디지털 이미지의 컬러수는 사실 제한되어 있습니다.
(다만 그것을 우리가 느끼지 못할 정도로 많은 수의 컬러수를 가지고 있을 뿐입니다.)
물론 Gray 이미지 역시 명암 값은 제한되어 있습니다.
저번 포스팅에서 사용하였던 Raw파일에서의 파일포멧은 1byte에 한개의 픽셀정보를 가지고 있는,,
즉 256개의 gray level을 가진 이미지 였습니다.
즉, 0에서 255까지의 256가지의 그래이 컬러를 표현할 수 있다는 의미지요.
자 그럼, 저번 포스팅 내용을 보시면서 의야해 하실만한 점이 떠오르실 텐데요,,,
바로 0보다 작은 수는 어떻게하지?? 255보다 큰 숫자는 어떻게 처리하지? 입니다.
예를들어 한 픽셀이 250의 값을 가지고 있고 여기에 + 10 연산을 한다고 가정해 봅시다.
그렇게 되면 연산된 픽셀의 값은 260...
한개의 픽셀정보를 가지고 있는 용량의 크기는 1byte이기 때문에 255이상의 숫자를 다룰수가 없습니다.
그렇다고 갑자기 파일 포멧을 바꾸어서 한 픽셀을 2byte로 표현할 수도 없는 노릇입니다.
자, 그렇다면 이미지에서 260은 어떻게 표현하면 될까요??
방법은 두가지가 있습니다.
1. Saturation

Saturation을 표현한 그래프
Saturation
1. 침윤(浸潤), 삼투;【화학】 포화 (상태) 《습도 100%의 상태》
2.【광학】 (색의) 채도(彩度) 《색의 포화도;백색과의 혼합 정도》
3.【군사】 (압도적인) 집중 공격
Saturation은 255의 이상인 값들은 모두 255로 표현하는 방법입니다.
그래프에는 표현되지 않았지만, 마찬가지로 0 이하의 값들은 모두 0으로 표현하게 됩니다.
구현은 어렵지 않습니다.
말 그대로 0이하의 값들은 0으로 표현해주고 255이상의 값들은 255로 표현해 주면 되기 때문입니다.
구현내용은 다음과 같습니다.
| TempNum = TempNum < 0 ? 0 : TempNum; TempNum = TempNum > 255 ? 255 : TempNum; |
대부분의 이미지 툴에서 사용하는 방식으로 아시면 됩니다.
참고로, 저번 포스팅에서는 Saturation의 방식으로 이미지를 표현하였습니다.

원본이미지 |

Saturation으로 표현된 +150 |
2. Wrap

Wrap을 표현한 그래프
1.a (감)싸다, 입다 《up, in, with》
2. 감추다, 덮어싸다 《up, in, with》;[종종 수동형으로] 보호하다 《in》
3. [보통 수동형으로] 몰두[열중]하다 《in》
4. <일·회의 등을> 끝내다, 마치다;<숙제 등을> 다 쓰다 《up》;<뉴스 등을> 요약하다
256 = 0, 257 = 1, 258 = 3 ... 501 = 0,,, 와 같이
255의 이상의 값이나, 혹은 0 이하의 값들을 , 0~255를 주기로 계속 반복적으로 표현하는 방식입니다.
구현은 딱히 하지 않습니다.
왜냐하면 위의 Saturation의 방법을 사용하지 않으면 저절로 Wrap방식으로 되기 때문입니다.
자주 사용하는 방식은 Saturation인데 왜 절로 Wrap이 되냐, 라고 하시냐면
그것은 컴퓨터의 데이터 저장방식 때문입니다.
1byte라고 하는것은 0과 1을 표현할 수 있는 1bit의 8개 모임입니다.
즉 1byte를 통해 다음과 같은 수를 표현할 수 있습니다.
00000000 ~ 11111111 (2진수) => 0~ 255 (10진수)
256를 표현하기 위해서, 혹은 그 이상의 수를 표현하기 위해서든 더 많은 bit들이 필요합니다.
참고로 256을 이진수로 나타내면 이렇습니다. => 100000000
이중, 1byte가 표현할 수 있는 비트수는 8개 이므로 100000000중 100000000만이 표현되게 됩니다.
이렇기 때문에, 아무런 구현을 해주지 않으면 저절로 Warp의 방식으로 이미지가 표현되게 됩니다.

원본이미지 |

Wrap으로 표현된 +150 |
대부분의 이미지툴은 이 방식을 사용하지 않기 때문에,
그냥 보신다면 어딘가 잘못된거같은 이미지다 . 라는 느낌을 받으실 겁니다.
이번 포스팅에서는 Saturation과 Wrap의 방식을 알아보았습니다.
다음 포스팅에서는 두 이미지글 가지고 포인트 연산에 관한 이야기를 하고자합니다.
감사합니다.
1. File Layout
앞서 설명한 File heading 에 이어 다음의 내용을 적어준다.
/** ***************************************************************************** **
** includes **
** ***************************************************************************** **/
/** ***************************************************************************** **
** defines **
** ***************************************************************************** **/
/** ***************************************************************************** **
** typedef **
** ***************************************************************************** **/
/** ***************************************************************************** **
** globals **
** ***************************************************************************** **/
/** ***************************************************************************** **
** locals **
** ***************************************************************************** **/
/** ***************************************************************************** **
** forward declarations **
** ***************************************************************************** **/
2. Function Comments
- 각 function definition 에 관한 정보 작성.
- 각 function definition 의 앞부분에 위치.
- 형 태
** Functions : Function name **
** Synopsis : Function 이 사용하는 알고리즘 등을 기술 **
** External Effects : 참조되는 전역변수 **
** Parameters : 파라미터의 의미 **
** Return : 리턴값 및 의미 **
** Error : 에러 발생시 리턴되는 값과 의미 **
** *************************************************** **/
3. Layout
- 한줄에 하나의 명령문 사용.
- 한 line 은 80 column 을 넘지 않는다.
- 한 function 내의 실행문은 300 ~ 500 라인을 넘기지 않는다.(주석포함시 600 ~ 1000)
data들을 예측할 수 있는 algorithm이다. 이 algorithm을 구현하는 방법은 다음과 같은 방법이 있다.
1. LMS(Least Mean Square) algorithm
2. The normal equations
예를들어 주식 시장을 예측할 수 있는 algorithm을 구현하려고 하면, 주식 가격을 결정할 수 있는 factor는 여러가지가
있다. 그 factor중에서 기업 영업 실적(x1), 업종의 경기(x2), 우리나라의 경기(x3) 만을 놓고 주식 시장을 예측한다고 하자.
그럼 이 3개의 요인은 다음과 같은 수식으로 표현할 수 있다.
이 수식에서 training set x1, x2, x3가 주어지고 θ0, θ1, θ2, θ3값을 찾는다면 새로운 data값 x1, x2, x3에 대해 h(x)를 찾을
수 있다. 결국 이 값을 이용해 h(x)를 구할 수 있게 되고, 우리가 값을 예측할 수 있게 되는 것이다. (물론 더 많은 factor들과
다른 다양한 이론들이 필요하겠지만...)
결국 여기에 맞는 θ0, θ1, θ2, θ3를 찾는 것이 regression의 목표이다.
위 수식은 간단히 다음과 같이 표현할 수 있다.
cost function을 가지고 우리가 원하는 값 θ를 찾기 위해서는 J(θ)값을 minimize시키면 된다.
이 알고리즘을 구현하는 방법 3가지중 LMS algorithm에 대해 소개한다.
LMS(Least Mean Square) algorithm
이 방법은 θ를 초기에 예상하는 값으로 설정한 후 이 값이 cost function의 minize값에 따라서 어떻게 변하는지 구하면 된다.
이 θ값을 update하기 위한 rule은 다음과 같다.
