
앞서서 이야기한 CLR(Common Language Runtime:공용언어런타임)과 .NET Framework Class Library 이 두가지가 프레임워크의 크게 2가지로 나뉘어진 부분이라 언급했는데 좀 더 자세한 설명을 추가하고 이야기를 하고자 합니다.
CLR
CLR은 코드 관리환경이며 여기서 실행되는 코드를 관리코드(Managed Code)라고 하였는데 이들은 CIL(Common Intermediate Language)라고 하는 중간언어로 구성되어있다. 일반적인 언어는 그 언어의 컴파일러를 통해 각 플랫폼에서 실행가능한 코드(Native Code)로 전환되는데, .NET Framework의 경우는 Managed Code에서 CIL로 변환되고 최종적으로 플랫폼에서 실행가능한 코드(Native Code)로 전환된다.
이러한 부분을 보았을 때 기존의 언어들로 이루어진 코드와 컴파일러를 통해 만들어진 프로그램에 비해 하나의 과정이 추가되어 있기 때문에 시간이 더 걸릴 것이라는 의구심을 가질 수 있다. (물론 사용해보면 알지만 역시 느리긴하다 -_-;) 때문에 MS의 개발자들은 JIT컴파일러의 최적화에 많은 시간을 할애 하였기에 최종 실행시간은 기존의 방법과 거의 동일하다는 결론을 내릴 수 있도록 되었다. (일반적인 인터프리터 코드처럼 느리지 않다)
.NET Code의 커다란 장점은 관리 코드를 만든다는 것이다.
몇가지 관리 코드의 잘 알려진 장점을 살펴본다면
Memory Leak(메모리 누수)가 발생될 수 있는 부분의 원천봉쇄 (예: 포인터 사용금지)
관리 스택, 관리 힙의 사용(불필요한 메모리 공간 사용이 없음)
보안에 대한 부분의 고려
메모리 공간의 자동적 관리기능(Garbage Collector)
등등등~
이런 것들이 주욱 있다 이는 개략적으로만 알아두고 후에 코드를 통한 구현을 하면서 느끼는 것이 낫다고 생각하여 여기까지만 적어둔다.
잠시 이야기가 샜지만; CLR과 관련된 개념은 개략적으로 여기까지이다. 앞에서 말했던 나머지 하나인 .NET Framework Class Library에 대해서 알아보자
.NET Framework Class Library
.NET Framework Class Library는 앞에서 이야기 한 부분을 다시보면
네 가지 요소로 구성되어 있습니다.
FCL에 들어있는 몇가지 네임스페이스를 훑어보고 이번 포스팅을 마무리 하도록 하겠습니다.
| 네임스페이스 | 내용 |
| System | 핵심 데이터 타입과 보조 클래스가 존재 |
| System.Collection | Hash테이블, 크기조절이 가능한 배열, 그 외의 데이터 저장소 |
| System.Data 이하 | ADO.NET을 이용한 데이터 접근 클래스들 |
| System.Drawing | 그래픽 처리를 위한 클래스들(GDI+) |
| System.IO | File과 stream I/O 처리를 위한 클래스들 |
| System.Net | HTTP등의 네트워크 프로토콜을 캡슐화한 클래스들 |
| System.Reflection 이하 | 메타데이터를 조작하기 위한 클래스들 |
| System.Runtime.Remoting 이하 | 분산 프로그램을 지원하는 클래스들 |
| System.ServiceProcess | Windows 서비스를 지원하는 클래스들 |
| System.Threading | 관리 스레드를 생성하는 클래스들 |
| System.Web | HTTP를 지원하는 클래스들 |
| System.Web.Services | 웹 서비스를 지원하는 클래스들 |
| System.Web.Services.Protocols | 웹 서비스 클라이언트를 지원하는 클래스들 |
| System.Web.UI | ASP.NET의 핵심 클래스들 |
| System.Web.UI.WebControls | ASP.NET 서버 컨트롤 클래스들 |
| System.Windows.Forms | GUI프로그래밍을 위한 클래스들 |
| System.Xml 이하 | XML을 조작하기 위한 클래스들 |
코드가 안나오니까 지루하네요 다음 주 부턴 코드가 슬슬 나오는 포스팅을 시작하도록 하겠습니다~
Reference Book : Programming Microsoft .NET 정보문화사
p . s >
아..그리고 하나 시작할 때 목적을 빼먹었는데...
