; for (int X = 0; X < 512; X++) { for (int Y = 0; Y < 512; Y++) { TempNum = TestData[X][Y] * Const; TempNum = TempNum < 0 ? 0 : TempNum; TestData[X][Y] = (Byte)TempNum; |
2. LookUpTable을 사용한 경우

LUT를 사용한 연산 |
| 같은 내용의 결과를 내는데 걸린 시간이 거의 1/4까지 줄어든 모습을 확인 할 수 있습니다. |
| 코드 보기 |
| public void MulUsingLookUpTable(int Const) { int TempNum; Byte[] LUT = new Byte[256]; // LookUp Table을 완성합니다. // LUT를 이용하여 연산을 수행합니다. |
뭐가 뭔지 모르겠다.
위나 아래나 for문이 들어갔는데,, 오히려 LookUpTable방식에서는 256번의 for문이 있지않느냐?
그럼 더 느린것이 아닌가?! 라고 하신다면.. 비밀인 여기입니다.
연산수를 따져봅시다.
| 기존의 방식 | LUT의 방식 |
| for (int X = 0; X < 512; X++) { for (int Y = 0; Y < 512; Y++) { TempNum = TestData[X][Y] * Const; TempNum = TempNum < 0 ? TestData[X][Y] = (Byte)TempNum; |
for (int i = 0; i < 256; i++) { TempNum = i * Const; TempNum = TempNum > 255 ? 255 : TempNum; LUT[i] = (Byte) TempNum; } for (int X = 0; X < 512; X++) { for (int Y = 0; Y < 512; Y++) { TestData[X][Y] = LUT[ImageData[X][Y]]; } } |
| 곱하기 연산의 수 512 * 512 = 262144 Saturation을 위한 연산의 수 512 * 512 = 262144 + 대입연산의 수 512 =================================== 524800 |
곱하기 연산의 수 256 Saturation을 위한 연산의 수 256 + 대입연산의 수 512 ================================ 1024 |
| 결과 : 13ms | 결과 : 4ms |
LUT방식은 미리 연산해야 하는 내용을 미리 연산 한 후 ,
연산의 결과에 해당하는 값만을 대입하는 방식이므로 위의 결과와 같이 연산의 수를 대폭 줄일 수 있습니다.
이를 통하여 좀 더 빠른 연산을 할 수 있는것이지요 ^^*
(그림을 표현해서 설명하고 싶었는데,, 살짝귀차니즘이 ㄷㄷㄷㄷ;;;; 추후에 수정하겠습니다.;)
사실 구현할때는 귀찮을 수 도 있지만,,
좀더 빠른 결과를 위해서라면 귀차니즘을 극복하고 사용할 만한 방식인것은 충분합니다..
이번 포스팅은 이만 마칩니다.
1) Name은 의미를 쉽게 파악할 수 있도록 한다.
3) 혼동될 문자는 가급적 사용하지 않도록 한다.
4) 발음 상 혼동이 되는 Name의 사용을 피한다.
5) Global 변수는 등록한 후 임의 갱신을 피한다.
6) 약어(abbreviations)의 사용을 자제한다.
- 불분명한 약어는 사용하지 않는다.
멤버 Field의 네이밍 가이드 라인에서 언더스코어(_, underscore)의 사용에 대한 의견이 분분하다.
언더스코어를 사용하는 개발자는 대/소문자로 구별하는 field/property가 익숙하지 못하다.
언더스코어를 싫어하는 개발자는 _가 사족 같다라는 느낌을 지울 수 없다.
가령
1. 언더스코어 사용 규칙
2. 마이크로 소프트 프레임워크 규칙
public int Age
{
get{return this.age;}
set{this.age=value;}
}
1번과 2번의 규칙 어떤것이 좋냐에 대한 의견이다.
1번은 C, C++ 또는 MFC에서 헝가리안 표기법의 멤버를 나타내는 m_ 에서 m을 제거하고 표기하는 규칙으로, 옹호론자들은 명백하게 노출하지 않을 멤버 필드임을 코딩시에 알 수 있다 이다.
2번의 옹호란자들은 Visual Studio IDE를 사용할때 , 직관적으로 나열되므로 코딩에 편하다. 이다.