이 값의 유도는 생략한다. 이 값을 위의 update rule에 적용하면 다음과 같다.
이 update rule을 이용해
matlab을 이용해 test해 보았다. random하게 200개의 sample을 만들었다. 우선 원래 선은 y=x이고 x는 0부터 20까지 200개의
random data에 gaussian distribution을 이용하여 noise를 추가하였다. gaussian distribution의 mean = 0, variance = 20을
이용하였다.
이를 이용해 regression한 결과는 다음과 같다.


data를 random하게 생성하였지만 구한 line은 동일하다는 것을 알 수 있다.
나머지 The normal equations 방법은 직접 찾아보길....
다음은 classifier의 고전인 perceptron에 대해서 알아보자.
.net framework 가장 처음 포스팅에서 말했던 부분을 다시 살펴봅시다~
.NET이라는 목표를 이루기 위해 실질적으로 돌아가는 Window기반의 응용프로그램을 개발하기 위한 기반이 되는 환경이 바로 .NET Framework라고 이야기 했었구요~
여기 목표라고 써있는 .NET이란 XML기반의 웹 서비스를 통해 서로 다른 시스템을 통합하기 위한 제반 환경 및 기반이라고 이야기 했었습니다.
자 대략적인 내부구조의 개괄적인 설명은 앞의 2포스팅에서 거의 다봤다고 생각이 드는데 XML이란 부분에서 약간 걸리는 것이 있네요 'XML기반의 웹 서비스'라고 할 때 XML이 뭔지 우선 알아야 할 법하여 간략히 정리해 보겠습니다. 아마 XAML이란 용어도 어디선가 들어보셨을 법하여 우선 제목에 같이 써놓았습니다.
XML?
우선 거창하게 영어 이름부터 풀어놓아보겠습니다. Extensible Markup Language. 해석하면 확장가능한 생성 언어 정도겠군요.
역사만 따져보면 XML은 1996년 W3C에서 제안하였구요 1998년 2월 W3C에서 처음으로 표준을 발표한 이래로 꾸준히 발전하면서 새로운 웹을 만들기 위한 여러 시도 중 한가지이면서 새로운 웹의 어찌보면 가장 기반이 되는 기술이라고 할 수 있을 정도로의 큰 부분이기도 합니다.
웹에서 가장 많이 기본으로 보는 것이 HTML입니다. 근데 ML부분이 일단 같은 약자입니다. 웹과 관련된 부분이니 역시 큰 연관관계가 있겠죠. 지금의 웹은 HTML로도 잘 돌아가고 있습니다. 여러 스크립트 언어나 서버 사이드 스크립트언어(PHP와 같은)언어들로 동적으로도 잘 돌아가고 있습니다. 하지만 곰곰히 생각해보면 문제가 있습니다.
최근 크롬이나 파이어폭스 등 브라우져가 널리 배포되면서 이곳저곳 페이지에 들어가보면 IE에서는 잘 돌아가던 페이지가 안되는 부분이 꽤있죠. 특히 초창기에 심했구요. 심지어 브라우저가 제작되던 초기에 IE와 넷스케이프도 자주 겪던 일인데 호환성의 문제가 있습니다. HTML은 분명 display를 위한 정적인 언어지만 이를 보완하기 위해 스크립트 등을 사용하다보니 각 스크립트, 제품별로 상호호환이 안되는 것이 큰 문제였고 지금 또한 그러한 문제가 남아있습니다.
또하나의 커다란 문제는 HTML은 display를 위한 언어, 즉 사용자가 눈으로 보고 읽을 수 만 있다면 컴퓨터는 그냥 뿌려주기만 하면 되는 역할을 가진 언어입니다. 동적으로 뿌려주는 부분은 프로그램으로 결국 클라이언트의 요청을 서버에서 처리하여 정적인 HTML 페이지를 클라이언트에게 보내주는 것일 뿐입니다. 하지만 이러다보면 문제가 자연스레 생깁니다. 요즘 검색엔진이 유난히 많아졌는데 검색어를 넣다보면 완전 엉뚱한 링크들이 모여있는 것을 볼 수 있습니다. 이게 바로 HTML로 이루어진 문서의 문제인데 검색어가 설령 HTML로 이루어진 페이지 속에 들어있다 하더라도 동의어나 문맥의 어떤부분인지 비중은 어떠한지에 대해 컴퓨터는 전혀 알 수 없기 때문에 검색을 하라고 컴퓨터에 시켜도 결국 정확한 값을 얻어오기는 힘들다는 것 입니다.
(이부분을 보완하기위해 수많은 알고리즘과 많은 테스트, 시도 등이 있었고 지금도 있습니다.)
또한 그외에도 HTML은 우선 태크가 한정적이기 때문에 구시대에는 그것만으로 모든 것을 표현 가능했을지 모르나 표준이 추가되지 않는한 확정성이 상대적으로 제한적입니다.
여튼 이런 문제들을 XML로 해결할 수 있다! 가 XML이 나오게 된 이유라고 할 수 있습니다. (즉 HTML의 문제점이 되는 부분을 해결할 수 있다.) 라는 것이죠.
물론 이런 문제점을 보완하기 위해서 제시된 표준이 XML이 최초는 아닙니다. SGML(표준화된 일반 마크업 언어)라고 하여 정부기관 등에서 많이 사용된 언어가 있습니다. 하지만 덩치가 크고 무거운 표준이고 웹이 발달하기 전의 언어라 웹에 대한 지원이 부족하기 때문에 웹에 사용하기에는 부적합했습니다. 하지만 결국 이것이 XML의 모태라고 해도 될 것 같습니다. XML은 현재 SGML의 많은 기술적인 부분을 받아들여 발전해 나가고 있습니다. 간략하게 둘을 비교하자면 아래의 그림과 같습니다.
그럼 다시 정리해서 XML의 장점은 뭐냐! 이렇게 물어본다면

1. 문서의 내용, 디자인이 완전히 분리되어 있다는 겁니다.
(문서의 구조는 XML문서를 통해서 트리구조의 구조적인 형태로 나타냅니다. 그리고 출력, 포매팅은 XSL 문서를 통해서 나타낼 수 있습니다.)2. 다양한 방식의 링크 기능을 제공합니다.
(XLink, XPointer를 이용하면 기존 HTML에서 이용하던 하이퍼링크 이상의 기능을 발휘할 수 있습니다.)3. 표준화된 DTD를 통해서 모든 분야에서 사용이 가능합니다.
(많이 사용되는 WML, SMIL, SVG등이 모두 XML에 기반을 둔언어입니다. 이것은 XML의 DTD를 선언하고 모든 사용자가 그 규칙에 맞추어 사용하면 컴퓨터나 사람이 모두 해석할 수 있는 메타 언어가 된다는 거죠.)
장점을 써놓았지만 처음보시는 분이 딱보고 2가지 이상이해 하셨으면 성공입니다~ 나머지는 차근차근 알아가면되겠구요
자 그럼 XML이란 것이 HTML로 이루어진 문서보다 낫다라는 식으로 앞에서 이야기 했던것은 다름이 아니라 어떤 신문기사에 나온 내용을 XML로 가지고 있다면 이를 다른 미디어로 보내는 것은 XML 포매팅만 새롭게 해준다면 기존의 XML문서를 이용해서 쉽게 할 수 있습니다. (<- 한번만 더 읽어보시고 잘 생각해보세요. 기존의 신문기사를 보고 만약 다른 미디어로 이를 재현하려면 어떠한 노력이 들지를 생각해보세요)
이런 것이 가능한 이유는 XSLT라는 W3C에서 발표한 XML표준안 때문입니다. 각 밴더들이 이에 대한 솔루션을 내놓고 있구요. 예시를 들자면 XSL의 포매팅 객체 (Formatting Object)를 이용해서 PDF파일(아크로뱃리더)형식과 HTML과 WAP의 3가지 형태로 출력하는 외국의 사이트를 본적이 있네요.. (http://www.renderx.com/)
이런 식으로 최근에는 XML이 보편화 되어가고 있습니다.