이 포스팅을 보면 다른 책 안보고 이해와 코드를 짤 수 있도록 하는 것이 목적입니다. (
HW만 전문적으로 하시는 분이나 이런 부분은 프로그래머가 아니면 모르는 부분이다 알려달라 하시는 분이 있으면 이미 했던 포스팅이라도 수정 추가를 하려고 했던 부분이라 이런 부분을 더 알고 싶다 등의 리플을 달아주시면 피드백이 되서 감사할 것 같습니다~
오라클의 특징
- 클라이언트 / 서버 환경 (분산 처리)
- 오라클은 현재 사용하는 컴퓨터 시스템이나 네트워크를 최대한 활용할 수 있도록 데이터베이스 서버와 클라이언트 응용
프로그램에 처리를 분산시킵니다. 즉, 데이터베이스 관리 시스템을 실행하는 컴퓨터는 데이터베이스 서버 역할을 담당하고 데이터베이스
응용 프로그램을 실행하는 워크스테이션은 데이터 해석과 표시를 담당합니다.
- 대규모 데이터베이스와 영역 관리
- 오라클은 테라바이트 크기의 데이터를 저장할 수 있는 대규모 데이터베이스를 지원합니다. 고가의 하드웨어 장치를 효율적으로 활용할 수 있도록 영역 사용을 완벽하게 제어합니다.
- 다중 동시 데이터베이스 사용자
- 오라클은 여러 사용자가 동일한 데이터에서 작동하는 다양한 데이터베이스 응용 프로그램을 실행하도록 지원하여 데이터 경합을 최소화하고 데이터 동시성을 보장합니다.
- 데이터 경합 : 데이터 경합은 데이터 경쟁 즉, row level locking을 의미합니다. row level locking이란 어떤 사용자가 실행하고 있는 DML문에 의해 변경이 진행 중인 행에 발생하는 것으로 Row-level lock는 변경이 진행중인 행이 완료될 때까지 보호됩니다. 즉, 한 사용자가 데이터를 변경하고자 하여 그 데이터에 접근해서 변경을 시도를 하게 되면 그 데이터는 lock에 걸리게 됩니다. 그 때, rollback segment라는 객체에 Before image와 after image에 데이터를 기록하고 commit하면 둘 다 프리상태로 만들게 욉니다. commit 전이라면 타 사용자는 before image 영역에 접근하여 사용하고 commit 후라면 after image 영역으로 접근이 되는 것입니다.
- 데이터 동시성 : 다수의 사용자가
동시에 데이터에 접근할 수 있어야한다는 의미입니다. 그렇다면 여기서 데이터의 일관성이 문제가 되겠죠? 데이터의 일관성이란,
각각의 사용자가 자신의 트랜잭션이나 다른 사람의 트랜잭션에 의해 변경된 내용을 포함하여 일관된 값을 본다라는 의미입니다. 만약
다수의 사용자가 데이터베이스에 동시에 접근하게 될 경우, 각각의 사용자가 다른 데이터에 접근을 한다면 문제가 없겠지만, 같은
데이터에 접근을 한다면 잘못된 데이터의 변경을 막기 위해선 반드시 어떤 제어를 해주어야 합니다. 그것을 병행 제어
(Concurrency control)이라 합니다. 병행제어 알고리즘에 대해서는 다음에 자세히 설명하도록 하겠습니다.
- 접속성
- 오라클 소프트웨어는 서로 다른 유형의 컴퓨터와 운영체제가 네트워크를 통해 정보를 공유하도록 합니다.
- 고성능 트랜잭션 처리
- 오라클은 전체 시스템의 성능을 높게 유지하면서 고 성능 트랜잭션 처리를 제공하므로 데이터베이스 사용자들은 느린 처리 속도로 고생하지 않아도 됩니다.
- 트랜잭션 : 논리적 작업 단위로 결합되는 작업 그룹으로 트랜잭션은 시스템에서 발생할 수 있는 오류에 관계없이 트랜잭션의 각 동작에 대해 일관성과 무결성을 제어하고 유지관리하는데 사용됩니다.
- 로컬 트랜잭션 : 단위 시스템에서 처리되는 트랜잭션으로 트랜잭션에 대한 관리를 DBMS에서 담당한다.
- 분산 트랜잭션: 여러 개의 시스템에서 처리되는 트랜잭션이다. 여러 DBMS에 걸친 트랜잭션을 담당하는 경우도 많아서 주로 미들웨어에서 트랜잭션 관리를 담당한다.