1번의 단점은 코딩시에 의미 없는 언더스코어의 나열을 봐야 하는 것이다. 2번의 단점을 멤버임을 대소문자로 구분하기가 약간 힘들다는데 있다. 또한 C#코드에서 대소문자를 구별하지 않는 VB등으로 변환시에 문제가 발생할 수 있다는 점이다.
1번 2번 모두 장단점에 대해 분명하게 말하기는 힘들지만, 2번 스타일을 권하고 싶다.
Field의 이용시에는 명확하게 this 키워드를 이용하며, 인텔리센스의 도움을 더 잘 받기 때문이다.
안녕하세요 조일룡입니다.
오늘은 C++에서 표준 라이브러리로 채택된 STL에 대해 간략하게 알아보겠습니다.
STL은 Standard Template Library의 약자로 템플릿을 이용한 표준 라이브러리.. 뭐 이정도의 의미를 가지고 있습니다.
아래의 주소에서 STL에 대한 모든것을 알 수 있습니다.
http://www.cplusplus.com/reference/stl/
이번 포스팅에서는 템플릿에대해 잠깐 짚어보고, STL에서 제공하는 컨테이너 중 가장 흔히 사용하는 'vector'에 대해 알아보겠습니다.
Template
템플릿을 건너뛰고 싶었지만 역시 언급을 해야할 것 같습니다.
템플릿은 컴파일타임에 자료형을 확정하여 그 자료형에 맞는 코드를 생성하는 C++에서 제공하는 기능입니다.
두개의 정수형 변수를 받아 값을 맞바꾸는 아래의 함수를 봅시다.
{
만약 실수형 변수를 받아 똑같은 일을 하는 함수가 필요하다면 우리는 아래와 같은 함수를 재정의 해야합니다.
{
단지 자료형만 다를 뿐 함수의 몸체는 동일한 구조를 가진 함수를 따로 구현하려니 여간 귀찮은 일이 아닙니다. 그래도 함수를 구현하는 일이니 좀 참아줄만 하네요.. 근데 클레스에서 이 짓을 해야한다면 참을 수 있을까요?
한 프로그램에서 int 형의 자료를 저장하는 스택과 double 형의 자료를 저장하는 스택이 필요한 경우를 가정해봅시다. 이 때 두 가지 형태의 스택을 각각 구현하려 생각하는 짜증이 밀려 오는군요... 하지만 어쩔수 없이 노가다 근성으로 코딩을 하겠지요.
일단 int형 스택을 구현하고 control+C -> contro+V 콤보를 작렬한 후 replace all(int->double)을 감행합니다.
휴.. 그나마 붙여넣기, 모두바꾸기 신공으로 그렇게 큰 노력을 들이지 않고 각각의 클레스를 만들긴 했습니다. ^^;
그런데 프로그램을 실행하다 보니 이상하게 프로그램이 죽는군요.. 어디가 잘못됐는지 찾아보니 스택이 문제입니다..
열심히 디버깅을 해서 오류가 난 지점을 찾아 제대로 작동하게 고쳤습니다.
이제 다시 프로그램을 실행하는데.. 또 죽는군요.. 이건 또 뭘까요.. 디버그를 해서 찾아보니...
아.. 아까전에 int형 스택만 고치고 double형 스택은 안고쳤네요 ㅠㅠ
템플릿을 사용하여 swap을 구현해봅시다.
void swap(ItemType & a, ItemType & b)
{
a = b;
b = temp;
위의 swap과 모양이 약간 다른데요.. 위의 swap에서는 비트연산을 통해 두 변수의 값을 맞바꾸었지만 아래에서는 temp변수를 사용해서 바꿨습니다.
template을 통해 넘어오는 변수의 자료형이 비트연산으로 값을 맞바꿀수 없는 경우가 있을 수 있기 때문인데요.. 예를 들어 string같은 자료형은 비트연산으로 그 값을 맞바꿀 수 없지요.. 대신 저렇게 해야합니다. 물론 대입연산자 재정의는 필수입니다.
Template의 원리
제 경험상 많은 친구들이 template의 사용은 잘 하지만 이게 어떻게 동작하는지는 잘 모릅니다. 어떤 친구는 런타임시에 어떤 메커니즘이 작동하는거 아니냐고 하더군요 그렇기 때문에 template을 쓰면 속도가 느려진다고 하면서...
그 친구에게 유감스럽지만 template은 런타임시에 자료형을 보고 적절한 처리를 하는 것이 아닙니다. C++ 컴파일러가 그렇게까지 똑똑하진 않나봅니다. 사실은 그렇게까지 똑똑해질 필요는 없습니다.