이렇게 좋은 것을 왜 널리 안쓰고 있느냐라고 하지만 XML은 현재 제한된 부분만 구현되어있고 개발되어지고 있다라는 것을 알고 이번 포스팅은 여기까지 하도록 하겠습니다. (표준이 제시되었다고 해서 완성된 것은 아니죠)
Referenced by XML DeveloperGroup Community & Wikipedia
저번 포스팅에서 예고해드린데로 이번에는 재귀호출에 대해서 다뤄볼까합니다.
물론 멤버십에 계신분들중에 재귀호출을 어려워 하실 분들은 없으리라 생각하는데요, 학교에서 주위를 살펴보면 재귀호출을 잘 못하는 친구나, 후배나, 등등 많은 것 같습니다. 그 만큼 재귀호출이 직관적으로 이해가 잘 안되는 부분인가 봅니다. C++과 싸우다 보면 포인터에서 한 번 좌절을 하게 되고 포인터를 넘고나면 재귀호출이 또다시 태클을 건다는.. 뭐 그런 전설이 내려오는데요.. 저도 지금 재귀호출을 어떻게 다뤄야할지 막막합니다 ㅠㅠ
뭐.. 어쨌든..... 각설하고 시작하겠습니다.

재귀(Recursion)
주어진 문제를 재귀적으로 푼다는 말은 문제의 답이 그 문제와 동일한 형태의 더 작은 부분문제(sub problem)의 답에 의존적(dependency)이다 라는 의미를 가지고 있습니다.
흠.. 무슨말인지 모르겠습니다. 이해를 돕기 위해 쉬운 예를 들어 보겠습니다.
누가 저 작품에 레고블럭이 몇 개가 쓰였는지 물어봅니다.
도저히 한눈에 레보블럭이 몇 개가 쓰였는지 알지 못하겠습니다.
레고를 쪼갭니다.
아직 각각이 몇개씩인지 모르겠습니다.
다시 레고를 쪼갭니다.
아직 모르겠습니다.
다시 레고를 쪼갭니다.
...
...
이제 몇 개인지 눈에 보입니다.
쪼갰던 레고를 합칩니다.
각각의 답도 같이 합칩니다.
쪼갰던 다른 레고를 합칩니다.
각각의 답도 같이 합칩니다.
계속 합칩니다.
...
처음의 레고 작품으로 돌아왔습니다.
이제 이 작품에 레고블럭이 몇 개가 쓰였는지 압니다.
위의 과정을 분할정복(Divide and Conquer)라고 합니다.
재귀호출은 분할정복, 백트레킹 뭐 이런 녀석들이랑 땔래야 땔 수 없는 사이인데요, 이 녀석들의 특징이 주어진 문제를 더 작은 문제로 분할하여 문제를 해결한다는 점에서 동일한 특성을 가지고 있기때문입니다. 실제로 거의 대부분의 경우 D&C나 백트레킹은 재귀함수로 구현하는 경우가 많습니다.
재귀함수(Recursive Function)
재귀적으로 문제를 푸는 함수를 재귀함수라고 하고 직간접적으로 자기자신을 호출합니다.
재귀적으로 문제를 푼다(동일한 형태의 다 작은 부분문제를 풀어나감)는 것을 생각해 봤을 때, 반복이 진행될 때마다 동일한 작업을 해야 한다는 것을 짐작할 수 있습니다.(동일한 형태의 문제를 푸니깐;) 그리고 더 이상 문제를 쪼개지 않아도 되는 상황에 언젠가는 도달해야 합니다. 따라서 재귀함수는 자기자신을 호출하고(동일한 형태) 언젠가는 종료를 해야합니다.
또.. 무슨 말인지 모르겠습니다. 프로그래머는 코드로 말한다고 코드를 보는게 더 쉽겠네요
수도코드보기
Begin
If It can possible to solve this problem then
Solve problem
Return solution
Else
Divide problem to subproblem1 and subproblem2
// 쪼갠 문제를 가지고 재귀호출 ㄱㄱㅆ
Type res2 = RecursiveFunction(subproblem2)
// 쪼개진 문제의 답을 조합하여 이 문제의 답을 구해 리턴
Return compose res1 and res2
현실적인 예를 들기위해 n!을 재귀적으로 구해보도록 합시다.
여러분은 10!이 얼마인지 아십니까?? 모르겠죠?? 저도 모릅니다. 그래도 10! 은 9!에다가 10을 곱했다는 거는 알 것 같습니다.. 모르시면 중학교 수학책을 찾아보십시오.
코딩을 하기 위해서는 수식을 일반화할 필요가 있는데요 지금껀 일반화하기 그닥 어렵지 않습니다.
= (n-1) * n (n >= 2) - 재귀호출
위와 같은 식을 점화식(Recurrence relation)이라고 합니다. 고등학교 수학시간에 수열의 일반항을 구할때 많이 들었던 용어일겁니다. 각설하고 점화식을 알았으면 바로 그래도 코드로 옮겨주면 됩니다.
- int fac(int n)
- {
- if (n <= 1) return 1;
- return n * fac(n-1);
- }
제가 주로 사용하는 언어가 C++인 관계로 C++로 코딩했습니다. 뭐 근데 생각해보니 저 함수는 자바나 C#으로 짜도 저렇게 나오겠네요 쿨럭; 여튼 앞으로도 계속 C++로 작성하겠습니다.
호출이 일어나는 순서를 도식화 하면 더 알기 쉽겠죠?
fac(5)를 호출했을 때 상태의 변화를 도식화하면 아래와 같습니다.
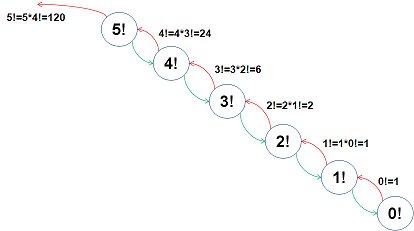
뭐 여기까지 이미 다 알고계신 내용이었을테구요..
재귀함수를 작성하다 보면 의도하지 않은 크리티컬한 문제에 봉착하게 되는 경우가 있습니다. 아래의 예를 봅시다.
공대를 다니면서 절대 피할수 없는 수열이 있습니다. 바로 피보나치수열인데요. 점화식은 아래와 같습니다.
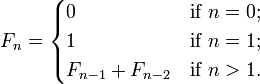
점화식대로 재귀함수를 코딩하면 이렇게 나오죠
- int fib(int n)
- {
- if (n <= 1) return n;
- return fib(n-1) + fib(n-2);
- }
그런데 여기에 엄청난 문제가 있습니다.. 눈치 채셨습니까??
함수의 콜 상태를 도식화 해보면 이렇습니다.
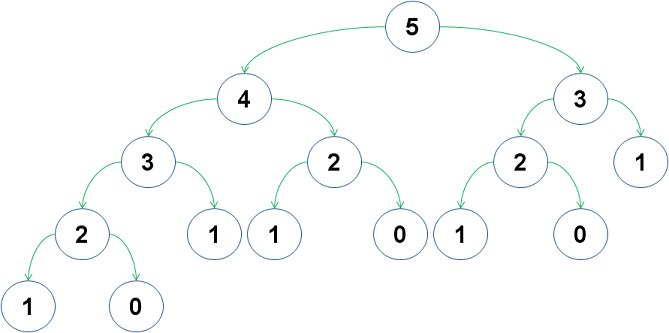
이 엄청난 문제 눈치채셧습니까??
그림을 잘 보면 fib(3)이 두번 계산 되는걸 알 수 있습니다. fib(2)는 3번이구요 fib(1)은 5번이나 호출되네요..