- 고 가용성
- 일부 사이트에서는 데이타베이스 처리 능력을 떨어뜨리는 장애 시간없이 하루 24시간 오라클을 작동시킵니다. 데이터베이스 백업같은 정상적인 시스템 기능이나 부분적인 컴퓨터 시스템 장애는 데이터베이스 사용에 영향을 주지 않습니다.
- 가용성 제어
- Oracle만이 가지고 있는 특징으로 데이터베이스 레벨과 하위 데이터베이스 레벨에서 데이터 가용성을 선택적으로 제어할 수 있습니다. 가용성 제어는 RAC(Real Application Clusters)와 관련있는 특징입니다. 잠시 RAC에 대해 알아보도록 하겠습니다.
RAC의 정의
- Oracle Real Application Clusters는 동일 데이터베이스를 여러 인스턴스에서 동시에 액세스할 수 있다.
- 시스템 확장이 가능하기 때문에 결함 허용, 로드 밸런싱 및 향상된 성능을 제공한다.
- 모든 노드가 동일한 데이터베이스를 엑세스하기 때문에 한 인스턴스에서 장애가 발생해도 데이터베이스에 대한 엑세스가 손실되지 않는다.
- 오라클 RAC의 핵심은 공유 디스크 하위 시스템이다.
RAC의 장점
- 확장성 (자원(CPU/메모리/디스크 등)이 부족했을 경우에 대처할 수 있는 구조)
- 새로운 업무가 지속적으로 추가되어 서버의 용량이 부족해지는 경우가 발생된다면 클러스터 상에 새로운 서버를 유연하게 확장할 수 있고, 서버를 확장하더라도 문제가 발생하지 않는다.
- 고가용성 (장애가 발생해도 시스템 전체가 운용될 수 있는 구조)
- 하나의 서버로 구성된 데이터베이스일 경우 데이터베이스 장애가 발생할 경우 복구될때까지 서비스 이용이 불가능했으나,
RAC의 경우에는 하나의 서버에 장애가 발생하더라도, 나머지 서버에서 지속적인 서비스를 제공할 수 있어 서비스의 중지가 발생하지
않는다.
RAC 구조
- 물리적인 하나의 데이터베이스를 여러 대의 서버가 공유하여 사용하는 것
- 모든 서버들은 같은 데이터를 사용하게 되어 논리적으로는 하나의 시스템을 이용하는 것
- Cache Fusion 기능을 위해 노드간 high-speed interconnect network는 필수

- 개방성과 산업표준
- 오라클은 데이터액세스 언어, 운영체제, 사용자 인터페이스 및 네트워크 통신 프로토콜 등에 대한 산업 표준을 준수하여 고객의 투자를 보호하는 열린 시스템이 되도록 합니다. 또한 오라클은 시스템 관리를 위해 SNMP (Simple Network Management Protocol) 표준을 지원하여 관리자가 단일관리 인터페이스로 여러 다른 기종의 시스템을 관리할 수 있도록 합니다.
- SNMP : 서로 통신할 수 있는 채널로 시스템의 상태를 알 수 있게 해주는 프로토콜
- 보안관리
- 인증되지 않은 데이터베이스 액세스와 사용을 방지하기 위해 오라클은 비상 안전 보안 기능을 사용하여 데이터 액세스를
제한하고 모니터합니다. 이 기능으로 가장 복잡한 데이터 액세스 설계까지도 쉽게 관리할 수 있습니다. 오라클에서는 스키마, 업무,
테이블 단위로 privillege가 주어집니다.
- 데이터베이스 무결성 강제 수행
- 허용할 수 있는 데이터의 기준이 되는 업무규칙인 데이터 무결성을 강제로 수행합니다. 이것은 많은 데이터베이스 응용 프로그램에서 데이터 확인을 위한 코딩과 관리에 드는 비용을 줄일 수 있습니다.
- 데이터 무결성 : 데이터의 입력이나 변경 등을 제한하여 데이터의 안전성을 저해하는 요소를 막는 것을 의미한다.
- 이식성
- 오라클 소프트웨어는 다른 운영 체제에서도 작동합니다. 오라클로 개발된 응용 프로그램이라도 거의 수정하지 않고 다른 운영 체제에서 사용할 수 있습니다.