C++은 단지 컴파일시간에 template으로 작성된 함수나 클래스를 사용하는 클라이언트를 보고 필요한 자료형으로 확장된 함수나 클레스를 각각 만들어 줍니다. 그러니깐 붙여넣기 + 모두바꾸기 신공을 컴파일러가 해주는 샘이지요 ㅎㅎ.. 컴파일이 약간 느려질수는 있겠습니다만 템플릿 때문에 실행속도가 느려졌다는 말은 어불성설이겠네요..
vector
vector는 STL에서 제공하는 컨테이너중 하나로 제 생각엔 가장많이 사용되는 컨테이너가 아닐까 생각됩니다.
vector는 배열과 같은 일을 합니다. 연속적인 공간에 템플릿으로 정의된 자료형의 배열을 할당하여 그 후에는 배열처럼 사용할 수 있습니다. 그리고 여러 STL에서 제공되는 algorithm 함수와 함께 강력한 기능을 제공합니다.
vector vs array
c++에선 이미 배열을 기본 데이터타입으로 제공을 합니다. 그런데 vector를 쓰는 이유는 무엇일까요?
가장 큰 이유는 동적할당 때문일 겁니다.
c++에서 배열을 잡을 때 컴파일시간에 배열의 크기를 모르면 배열을 잡을 수 없습니다. 즉 배열의 크기는 변수가 될 수 없고 오로지 상수만이 가능합니다. 이를 극복하기 위해 동적할당이 제공됩니다. c에서는 malloc 함수를 쓰고 c++에서는 new 객체를 사용합니다.
위의 기능을 활용하여 런타임에 적절한 배열의 크기를 알아내서 적절하게 배열을 할당할 수 있습니다.
그럼 왜 vector일까요?
런타임시에도 배열을 얼마나 크게 잡아야 할지 모르는 경우를 생각해봅시다. 예를 들어 장기게임을 하는데 한 수 한 수를 배열에 저장하고 싶습니다. 그런데 장기게임이 몇 수 만에 끝날지는 아무도 모르기 때문에 배열을 잡기가 쉽지 않습니다.
방법중 하나로 배열을 그냥 대충 엄하게 크게 할당하고 시작할 수는 있습니다. 왠만하면 그 배열크기를 초과할 만큼 게임이 진행되지는 않게 크게 잡습니다. 대부분의 게임은 배열을 오버플로우를 발생시키지 않고 종료됩니다. 하지만 여기에는 두가지의 문제점이 있습니다.
첫번재 문제점은 메모리의 낭비입니다. 대부분의 경우 잡아놓은 배열을 다 쓰지 않고 버려진채 게임이 끝납니다.
두번째 문제점은 메모리 오버플로우의 가능성이 있다는 것입니다. 두 기사가 너무 방어적이라 좀처럼 게임이 끝나지 않고 계속 진행되다 보면 잡아놓은 배열을 모두 쓰고도 모자란 상황이 발생할 수 있습니다. 이때 게임은 외마디 오류박스를 띄우고 사라지겠지요.
위의 문제를 해결하기 위해서 일단 배열을 적당히 작게 잡고 필요할때마다 더 큰 배열을 할당하는 방법이 있습니다. 장기를 예로 보면 대부분 장기를 하면 50수까지는 둔다는 정보가 있다고 가정합시다. 그럼 첫 번째 배열은 크기를 50으로 잡습니다. 게임이 진행되다가 50수가 넘으면 100개짜리 배열을 새로 잡고 50수까지의 기록을 100개 짜리 배열에 복사를 합니다. 그후 50개짜리 배열은 메모리에서 해제를 하고 이제부턴 100개짜리 배열을 씁니다. 이런식으로 배열의 크기가 더 커질 필요가 있을 때 마다 새로 메모리를 할당하는 방법이 있습니다만. 귀차니즘이 텍사스 소때처럼 몰려옵니다.