저게 fib(5)를 구하는 그림이라 그렇지 fib(50)을 구한다고 생각해보십시오.. 끔찍합니다..
분석을 해보면 저런식으로 함수를 구현하게 되면 fib(n)을 구하는데 대략 2^n번의 함수 호출이 발생합니다. fib(50)을 구한다면??또 이 표현 안할수가 없네요. 지구가 멸망할때까지 답을 못봅니다
다행이도 이런 문제를 해결하는 Memoization이라는 기법(Memorization이 아닙니다)이 있는데요, 언젠가 포스팅을 하겠습니다.
하노이의 탑
마지막으로 하노이 탑을 옮겨보도록 하겠습니다.
하노이의 탑 하러가기
하노이의 탑은 세개의 공간 중 한 공간에 쌓여진 탑을 한 번에 하나의 층만 이동하여 다른 공간으로 이동하는 문제인데요 이동하는 도중에 크기가 더 큰 층이 작은 층 위에 올라올 수 없습니다.
최소의 횟수로 하노이의 탑을 옮기는 방법은 단 한가지가 존재하는데 옮기는 횟수가 무려 2^n-1 번이나 됩니다.
인도의 베레니스에 있는 한 사원에 64층의 하노이 탑이 있는데 이 탑을 위의 규칙에따라 옮기면 탑은 무너지고 세상은 종말한다라는 예언이 전해오는데요.. 사실 64층의 탑을 사람의 힘으로 옮기려면 영겁의 세월이 걸립니다. 그 전에 세상이 종말하겠죠;
그럼 본격적으로 하노이 탑을 옮겨보도록 하겠습니다.
source(S)에 있는 n층의 하노이탑을 destination(D)으로 옮기고자 합니다. 그리고 이를 위해 temp(T)라는 공간이 준비되어 있습니다.
크게 생각해보면 n층의 하노이 탑을 옮기려면 n-1층까지 모든 블록을 S->T로 옮기고 젤 마지막 조각을 S->D로 옮긴 다음에 T에 있는 n-1층의 하노이탑을 D위에 쌓으면 됩니다. 그럼 여기에서 n-1층의 하노이 탑을 옮기는 과정(S->T, T->D)이 필요한데, 이 과정은 n층의 하노이 탑을 옮기는 과정과 방법이 같습니다.
우선 n-1층의 탑을 S->T로 옮기는 것을 생각해봅시다. 이경우 S가 원본이되고 T가 목적지가 됩니다. 각각 S'과 D'이라고 하고 남은 슬롯인 D를 이 경우에서는 임시공간으로 사용하므로 T'이라하면, 우선 n-2층까지 S'->T'으로 옮기고 n-1층을 S'->D'으로 옮깁니다. 그 후 T'에 있는 n-2층까지의 블록을 D'위로 옮겨놓으면 됩니다. 여기에서 또 n-2층을 옮기는 방법을 알아야 하는데요 n-1층을 옮기는 방법과 똑같이 하면 됩니다. 이 과정을 1층이 될때까지 재귀적으로 수행하면 됩니다.
그림보기
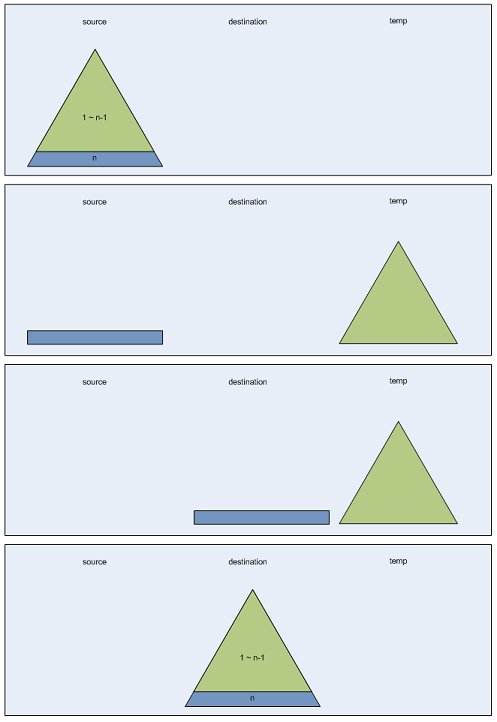
이제 위의 과정을 함수로 작성해봅시다.
함수 TowerOfHanoi(int n, int a, int b, int c) 을 n층의 하노이이 탑을 a에서 b로 c의 임시공간을 이용해서 옮기는 함수라고 정의하면 함수의 몸체는 위에서 설명한 세단계(n-1층까지 a->c로 옮김, n층을 a->b로 옮김, n-1층까지 c->b로 옮김)으로 구성됩니다. 이 세 단계를 모두 재귀호출을 이용하여 구현하면 하노이의 탑은 아래와 같이 간단하게 구현됩니다.
- // 하노이의 탑
- // n층의 탑을 a에서 b로 옮긴다. c는 여유공간
- void TowerOfHanoi(int n, int a, int b, int c)
- {
- // 종료조건
- if (n == 1)
- {
- printf("%d -> %d\n", a, b);
- return;
- }
- // 1~n-1층까지 a->c로 옮긴다
- TowerOfHanoi(n-1, a, c, b);
- // n번째 층을 a->b로 옮긴다
- TowerOfHanoi(1, a, b, c);
- // 1~n-1층까지 c->b로 옮긴다
- TowerOfHanoi(n-1, c, b, a);
- }
TowerOfHanoi(4, 1, 2, 3); 을 실행한 결과는 다음과 같습니다.
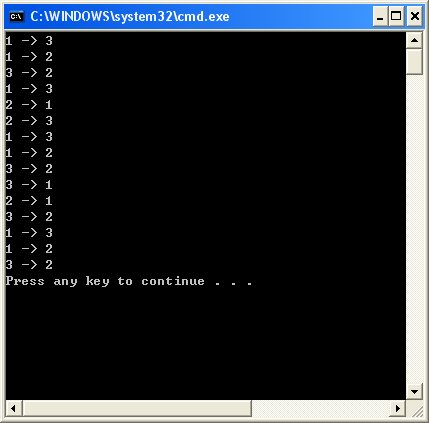
답이 제대로 나온 것 같나요??
다음에는 바이너리서치를 구현하는 방법에 대해서 얘기해보겠습니다.
Verilog HDL, VHDL, SFL 등등. 그 중 Verilog HDL을 많이 사용하고 있다.
장점을 살펴보면 다음과 같다.
(1) C언어를 기초로 한 문법이며, 기술이 간단
(2) 문장과 연산자 등이 C언어와 거의 비슷하기 때문에, 배우기가 쉽다.
(3) 처음 시뮬레이션용 언어로 만들어졌기 때문에, 시뮬레이션 언어능력이 좋다.
(4) 언어체계가 단순하기 때문에 시뮬레이터가 고속이다.
Verilog HDL를 사용하여 간단한 논리회로를 설계해 보면
어떠한 기능을 가지는 하나의 로직을 모듈이라고 정의하고 "module"~"endmodule"안에 있어야 한다. 모든 문장은 세미콜론으로 끝내고, "end~"로 시작하는 예약어에는 세미콜론을 사용하지 않는다.
module 모듈이름 (포트목록);
포트선언;
레지스터 선언;
와이어 선언;
파라미터 선언;
회로기능 표현;
원시적인 연산자 또는
assign문(조합회로표현)
function문(조합회로표현)
always문(순차회로표현)
하위 모듈 호출 등.
endmodule (세미콜론 없음)
모듈이름은 영문자와 언더바("_")로 시작 할 수 있으며 대문자와 소문자를 구별하므로 주의한다.