- 호환성
- 오라클 소프트웨어는 대부분의 산업 표준 운영 체제를 포함하여 산업 표준 시스템과 호환할 수 있습니다. 오라클로 개발된 응용 프로그램은 모든 시스템에서 거의 수정하지 않고도 효과적으로 사용할 수 있습니다.
- 분산 시스템
- 분산 네트워크 환경에서 오라클은 물리적으로 서로 다른 컴퓨터에 있는 데이터를 네트워크 상의 모든 사용자가 액세스할 수 있는 하나의 논리적 데이터베이스로 결합합니다. 분산 시스템은 비 분산 시스템과 동일하게 사용자 투명성과 데이터 일관성을 유지하면서 로컬 데이터베이스 관리의 장점을 지닙니다. 또한 오라클은 사용자가 오라클이 아닌 데이터베이스의 데이터를 투명하게 액세스할 수 있도록 다른 기종에 대한 옵션을 제공합니다.
오라클 아키텍처

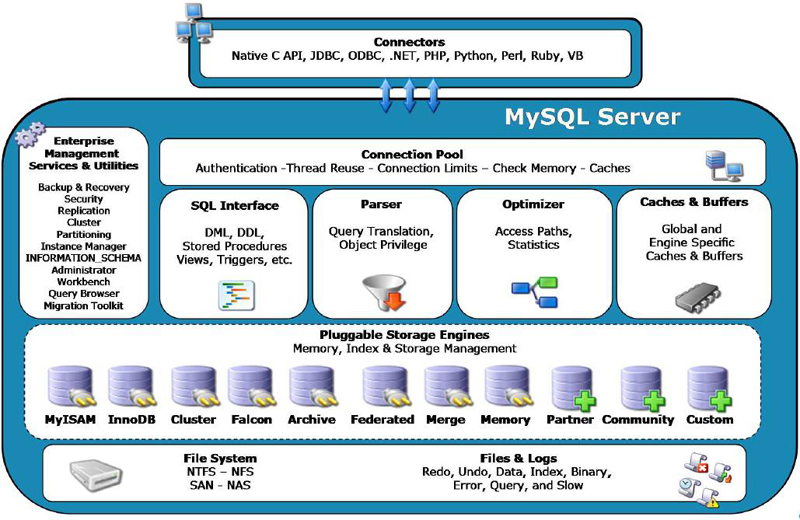
MySQL은 오픈 소스 데이터베이스로 매일 50,000여건의 다운로드가 이루어지고 있는 최고의 다운로드 수를 기록하고 있는
데이터베이스입니다. 세계에서 가장 많이 인스톨되고 가장 대중적인 데이터베이스라 할 수 있다.Heavy transaction
processing, Terabyte-sized data warehouse, high-traffic web site 등에서
최고의 데이터베이스 기술이 입증되었다.또한 MySQL의 아키텍쳐 상 가볍고 핸들링이 쉬워 Web 2.0 사용환경에 가장 적합한
데이터베이스로 볼 수 있다.
MySQL의 특징
- Internals and portability:
- 커널 쓰레드를 이용한 멀티 쓰레드 지원.
Fully multi-threaded using kernel threads. It can easily use multiple CPUs if they are available
- transational과 non-transactional 저장 엔진을 제공한다.
Provides transactional and non-transactional storage engines. - Uses very fast B-tree disk tables(MYISAM) with index compression
MYISAM 엔진은 매우 빠른 B-tree 테이블을 사용한다. - 상대적으로 다른 저장 엔진을 추가하는 것이 쉽다. 만약 SQL 인터페이스를 내부 데이터베이스에 추가하려할 때 유용하다.
Relatively easy to add other storage engines. This is useful if you want to add an SQL Interface to an in-house database. - 쓰레드 기반의 빠른 메모리 할당 시스템
A very fast thread-based memory allocation system. - one-sweep multi join을 이용하기 때문에 join시 매우 빠르다.
Very fast joins using an optimized one-sweep multi-join (Oracle도 사용하고 있음)
- In-memory hash tables, which are used as temporary tables.
임시 테이블을 사용하는 내부 해쉬 테이블
- Scalability and limits (확장성과 제한성)
- 크기가 큰 데이터베이스를 다룰 수 있다.
Handles large databases. We use mysql server with databases that contain 50 million records. We also know of users who use mysql server with 60,000 tables and about 5,000,000,000 rows.
MySQL 아키텍처
안녕하세요.
이번에는 지난 포스팅에 이어 알고리즘의 차수에 대해서 알아보겠습니다.
