
Machine Learning에 해당되는 글 3건
2008.11.29 :: Perceptron 3
2008.10.31 :: Linear Regression
2008.10.21 :: Machine Learning Introduction 1
2008. 11. 29. 23:57 :: Machine Learning
Perceptron은 1957년 Cornell Aeronautical Laboratory에서 Frank Rosenblatt에 의해서 개발된 Artificial Neural Network의 한 종류이다.
그리고 Perceptron은 가장 간단한 feedforward netral network라고 할 수 있고, 이것을 이용해 linear classifier를 만들 수 있다.
Definition
Perceptron은 matrix eigenvalue를 이용해서 feedforward netral network를 만들고 input value x를 output value f(x)로 mapping시키는 classifier이다. f(x)는 다음과 같이 정의할 수 있다.
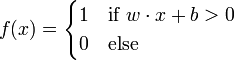
w는 실수 값을 갖는 vector이고 wx는 dot product를 이용해 값을 구할 수 있다. 그리고 b값은 bias term으로서 input vector들이 어느 방향으로 값들이 치우져 있는지 알려주는 값이다.
Learning
x(j)는 input vector의 j-th term
w(j)는 weight vector의 j-th term
y는 neuron으로부터의 output
δ는 expected output
α는 learning rate
weight의 update rule
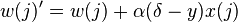
위의 방법으로 wegith vector를 update해서 특정값 이하의 error가 발생하지 않을 때 까지 반복해
linear하네 classify할 수 있는 classifier를 찾는다.
2008. 10. 31. 16:48 :: Machine Learning
Logistic Regression은 training set으로부터 주어진 vector data를 이용하여 data들의 방향을 찾고 실제 제공하지 않은
data들을 예측할 수 있는 algorithm이다. 이 algorithm을 구현하는 방법은 다음과 같은 방법이 있다.
1. LMS(Least Mean Square) algorithm
2. The normal equations
예를들어 주식 시장을 예측할 수 있는 algorithm을 구현하려고 하면, 주식 가격을 결정할 수 있는 factor는 여러가지가
있다. 그 factor중에서 기업 영업 실적(x1), 업종의 경기(x2), 우리나라의 경기(x3) 만을 놓고 주식 시장을 예측한다고 하자.
그럼 이 3개의 요인은 다음과 같은 수식으로 표현할 수 있다.

이 수식에서 training set x1, x2, x3가 주어지고 θ0, θ1, θ2, θ3값을 찾는다면 새로운 data값 x1, x2, x3에 대해 h(x)를 찾을
수 있다. 결국 이 값을 이용해 h(x)를 구할 수 있게 되고, 우리가 값을 예측할 수 있게 되는 것이다. (물론 더 많은 factor들과
다른 다양한 이론들이 필요하겠지만...)
결국 여기에 맞는 θ0, θ1, θ2, θ3를 찾는 것이 regression의 목표이다.
위 수식은 간단히 다음과 같이 표현할 수 있다.

 "equation preview")
 "equation preview") 이 값은 위의 cost function을 differentiation한 값이다. 이 값을 이용해서
이 값은 위의 cost function을 differentiation한 값이다. 이 값을 이용해서  를 update시켜 값을 구한다.
를 update시켜 값을 구한다.
이 값은 다음과 같다.
%20%3D%20%5Cfrac%7B%5Cdelta%7D%7B%5Cdelta%5Ctheta_j%7D%5Cfrac%7B1%7D%7B2%7D(h_%5Ctheta(x)%20-%20y)%5E2%20%0D%0A%3D%20(h_%5Ctheta(x)%20-%20y)x_j "equation preview")
이 값의 유도는 생략한다. 이 값을 위의 update rule에 적용하면 다음과 같다.
%20)x%5Ei_j "equation preview")
 ( 그림 2 - test 2 )
( 그림 2 - test 2 )
data를 random하게 생성하였지만 구한 line은 동일하다는 것을 알 수 있다.
나머지 The normal equations 방법은 직접 찾아보길....
다음은 classifier의 고전인 perceptron에 대해서 알아보자.
data들을 예측할 수 있는 algorithm이다. 이 algorithm을 구현하는 방법은 다음과 같은 방법이 있다.
1. LMS(Least Mean Square) algorithm
2. The normal equations
예를들어 주식 시장을 예측할 수 있는 algorithm을 구현하려고 하면, 주식 가격을 결정할 수 있는 factor는 여러가지가
있다. 그 factor중에서 기업 영업 실적(x1), 업종의 경기(x2), 우리나라의 경기(x3) 만을 놓고 주식 시장을 예측한다고 하자.
그럼 이 3개의 요인은 다음과 같은 수식으로 표현할 수 있다.
이 수식에서 training set x1, x2, x3가 주어지고 θ0, θ1, θ2, θ3값을 찾는다면 새로운 data값 x1, x2, x3에 대해 h(x)를 찾을
수 있다. 결국 이 값을 이용해 h(x)를 구할 수 있게 되고, 우리가 값을 예측할 수 있게 되는 것이다. (물론 더 많은 factor들과
다른 다양한 이론들이 필요하겠지만...)
결국 여기에 맞는 θ0, θ1, θ2, θ3를 찾는 것이 regression의 목표이다.
위 수식은 간단히 다음과 같이 표현할 수 있다.
( theta, x는 vector, T 는 transpose )
위 식의 vector θ를 찾기 위한 cost function은 다음과 같이 정의한다.