위의 방법으로 간단한 모듈을 설계하는 2가지 예를 들어보면
1. 게이트 연산자를 이용한 경우
/* H_ADD */
module H_ADD (X, Y, C, S);
input X, Y;
output C,S;
and U1 (C, X, Y);
xor U2 (S, X, Y);
endmodule
2. 연속 할당 문을 이용한 경우
/* H_ADD */
module H_ADD (X, Y, C, S);
input X, Y;
output C,S;
assign C=X&Y;
assign S=X^Y;
endmodule
이전글 [UNIX 보안 기초 -2-] UNIX 파일시스템 초간략
- DoS, DDoS - local DoS, remote DoS (서비스를 불가능하게 하는 공격)
- 시스템 오류 - 환경변수의 취약성, ptrace, race condition, 잘못된 퍼미션
- 프로그램의 오류 - setuid, daemon 의 오류 이용, BOF(Buffer Overflow), FSB(Format String Bug)
- Network의 취약성 - Spoofing, Sniffing
- 기타 - passwd cracking
다음은 간단한 해킹시도의 원리들이다.
1. DoS, DDoS
DoS (Denial of Service) 공격이란 다중작업을 지원하는 운영체제에서 발생할 수 있는 공격 방법. 구체적으로 한 프로세스가 시스템의 리소스를 독점하거나, 모두 사용해 버리거나 또는 파괴하여서 올바른 서비스를 제공하지 못하도록 하는 공격. 공격 장소에 따라 나누면 local DoS, remote DoS 가 있다.
local DoS - 공격자가 시스템에 들어와서 시행하는 방법. 실제 이를 위해서는 간단한 C코드나 쉘 스크립트를 이용하면 된다. 하지만 이러한 공격법의 문제점은 반드시 시스템에 계정이 있어야 한다는 점.
ex) 디스크 채우기, 메모리 고갈, 프로세스 만들기. Explorer 4.0 자기참조프레임
remote DoS - 일반적으로 이들은 특정 포트를 listen하고 있는 프로세스를 마비시키거나 운영체제의 네트워크 기능 자체를 오동작하게 하거나 LAN 자체를 마비시키는 것으로 분류할 수가 있다.
ex) ping attack, ICMP(Internet Control Message Protocol)공격, 메일폭탄 등.
2. 환경변수 이용
다중 사용자를 지원하는 서버용 시스템은 각 사용자에 맞는 환경변수를 지정하여서 지정한 환경 하에서 사용자가 좀더 편리하게 작업을 할 수 있도록 도와주고 있다.
PATH - PATH 환경변수는 실행파일이 위치한 디렉토리들을 값으로 가지고 있다. 프로그램 내부에서 절대 경로를 주지 않고 외부 프로그램을 호출한다면 PATH 변수에 포함된 디렉토리들을 순서대로 찾아가면서 호출한다. 프로그래머가 만약 다음과 같은 코드를 사용한다면
| ... exec("ls -l | grep xxx"); ... |
IFS - IFS (Internal Field Seperator)는 프로그램이 exec()나 popen() 등을 이용하여 외부 프로그램을 실행할 때 입력되는 문자열을 여러 필드로 나눌 때 기준이 되는 문자를 정의하는 변수이다. 기본적으로 IFS는 ' ' (space)로 정의된다.
프로그래머가 코드상에서 exec("/usr/lib/sendmail"); 이라고 코드를 넣었다고 가정하자. 만약 이 프로그램을 IFS를 '/' 로 바꾸고 실행하였다면 어떤 효과가 나타날까? exec(" usr lib sendmail"); 을 수행한것이 되어버린다. 즉, exec 의 실행 명령어는 'usr'이 되며 'lib sendmail'은 'usr' 이란 프로그램에 대한 인자로 쓰이게 된다. 만약 path 내에 SETUID 프로그램이라면 보안상의 문제가 된다.
| hankyung@ubuntu:~$ IFS="/"; export IFS |
set | less 명령어로 확인하여 보자.

IFS 가 "/"로 바뀐 것을 확인할 수 있다.
동적 라이브러리 이용 - 유닉스 시스템에서 사용하는 동적 라이브러리(Dynamic Library)를 이용하기 위한 환경변수를 이용해도 프로그램의 오동작을 유도할 수도 있다. 동적라이브러리를 이용하기 위한 환경변수에는 LD_LIBRARY_PATH와 LD_PRELOAD가 있다.
- LD_LIBRARY_PATH : 동적 라이브러리가 들어있는 디렉토리들을 값으로 갖는다.
- LD_PRELOAD : 먼저 loading 해야 하는 동적 라이브러리가 들어있는 디렉토리를 값으로 갖는다.
이 코드를 동적 라이브러리로 만든다.
fgetc(char *buf, int n, FILE *fp) {
exec("/bin/sh", "-sh", 0);
}
만들어진 동적 라이브러리를 다음과 같이 다른 동적라이브러리보다 먼저 링크되도록 한다.
hankyung@ubuntu:~$ cc -c -pic fget.c
hankyung@ubuntu:~$ ld -o libme.so fget.o
hankyung@ubuntu:~$ setenv LD_PRELOAD .:$LD_PRELOAD
fgetc()를 사용하는 수퍼유저 소유의 SETUID 프로그램을 실행시키면 파일로부터 문자를 받아들이는 원래의 fgetc() 대신에 크래커가 작성한 위의 fgetc()가 실행되어 쉽게 수퍼유저 권한으로 실행된 쉘을 얻을 수 있다.
3. Race Condition(경쟁조건) #1. 임시파일을 생성하는 SETUID가 걸린 프로그램
만약 수퍼유저 소유의 SETUID 프로그램이 임시파일을 만든다면 수퍼유저의 권한으로 파일이 생성될 것이고 이 임시 파일을 프로세스가 접근하기 전에 다른 시스템 파일로 바꿔버린다면 어떤 시스템 파일이든 덮어쓰기가 가능해진다.
root권한의 setuid가 걸린 "good"이라는 프로그램이 있다고 하자.
그런데 이 프로그램은 실행한 후에 /tmp 디렉토리안에 byebye라는 임시파일을 만든다. 이러한 경우, 즉 프로그램이 실행 과정에 임시파일을 생성하는 경우에도 심볼릭링크를 이용하여 해킹을 할 수 있다.
일단 good이라는 프로그램을 실행하면 /tmp/byebye라는 임시파일이 생길 것이다. 일반 사용자가 이 임시파일(/tmp/byebye)을 삭제하고, /etc/passwd의 심볼릭 링크를 만드는데 이름을 /tmp/byebye라고 하여 만들었다.
그럼 이제 다시 good을 실행시키면 어떻게 되겠는가?
good이라는 프로그램엔 root권한의 setuid가 걸려있으므로 실행되는 동안에는 root의 권한이 유지된다. 프로그램이 byebye라는 임시파일을 만드는데 byebye는 /etc/passwd의 심볼릭링크 파일이다. /etc/passwd는 root만이 쓰기가 가능한데, 프로그램 실행 중에는 root권한이기 때문에 결국 /etc/passwd파일에 쓰기가 가능해진다. 따라서 심볼릭링크 파일을 수정하면 원본파일(/etc/passwd)도 수정이 되는 것이다.