지난글의 마지막에 이번시간부터는 본격적으로 코딩기법에 대해서 포스팅하겠다고 했는데 생각을 해보니 일단 차수에 대해서는 언급을 하고 넘어가야 할 것 같아서 순서를 바꿨습니다 ^^
알고리즘의 분석
알고리즘이 문제를 얼마나 효과적으로 해결하는지를 결정하기 위하여 알고리즘을 분석할 필요가 있습니다. '알고리즘 코딩기법 1 - Introduction' 에서 소개했던 순차검색과 이분검색의 비교가 바로 알고리즘의 분석이라고 할 수 있고 분석결과 n이 커질수록 이분검색이 유리하다고 결론을 내렸었는데요, 이번 파트에서는 알고리즘의 분석에 대해서 좀 더 자세히 알아보겠습니다.
복잡도 분석(complexity analysis)
시간을 기준으로 알고리즘의 효율을 분석할 때 보통은 CPU에서의 실제 작동시간으로 분석을 하지는 않습니다. 왜냐하면 사용하는 컴퓨터의 성능에 따라 결과가 다르게 나타나기 때문입니다. 그 외에 알고리즘을 구현하는데 사용한 언어나 컴파일러, OS에 따라서도 시간이 다르게 측정될 수 있습니다. 따라서 알고리즘의 효율성을 분석하기 위해서는 위에서 언급한 것들과는 독립된 다른 기준이 필요합니다.
알고리즘의 시간복잡도를 분석할 땐 '1-Introduction' 에서 그랬듯이 입력크기 n에 대해서 알고리즘의 단위연산이 수행되는 횟수를 비교하여 분석하는 기법을 가장 많이 사용합니다. 일반적으로 알고리즘의 실행시간은 입력의 크기에 따라 증가하고, 총 실행시간은 단위연산이 몇 번 수행 되는가에 비례합니다. 따라서 단위연산이 수행되는 횟수를 입력의 크기에 대한 함수로 나타내어 알고리즘의 효율성을 분석할 수 있습니다.
입력크기(input size)
말 그대로 알고리즘으로의 입력의 크기를 의미합니다. 대부분의 알고리즘에서 입력을 크기를 구하기는 매우 쉽습니다. 예를 들어 n개의 아이템을 정렬하는 알고리즘에서 입력크기는 아이템의 갯수인 n이 됩니다. n번째 피보나치항을 구해야 하는 알고리즘의 시간복잡도는 n에 비례할 것입니다. (하지만 엄밀히 따지면 입력크기가 n이라고 말할 수는 없습니다)
단위연산(basic operation)
어떤 명령문이나 일련의 명령문의 집합을 선정하여, 알고리즘이 수행한 총 작업의 양을 이 명령문이나 명령문의 집합을 수행한 횟수에 대략적으로 비례하게 되었을 때, 이 것을 단위연산이라고 합니다. 예를 들어 버블소트 알고리즘에선 두 아이템을 비교를 하고 아이템을 위치를 바꾸는 작업을 하나의 단위연산으로 볼 수 있습니다.
시간복잡도 분석(time complexity analysis)
알고리즘의 시간복잡도 분석은 입력크기의 값에 대해서 단위연산을 몇 번 수행하는지를 구하는 것입니다.
차수
동일한 일을 하는 두 개의 알고리즘이 있습니다. 하나는 시간복잡도가 100n이고 나머지 하나는 0.01n^2 일 때, 어떤 알고리즘이 더 효율적일까요..
사실 두 알고리즘 중 어떤 알고리즘을 선택해야 하는지는 부등식으로 쉽게 풀 수 있습니다. 아래의 부등식을 봅시다.
100n < 0.01n^2
부등식을 풀면 n > 10,000 이 됩니다. 해석해보면 n이 1만 이상일때 두 번째 알고리즘의 시간복잡도가 더 크다(더 느리다)라는 말이 됩니다. 따라서 n이 1만 이하일 때는 두번째 알고리즘을 선택하고 이상일 때는 첫번째 알고리즘을 선택하는 것이 유리합니다.
궁극적으로는 100n의 시간복잡도를 가진 첫번째 알고리즘이 더 효율적인 알고리즘이 됩니다. 왜나하면 입력크기가 어떤 임계값을 넘으면 그 후로는 항상 첫번째 알고리즘이 효율적이기 때문입니다.