만약 한 프로그램내에서 저런 배열이 여러개 있어야 한다면 각각 구현해야 하는데 정말 귀찮아 죽겠습니다. 그렇다면 객체지향프로그래밍 페러다임을 도입해 클래스로 저런 배열을 구현해 놓고 가져다 쓰는게 그나마 좀 영리한 선택이 되겠지요? 거기에다가 템플릿의 편리함 까지 추가해서 언제어디서나 쓸 수 있게 만들어 놓읍시다.. ㅋㅋㅋ 클래스를 구현할땐 좀 귀찮지만 나중을 생각하면 기분좋은 일이내요
그런데 C++을 사용하는 프로그래머들에게 사막 한 가운데의 오아시스 같은 존재가 있었으니 그것이 바로 STL입니다.
STL에선 바로 저런 배열 클레스를 vector라는 이름으로 제공을 하고 있습니다. 저 같은 귀차니즘에 감염된 종자들에게 구원의 손길과 같게 느껴지네요.
vector를 사용해보자
우선 vector의 멤버함수를 살펴봅시다.
Member functions
| (constructor) | Construct vector (public member function) |
| (destructor) | Vector destructor (public member function) |
| operator= | Copy vector content (public member function) |
Iterators:
| begin | Return iterator to beginning (public member type) |
| end | Return iterator to end (public member function) |
| rbegin | Return reverse iterator to reverse beginning (public member function) |
| rend | Return reverse iterator to reverse end (public member function) |
Capacity:
| size | Return size (public member function) |
| max_size | Return maximum size (public member function) |
| resize | Change size (public member function) |
| capacity | Return size of allocated storage capacity (public member function) |
| empty | Test whether vector is empty (public member function) |
| reserve | Request a change in capacity (public member function) |
Element access:
| operator[] | Access element (public member function) |
| at | Access element (public member function) |
| front | Access first element (public member function) |
| back | Access last element (public member function) |
Modifiers:
| assign | Assign vector content (public member function) |
| push_back | Add element at the end (public member function) |
| pop_back | Delete last element (public member function) |
| insert | Insert elements (public member function) |
| erase | Erase elements (public member function) |
| swap | Swap content (public member function) |
| clear | Clear content (public member function) |
Allocator:
| get_allocator | Get allocator (public member function) |
http://www.cplusplus.com/reference/stl/vector/
100개의 숫자를 임의로 생성하고 비내림차순으로 소팅하여 출력하는 아래의 프로그램을 봅시다.
- #include <cstdlib>
- #include <ctime>
- #include <iostream>
- #include <vector>
- #include <algorithm>
- using namespace std;
- int main()
- {
- int i;
- srand(time(NULL));
- // 벡터를 선언합니다
- vector<int> nums;
- // 100개의 난수를 생성하여 벡터에 추가합니다
- for (i = 0; i < 100; i++)
- nums.push_back(rand());
- // 비내림차순으로 정렬
- sort(nums.begin(), nums.end());
- // 화면에 출력
- for (i = 0; i < 100; i++)
- cout << nums[i] << endl;
- return 0;
- }
위의 프로그램에서는 push_back() 함수를 사용하였습니다만 vector에 추가될 원소의 갯수를 미리 알고 있다면 생성자에서 미리 배열의 크기를 지정하여 시간과 메모리를 아낄 수 있습니다.
- int main()
- {
- int i;
- srand(time(NULL));
- int N = 100;
- vector<int> nums(N, 0);
- for (i = 0; i < N; i++)
- nums[i] = rand();
- sort(nums.begin(), nums.end());
- for (i = 0; i < N; i++)
- cout << nums[i] << endl;
- return 0;
- }
마지막으로 vector<int> 형 배열을 전달받아 합과 평균을 리턴하는 함수를 작성해보겠습니다. 평균은 반올림합니다.
- vector<int> SumAvg(vector<int> array)
- {
- vector<int> ans;
- int sum = 0;
- for (int i = 0; i < array.size(); i++)
- {
- sum += array[i];
- }
- ans.push_back(sum);
- ans.push_back((double)ans / array.size() + 0.5);
- return ans;
- }
이것으로 이번 포스팅은 마치겠습니다. 힘드네요 ^^;
다음 포스팅은 비트연산(bit operation)을 이용한 Brute Force Search 방법에 대해서 쓸까합니다. 간략히 설명하자면 Brute Force는 해의 후보가 될 수 있는 모든 문제 공간을 탑색하여 최적을 찾는 방법입니다. 문제를 해결하는 가장 확실하면서도 쉬운 방법인 반면에 수행 시간이 긴 단점이 있죠.. 주로 모든 문제 공간을 탐색해야 하는 경우에 사용됩니다.