cost function을 가지고 우리가 원하는 값 θ를 찾기 위해서는 J(θ)값을 minimize시키면 된다.
이 알고리즘을 구현하는 방법 3가지중 LMS algorithm에 대해 소개한다.
LMS(Least Mean Square) algorithm
이 방법은 θ를 초기에 예상하는 값으로 설정한 후 이 값이 cost function의 minize값에 따라서 어떻게 변하는지 구하면 된다.
이 θ값을 update하기 위한 rule은 다음과 같다.
cost function을 가지고 우리가 원하는 값 θ를 찾기 위해서는 J(θ)값을 minimize시키면 된다.
이 알고리즘을 구현하는 방법 3가지중 LMS algorithm에 대해 소개한다.
LMS(Least Mean Square) algorithm
이 방법은 θ를 초기에 예상하는 값으로 설정한 후 이 값이 cost function의 minize값에 따라서 어떻게 변하는지 구하면 된다.
이 θ값을 update하기 위한 rule은 다음과 같다.
이 값의 유도는 생략한다. 이 값을 위의 update rule에 적용하면 다음과 같다.
이 방법을 LMS update rule이라 한다.
이 update rule을 이용해 값을 찾을 수 있다.
값을 찾을 수 있다.
matlab을 이용해 test해 보았다. random하게 200개의 sample을 만들었다. 우선 원래 선은 y=x이고 x는 0부터 20까지 200개의
random data에 gaussian distribution을 이용하여 noise를 추가하였다. gaussian distribution의 mean = 0, variance = 20을
이용하였다.
이를 이용해 regression한 결과는 다음과 같다.

이 update rule을 이용해
matlab을 이용해 test해 보았다. random하게 200개의 sample을 만들었다. 우선 원래 선은 y=x이고 x는 0부터 20까지 200개의
random data에 gaussian distribution을 이용하여 noise를 추가하였다. gaussian distribution의 mean = 0, variance = 20을
이용하였다.
이를 이용해 regression한 결과는 다음과 같다.
( 그림 1 - test 1 )
data를 random하게 생성하였지만 구한 line은 동일하다는 것을 알 수 있다.
나머지 The normal equations 방법은 직접 찾아보길....
다음은 classifier의 고전인 perceptron에 대해서 알아보자.
2008. 10. 21. 23:36 :: Machine Learning
Machine Learning Introduction
Machine Learning
우리나라말로 기계학습을 의미한다.
Machine Learning의 분류는 supervised learning과 unsupervised learning이 있다.
즉, training data를 가지고 learning algorithm을 적용할 수 있는 supervised learning과 training data의 존재 없이 learning을 하게 되면 unsupervised learning이 있다.
supervised learning의 예.
search by humming - 사람의 humming 만으로도 음악 검색. http://www.midomi.com/
unsupervised learning의 예.
BSS(blind source separation) - 두개의 섞인 음을 분리. http://cnl.salk.edu/~tewon/Blind/blind_audio.html
이상 machine learning에 대한 소개를 마친다.
다음 블로깅에는 supervised learning algorithm중의 하나인 linear regression에 대한 소개를 하겠다.~