이러한 사실을 기초로 하면, 결국 /tmp/byebye의 내용이 /etc/passwd로 들어갈 것이고 /etc/passwd파일은 손상을 입게된다고 예상할 수 있을 것이다.
ex)
-> 문제가 되었던 SunOS의 /bin/mail은 편지를 저장할 때 먼저 그 사용자의 계정을 파일 이름으로 하는 파일의 상태를 검사한다. (lstat()을 이용). 그리고 나서 편지를 저장하기 위해 open()을 수행한다. 즉, 두 시스템 콜 사이에 아무런 변화가 없었다고 가정하고 프로그램이 작성되어 있다. 하지만 lstat()를 사용한 바로 다음에 다른 프로세스가 그 파일을 /.rhosts로 바꿔버리면 편지의 내용은 /.rhosts에 저장하게 된다. 만약 편지의 내용 중에 "+ +"가 들어 있다면 모든 시스템에서 수퍼유저의 권한으로 아무런 제약 없이 로긴할 수 있게 되는 것이다.
| hankyung@ubuntu:~$ cd /var/spool/mail; ln -s ~root/.rhosts daemon hankyung@ubuntu:~$ echo "+ +" | mail daemon hankyung@ubuntu:~$ rlogin localhost -l root |
4. Race Condition(경쟁조건) #2.
만약 위와 같다면 왜 race condition이 등장하게 되었을까? 그냥 링크 시켜서 하면 되는 것인데, 왜 프로세스 간의 resource 경쟁이 나타나는가? 그것은 일종의 방어자와 공격자의 싸움에서 등장한 결과라고도 볼 수 있다.
프로그래머는 이런 문제점을 인식하고 lstat()을 이용한 방법을 택하였다. lstat()을 이용하여 먼저 modify 하고자 하는 파일이 Symbolic Link인지를 먼저 파악, 그 후 그 파일을 open() 시켜서 처리하도록 한 것이다. 아무런 문제가 없는 듯이 보였다. 그러나, 여기에서 진정한 race condition이 등장한다.
lstat()과 open()사이에는 분명히 갭이 존재한다. 그 갭을 적절히 이용한 것이 바로 race condition인데, 먼저 race 프로그램을 background로 돌린다. race 프로그램은 돌면서, 공격하고자 하는 프로그램이 modify하는 파일을 연속해서 지우고, 링크를 만들고 하는 작업을 반복한다. 그런 후에 공격하고자 하는 프로그램을 돌린다. 그러면 어떻게 될까?
race condition example.
fork()라는 함수는 동일한 작업을 하는 프로세스를 하나 더 띄우는 함수이다.
#include <stdio.h>
int main(void)
{
int childpid;
int a, b;
if((childpid = fork()) > 0)
{
/* Parent process */
for(a=0; a<100; a++)
printf("O");
exit(0);
}
else
{
/* Child process */
for(b=0; b<100; b++)
printf("X");
exit(0);
}
}
그냥 생각하기로는 결과가 OXOXOX...이런 식으로 나오리라 생각할 수 있지만, 실행해보면 OOOXXOXOOOOXXOXXXXOXOOX 이런식으로 얽혀서 주기성이 없이 나타난다. 이것이 바로 race condition의 기본 개념.
(글이 길어저 자세한 내용은 나중에 다룰 "race condition 시도" 글에서 다루도록 하겠습니다.)
5. PTRACE
ptrace는 생성된 프로세스가 어떻게 움직이며, 어떤 식으로 데이터를 읽고 쓰는지, 어떤 에러를 내는지 추적을 하기 위해 마련된 시스템 콜이다. 이것은 주로 디버그를 위해 사용되며, 따라서 디버거는 일종의 ptrace 명령어 묶음 유틸리티라고 보면 옳겠다. 프로그래머는 디버거를 통해 ptrace를 손쉽게 사용할 수 있으며, 자신이 만든 프로그램이 어떻게 수행되는지 총괄적으로 관제할 수 있다.
부모프로세스가 invoke된 자식 프로세스를 통제할 수 있다는 사실. 조작의 대상이 되는 것은 그 프로세스가 가진 variables등의 메모리 core와 registers 들이다. ptrace 명령어들은, 이러한 것들을 읽고 쓰고 할 수 있음으로 해서 그 프로세스에 대한 전체적인 control flow도 조작해낼 수 있다는 것이다.
* Reference
- [book] Security PLUS for UNIX
- BIT 교육센터 유닉스 보안 강의자료
- wikipedia.org
- http://www.hackerslab.org 레벨3
이번주 완전 바빴네요. 과제심사에 중간고사에...ㄷㄷㄷㅠ_ㅠ
다음글 부터는 본격적으로 해킹시도에 대해 공부 및 실습과정을 쓰도록 하겠습니다.
예고- BOF (Buffer Over Flow)
아.. 이거 벌금의 압박으로 무조건 쓰게 되네요..-ㅁ-a;;;
ㄷㄷㄷㄷ
무서운 시그장님.. ㄷㄷ
오늘은 VPL로 C언어나 새로운 언어들을 배울때 가장 많이 시작하는 Hello World 를 화면에 표시하는 것을 할 것입니다.
VPL로 간단하게 어떻게 되는지.. 보시죵~
VPL 실행 방법은 다들 아시라 믿습니다만...-ㅁ-;; 설마.. 모르시는분은.. 설마.. -ㅁ-a
저번에도 올렸듯이... 비스타에서는 관리자권한으로 실행하시구요~~
File 메뉴에서 새로만들기 혹은 New를 선택하셔서 새 프로젝트를 만드시구요.
왼쪽 상단에 있는 Basic Activities에 있는 "Data" toolbox를 마우스로 끌어서 오른쪽의 빈 Diagram에 아무데나 원하는 곳에 놓으세요~
그리고 그 activity의 int 옆에 있는 드롭다운 리스트에서 string을 선택하시면 됩니다. 왜 그걸 선택하냐는... 설마..-ㅁ-aa
Hello World가 문자열이라서.. 설마..-ㅁ-aa
data avtivity의 텍스트 상자를 클릭하시면 입력 하실수 있는데 거기에 Hello World! 를 입력하시면 됩니다.
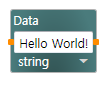
화면에 표시할 다이얼로그 창을 가져와야..-ㅁ-a
왼쪽 아래의 Services 에서 아래로 쭈우우우우욱 내리시면 SimpleDialog 가 있습니다. 혹시 못 찾으시겠으면.. 아니면 내리는게 귀찮다거나 하시면~~ Services의 아래에 Find service ... 에 입력을 해서 검색 하시면 됩니다. 찾으시면~~! 그 것을 오른쪽 Diagram창에 끌어 오세요~
그 위치는 어디에 있어도 상관 없습니다. 그리고 data activity와 SimpleDialog를 연결합니다.
아 어떻게 연결하시는지 모르시겠으면... Data activity의 오른쪽에 보면 주황색 네모가 있습니다. 그 네모를 클릭해서 SimpleDialog의 왼쪽 네모에 붙이시면 자동으로 연결이 됩니다...!! 참.. 쉽죠.. 라고 말해야 하나.-ㅁ-a 설마...
그러면 Connections 라는 Dialog 창이 뜹니다. 거기서~~!
첫번째 항목... 즉, From에서 DaraValue를 선택하시고.. 그거 하나 밖에 없지만...
두번째 항목에서는 AlertDialog를 선택합니다. 왜냐구요??
그냥 뭐 알람 창 같은 모양에 Hello World!를 띄우기 위해서~~
ConfirmDialog도 실행하면 똑같습니다만... -ㅁ-;;; PromptDialog는 뭔가 입력을 받을때 쓰구요~!

그러면 Value 드롭다운하는 리스트에서 value를 선택합니다.
그렇게 함으로써~~ Data Activity에 있는 값이 Alert Form에 띄울 메시지 텍스트로 보내집니다.

실행방법은 Run메뉴에 있는 Start 를 실행하거나 아니면 Help 메뉴 아래에 위치한 화살표 모양을 실행시켜도 되고... 그것마저.. 귀찮으시다면.. F5누르셔도 됩니다..;;;;-ㅁ-;;
프로젝트 저장을 안했을 것인데요.. 안했으면 저장 다이얼로그를 열어줘서 거기서 프로젟트 이름을 원하는대로 하시고 save하시면 됩니다.
그러고 나서 어플리케이션을 실행시키는데...! 그 과정이 끝나면..!
Hello World! 가 쓰여저 있는 simple alert dialog 상자가 뜹니다.