위의 예에서 100n과 같은 시간복잡도를 가진 알고리즘을 1차시간 알고리즘(linear-time algorithms)이라고 하고 0.01n^2과 같은 시간복잡도를 가진 알고리즘을 2차시간 알고리즘(quadratic-time algorithm)이라고 힙니다. 궁극적으로는 어떤 1차시간 알고리즘도 어떤 2차시간 알고리즘보다 항상 효율적입니다.
이해를 돕기위해 시간복잡도가 아래와 같은 세 개의 알고리즘을 살펴봅시다.
algorithm2의 시간복잡도: 0.1n^2
algorithm3의 시간복잡도: 0.1n^2 + n + 100
n이 커짐에 따라 각 알고리즘의 단위연산 수행횟수를 살펴보면 다음과 같습니다.
| n | algorithm1(n) | algorithm(0.1n2) | algorithm3(0.1n2+n+100) |
| 10 | 10 | 10 | 120 |
| 20 | 20 | 40 | 160 |
| 50 | 50 | 250 | 400 |
| 100 | 100 | 1,000 | 1,200 |
| 1,000 | 1,000 | 100,000 | 101,100 |
표에서 볼 수 있듯이 n이 커지면 커질수록 시간복잡도는 시간복잡도 함수의 최고차항의 영향을 가장 크게 받는다는 것을 알 수 있습니다. 즉 다른 항들의 값은 최고차항의 값에 비해 궁극적으로 대수롭게 되기 때문에 알고리즘의 효율성을 비교할 때는 보통 최고차항의 차수를 봅니다.
가장 흔하게 나타나는 복잡도 카테고리와 그래프를 보시겠습니다.
| θ(lg n) < θ(n) < θ(n lg n) < θ(n2) < θ(n3) < θ(2n) < θ(n!) |
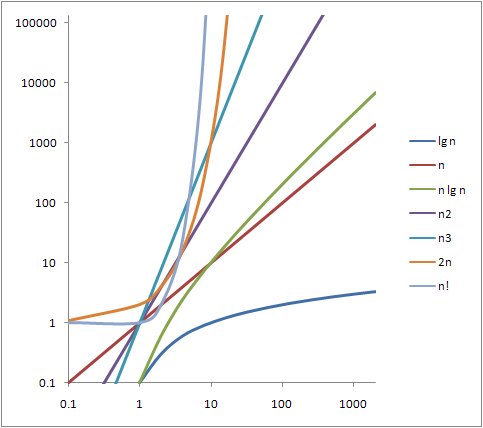
주어진 시간복잡도에 대한 알고리즘의 실행시간은 대략 아래의 표와 같은 비율을 나타냅니다.
| n | lg n | n | n lg n | n2 | n3 | 2n | n! |
| 10 | 0.003 μs | 0.01 μs | 0.033 μs | 0.10 μs | 1.0 μs | 1 μs | 10.87 ms |
| 20 | 0.004 μs | 0.02 μs | 0.086 μs | 0.40 μs | 8.0 μs | 1 ms | 23 years |
| 30 | 0.005 μs | 0.03 μs | 0.147 μs | 0.90 μs | 27.0 μs | 1 s | 2.5 x 1016 years |
| 40 | 0.005 μs | 0.04 μs | 0.213 μs | 1.60 μs | 64.0 μs | 18.3 min | |
| 50 | 0.006 μs | 0.05 μs | 0.282 μs | 2.50 μs | 125.0 μs | 13 days | |
| 102 | 0.007 μs | 0.10 μs | 0.664 μs | 10.00 μs | 1.0 ms | 4 x 1013 years | |
| 103 | 0.010 μs | 1.00 μs | 9.966 μs | 1.00 ms | 1.0 s | ||
| 104 | 0.013 μs | 10.00 μs | 130.000 μs | 100.00 ms | 16.7 min | ||
| 105 | 0.017 μs | 0.10 ms | 1.670 ms | 10.00 s | 11.6 days | ||
| 106 | 0.020 μs | 1.00 ms | 19.930 ms | 16.70 min | 31.7 years | ||
| 107 | 0.023 μs | 0.01 s | 0.222 s | 1.16 days | 31709 years | ||
| 108 | 0.027 μs | 0.10 s | 2.660 s | 115.70 days | 3.17 x 107 years | ||
| 109 | 0.030 μs | 1.00 s | 29.900 s | 31.70 years |
표에서 알 수 있듯이 차수가 올라갈수록 입력 크기가 증가함에 따라 알고리즘의 수행시간은 기하급수적으로 오래걸린다는 것을 알 수 있습니다. 알고리즘의 선택이 중요한 이유가 여기에 있습니다. 10억개의 아이템을 정렬해야 하는데 버블정렬을 사용했다면 31년이나 걸렸겠지만 다행히 O(n log n)에 정렬을 하는 알고리즘이 존재하기 때문에 그 알고리즘을 선택을 하면 29.9초만에 정렬을 완료 할 수 있습니다.