바로 이렇게요!

우후후훗.. 오늘은 여기까지!!!
너무 쉬워서 글쎄 너무 뭐 한것도 없어서.. 에휴...
욕먹지 않으려나.. 에라잇 ..-_-;
예전에 인터넷에서 플래시로 한번 봤었던 내용인데 실습용으로 괜찮을거 같아서 한번 구현해 보았습니다. 하나의 그림을 총 4부분으로 나누어서 출력하고 마우스의 움직임에 따라서 마우스와의 거리에 따라 영역이 따라오는 속도를 조절하는 내용입니다. 마땅히 떠오르는 제목이 없어서.. 다이나믹 마우스 무브 애니메이션이라고 했지만.. 그냥 마우스 따라다니는 그림 정도라 할수도 있겠습니다..
아래는 시연 동영상 입니다.
컴퓨터 화면을 촬영한것이라서 많이 버벅대는 느낌이 있어서 조금 아쉽습니다..
아래는 XAML 소스코드입니다.
- <WINDOW title="Mouse Move Here!! - WPF KOREA!!" xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation" ResizeMode="NoResize" xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml" x:Class="MouseOver.Window1" Width="400" Height="450" Background="White">
- <CANVAS Width="400" Height="400">
- <CANVAS.RESOURCES>
- <STYLE TargetType="Image">
- <Setter Property="Width" Value="400"/>
- <Setter Property="Height" Value="400"/>
- <Setter Property="Source" Value="character.JPG"/>
- </STYLE>
- <STYLE TargetType="Canvas">
- <Setter Property="Background" Value="White"/>
- <Setter Property="Width" Value="400"/>
- <Setter Property="Height" Value="400"/>
- </STYLE>
- </CANVAS.RESOURCES>
- <CANVAS MouseMove="ImageTop_MouseMove">
- <IMG x:Name="ImageTop">
- <CANVAS.CLIP>
- <RECTANGLEGEOMETRY Rect="0,0,400,100" />
- </CANVAS.CLIP>
- </CANVAS>
- <CANVAS MouseMove="ImageTopBottom_MouseMove">
- <IMG x:Name="ImageTopBottom">
- <CANVAS.CLIP>
- <RECTANGLEGEOMETRY Rect="0,100,400,100" />
- </CANVAS.CLIP>
- </CANVAS>
- <CANVAS MouseMove="ImageBottomTop_MouseMove">
- <IMG x:Name="ImageBottomTop">
- <CANVAS.CLIP>
- <RECTANGLEGEOMETRY Rect="0,200,400,100" />
- </CANVAS.CLIP>
- </CANVAS>
- <CANVAS MouseMove="ImageBottom_MouseMove">
- <IMG x:Name="ImageBottom">
- <CANVAS.CLIP>
- <RECTANGLEGEOMETRY Rect="0,300,400,100" />
- </CANVAS.CLIP>
- </CANVAS>
- </CANVAS>
- </WINDOW>
아래는 C# 소스코드입니다.
- public partial class Window1 : Window
- {
- public Window1()
- {
- InitializeComponent();
- Canvas.SetLeft(ImageTop, 0);
- Canvas.SetLeft(ImageTopBottom, 0);
- Canvas.SetLeft(ImageBottomTop, 0);
- Canvas.SetLeft(ImageBottom, 0);
- }
- DoubleAnimation TopMoveAnimation = new DoubleAnimation();
- DoubleAnimation TopBottomMoveAnimation = new DoubleAnimation();
- DoubleAnimation BottomTopMoveAnimation = new DoubleAnimation();
- DoubleAnimation BottomMoveAnimation = new DoubleAnimation();
- private void ImageBottom_MouseMove(object sender, MouseEventArgs e)
- {
- SetAnimationPosition(e.GetPosition(this).X);
- TopMoveAnimation.SpeedRatio = 0.5;
- TopBottomMoveAnimation.SpeedRatio = 1;
- BottomTopMoveAnimation.SpeedRatio = 2;
- BottomMoveAnimation.SpeedRatio = 4;
- BeginAnimation();
- }
- private void ImageBottomTop_MouseMove(object sender, MouseEventArgs e)
- {
- SetAnimationPosition(e.GetPosition(this).X);
- TopMoveAnimation.SpeedRatio = 0.5;
- TopBottomMoveAnimation.SpeedRatio = 2;
- BottomTopMoveAnimation.SpeedRatio = 4;
- BottomMoveAnimation.SpeedRatio = 1;
- BeginAnimation();
- }
- private void ImageTopBottom_MouseMove(object sender, MouseEventArgs e)
- {
- SetAnimationPosition(e.GetPosition(this).X);
- TopMoveAnimation.SpeedRatio = 2;
- TopBottomMoveAnimation.SpeedRatio = 4;
- BottomTopMoveAnimation.SpeedRatio = 1;
- BottomMoveAnimation.SpeedRatio = 0.5;
- BeginAnimation();
- }
- private void ImageTop_MouseMove(object sender, MouseEventArgs e)
- {
- SetAnimationPosition(e.GetPosition(this).X);
- TopMoveAnimation.SpeedRatio = 4;
- TopBottomMoveAnimation.SpeedRatio = 2;
- BottomTopMoveAnimation.SpeedRatio = 1;
- BottomMoveAnimation.SpeedRatio = 0.5;
- BeginAnimation();
- }
- private void SetAnimationPosition(double LeftPosition)
- {
- LeftPosition -= 200;
- TopMoveAnimation.To = LeftPosition;
- TopBottomMoveAnimation.To = LeftPosition;
- BottomTopMoveAnimation.To = LeftPosition;
- BottomMoveAnimation.To = LeftPosition;
- }
- private void BeginAnimation()
- {
- ImageTop.BeginAnimation(Canvas.LeftProperty, TopMoveAnimation, HandoffBehavior.Compose);
- ImageTopBottom.BeginAnimation(Canvas.LeftProperty, TopBottomMoveAnimation, HandoffBehavior.Compose);
- ImageBottomTop.BeginAnimation(Canvas.LeftProperty, BottomTopMoveAnimation, HandoffBehavior.Compose);
- ImageBottom.BeginAnimation(Canvas.LeftProperty, BottomMoveAnimation, HandoffBehavior.Compose);
- }
- }
public partial class Window1 : Window
{
public Window1()
{
InitializeComponent();
Canvas.SetLeft(ImageTop, 0);
Canvas.SetLeft(ImageTopBottom, 0);
Canvas.SetLeft(ImageBottomTop, 0);
Canvas.SetLeft(ImageBottom, 0);
}
DoubleAnimation TopMoveAnimation = new DoubleAnimation();
DoubleAnimation TopBottomMoveAnimation = new DoubleAnimation();
DoubleAnimation BottomTopMoveAnimation = new DoubleAnimation();
DoubleAnimation BottomMoveAnimation = new DoubleAnimation();
private void ImageBottom_MouseMove(object sender, MouseEventArgs e)
{
SetAnimationPosition(e.GetPosition(this).X);
TopMoveAnimation.SpeedRatio = 0.5;
TopBottomMoveAnimation.SpeedRatio = 1;
BottomTopMoveAnimation.SpeedRatio = 2;
BottomMoveAnimation.SpeedRatio = 4;
BeginAnimation();
}
private void ImageBottomTop_MouseMove(object sender, MouseEventArgs e)
{
SetAnimationPosition(e.GetPosition(this).X);
TopMoveAnimation.SpeedRatio = 0.5;
TopBottomMoveAnimation.SpeedRatio = 2;
BottomTopMoveAnimation.SpeedRatio = 4;
BottomMoveAnimation.SpeedRatio = 1;
BeginAnimation();
}
private void ImageTopBottom_MouseMove(object sender, MouseEventArgs e)
{
SetAnimationPosition(e.GetPosition(this).X);
TopMoveAnimation.SpeedRatio = 2;
TopBottomMoveAnimation.SpeedRatio = 4;
BottomTopMoveAnimation.SpeedRatio = 1;
BottomMoveAnimation.SpeedRatio = 0.5;
BeginAnimation();
}
private void ImageTop_MouseMove(object sender, MouseEventArgs e)
{
SetAnimationPosition(e.GetPosition(this).X);
TopMoveAnimation.SpeedRatio = 4;
TopBottomMoveAnimation.SpeedRatio = 2;
BottomTopMoveAnimation.SpeedRatio = 1;
BottomMoveAnimation.SpeedRatio = 0.5;
BeginAnimation();
}
private void SetAnimationPosition(double LeftPosition)
{
LeftPosition -= 200;
TopMoveAnimation.To = LeftPosition;
TopBottomMoveAnimation.To = LeftPosition;
BottomTopMoveAnimation.To = LeftPosition;
BottomMoveAnimation.To = LeftPosition;
}
private void BeginAnimation()
{
ImageTop.BeginAnimation(Canvas.LeftProperty, TopMoveAnimation, HandoffBehavior.Compose);
ImageTopBottom.BeginAnimation(Canvas.LeftProperty, TopBottomMoveAnimation, HandoffBehavior.Compose);
ImageBottomTop.BeginAnimation(Canvas.LeftProperty, BottomTopMoveAnimation, HandoffBehavior.Compose);
ImageBottom.BeginAnimation(Canvas.LeftProperty, BottomMoveAnimation, HandoffBehavior.Compose);
}
}간단하게 설명을 하자면, Canvas위에 Image를 영역별로 Clip해서 출력한 뒤 Canvas의 마우스 이벤트에 따라서 Animation을 적용한 것입니다. 수동으로 SpeedRatio를 수정해서 반응속도를 조절했습니다. 보다 자연스러운 Animation을 위해서 BeginAnimation을 호출할 때 HandoffBehavior를 주어서 약간의 관성을 주었습니다. 기타 궁금하신 사항은 리플이나 메일로 주시면 답변 해드리도록 하겠습니다.

저번시간에 window를 만들어 보았습니다. 아주 간단하게 몇줄 끄적였더니 하나의 귀엽고 앙증맞은 window가 생성되었죠?
오늘은 소스 코드에 대하여 설명하도록 하겠습니다. 처음 전 몇줄 없다고 대충 훌터 보았었지만, 그렇게 되면 결국 다시한번 보게 되더라구요 ^ ^ GTK+의 소스 하나하나 설명을 해보겠습니다.
#include <gtk/gtk.h>
이것은 gtk를 사용하기 위해 꼭 필요한 헤더입니다. /usr/include/gtk/
실제 gtk의 함수들은 여러 헤더 파일에 함수를 선언하고 있지만 위의 헤더파일만 선언해 주면 되지만, 가끔은 위의 헤더에 내장되어있지 않은 함수가 있기도 합니다. (그럴 경우에는 따로 프로젝트를 진행하면서 설명하도록 하겠습니다.) 그렇지만, 위의 헤더함수가 다른 하위 헤더파일을 거의 포함하고 있습니다.
gtkwidget *window;
이것은 gtk프로그래밍 할 때 꼭 선언되는 변수입니다. c나 c++ 등 프로그래밍을 할때 변수를 선언해 주듯이 선언해 주면 됩니다. gtkwidget은 문자 그대로 gtk widget의 한종류라는 것을 나타내줍니다. 우리는 window를 생설할 것이기 때문에 저는 window 로 선언하겠습니다. gtkwidget 은 여러 가지가 있지만, gtk로 짜여진 프로그램의 대부분 인터페이스는 저 자료형 하나로 선언가능한 것이 많습니다. 버튼 메뉴, 아이콘, 상태바, 레이블 등 모든 것이 저 자료형(gtkwidget)으로 선언하면 됩니다.
gtk_init (&argc, &argv);
이것은 프로그램 실행 파일에 인수로 넘겨받는 것을 처리 하는 부분이며, 기본으로만 실행하기 위해서 내부 함수를 쓰는 부분이다. c에서 사용하시는 함수의 개념을 생각하시면 이해를 하시기에 조금의 도움이 됩니다.
window = gtk_window_new (gtk_window_toplevel);
위에서 변수를 선언 했으니 이제 사용을 해보겠습니다. 모든 것이 저 하나로 선언가능하다면 어느 부분에 사용할 것인가를 정해야 할 것이다.위의 선언문을 하나씩 풀어보겠습니다.
window라는 변수는 단순히 변수에 window라는 형태를 갖는 역학을 하는 부분입니다. 윈도우는 말그대로 창을 의미합니다. (MFC에서의 Dialog와는 다른 개념입니다.) gtkwidget의 가장 기본이 되고 바탕이 되는 부분입니다. 가장 기본적이고 심플한 window를 생성할 것이 기때문에 우리는 gtk_window_toplevel 이라는 window의 특징을 선언해 준것입니다.
즉, 다시 말해서 window라는 변수안에 gtkwidget중 가장 기본적인 toplevel(가장 기본적인 window)을 정의해준 것입니다.
앞으로 여러 가지 widget을 만들어 보겠지만, 대부분 gtk_*_new 형태의 함수로 위젯을 정의 하게 될 것이다. '*'은 button, menu, label, box, frame 등이 됩니다.
gtk_widget_show (window);
위의 선언문을 해석하면 widget을 show하라는 뜻이며, 이로써 화면에 보이게 됩니다. gtk_widget_show 뒤의 인수 부분에서 화면에 보여질 위젯을 결정합니다. 우리는 window를 하나 만들었고 window만 보여줄 것이라 window만 show하게 되는거겠죠? 여러가지 widget을 생성한다면 widget을 각각 보여줘야겠죠? ^ ^;
gtk_main();
이부분도 마찬가지로 gtk프로그래밍에서 빠지지 않는 부분입니다. 인수도 없으며 단순히 저렇게 적어주면 됩니다. 물론 main 함수의 끝부분쯤에서 써줘야겠죠. 조금 중요한 부분이니 이부분은 나중에 따로 다루어 보도록 하겠습니다. (약간 미루는듯한-_-+)
여기까지가 저번시간에 작성한 코드였습니다. 흠.. 아주 귀엽고 앙증맞지만, 생각외로 close버튼도 있고 전 매우 놀랐습니다. 달랑 윈도우만 만들어 지는줄 알았는데 close 버튼이 있는게 어디입니까~ 다들 그냥 넘기시겠지만, 전!! 매우 좋았습니다. 분명 찾아보면 최소화, 최대화 버튼도 달린 윈도우를 만들수 있을거라는 생각이 들기 때문입니다.
위에 살짝쿵 설명했듯이, GTK+에서는 window와 dialog는 다른 방식입니다. gtk_window_new()를 위한 또다른 define으로 GTK_WIDNOW_TOPLEVEL말고 GTK_WINDOW_DIALOG 도 있습니다. 이것은 윈도매니저와 약간 다른 방식으로 상호작용하며, 일시적인 윈도 들에 대해 쓰여지고 있습니다. 예를 들어 기본 윈도우에 팝업 정도의 개념이라고 생각하시면 됩니다.
그럼 위의 코드를 응용하여 dialog를 만들어 낼 수 있겠죠? 다들 한번 응용해 보세요~
이제부터 위의 코드에 widget을 하나씩 추가하여 기능성 있는 window를 만들어 볼까 합니다.
오늘은 사정상 새로운 내용을 첨가 하지 못하였습니다. 다음주부터는 분발하겠습니다 ^ ^ 넓으신 마음으로 봐주세요 ~
그럼 이번주도 매일매일 올라오는 즐겁고 흥미로운 블로그를 보면서 열공하겠습니다..ㅋㅋ