만약 어떤 문제를 해결하는데 2^n의 시간복잡도를 가지는 알고리즘은 금방 생각해 낼 수 있는데 입력크기가 1000이라면 어떨까요? 아마 우주가 멸망할때까지 2^n의 알고리즘으로는 문제의 답을 볼 수 없을것입니다. 이럴때에는 더 좋은 알고리즘(차수가 n^3이하인 알고리즘)을 찾아보거나 최적화알고리즘을 선택해야 합니다.
이상으로 알고리즘의 차수와 효율적인 알고리즘의 선택이 중요한 이유에 대해서 간략히(??) 살펴보았습니다.
Big-O 표기법에 대해서도 살펴보려 했으나 수식이 좀 들어가는 관계로 생략하겠습니다. 혹시나(설마??) 요청이 있다면 다음 기회에 Big-O 표기법에 대해서도 다뤄보겠습니다.
그리고 지금까지는 알고리즘의 효율성을 분석하면서 시간복잡도에 대해서만 고려했는데 메모리가 제약적인 임베디드시스템 같은 경우에는 시간복잡도보다 공간복잡도를 더 중요하게 다뤄야 할 상황도 있습니다. 하지만 대부분의 경우에 메모리가 훨씬더 싸고 공간복잡도는 시간복잡도만큼이나 기하급수적으로 증가하지 않기 때문에(알고리즘의 선택에 따라 공간복잡도도 엄청난 차이를 보이지만 시간복잡도에 비하면 새발의 피라고 표현하고 싶네요) 생략하겠습니다.
지난번에 이어 이번 포스팅까지 머리아픈 글로만 채워진 지루한 포스팅이었는데요..
다음 포스팅에는 정말로 시그 주제에 맞게끔 코딩주제로 넘어가 제귀호출의 코딩과 그 동작원리에 대해서 살펴보도록 하겠습니다.
참고: Foundations of Algorithms / Richrd E. Neapolitan
안녕하세요...........
하나도 안바쁜데 게으름이 넘쳐나서 주체할수 없는 ,,, 김지혜 입니다....
고쳐야 할텐데 말이지요.......
먼저...
모범을 보였어야 했던,,, 제 성의없는 포스팅은.. 깊은 사과를 드리며,,
벌금을 제출하겠습니다 -_ㅠ 죄송합니다.... ( 뭔가 올려놓아야한다는 강박관념에,,, 곧 수정예정 )
그럼 네번째 잔소리 시작합니다.. 죄송해요 ㅠ-ㅠ
1. 시험기간인건 이해하지만,,, 포스팅들이 다들 밀리셨어요...
포스팅에 힘써주세요. 예약기능 유용합니다. (김대욱군, 벌써 12월달 포스팅까지 끝내놓았더군요-)
벌금 내실분들 많으십니다... 모두 기록하고 있습니다. ㄷㄷㄷ
이런 추세라면 회식을 기대하셔도 좋을 듯 합니다 !!!!!! ...... 라니요 ㅠㅠ,, 시그활동 활발히 부탁드립니다
2. 리플을 달아주세요!! ^^*
아무래도 개인맞춤형 시그다 보니 본인 포스팅에만 신경쓰시는 경향이 있는데,,
다른분들의 포스팅에 관심을 가져주세요 ~
" 당신은 예쁘근영 " 리플하나에 싹터오는 +_+... 뭐...?..지..;
p.s 위 사항은 어딘가에서 들려온 건의사항이였습니다~...
3. 멤버십 블로그의 경우,
우수한 카테고리의 내용만 올리는것이 어떠냐는 이희병운영자님의 피드백을 받아서
현재 무조건복사붙여넣기식의 퍼나름은 멈춰있는 상태입니다. ^^
공지에 추천 해주시면 감사하겠습니다. ㅋㅋ 자기 추천 가능합니다!! 세분정도 제가 잘 살펴보고 퍼가도록 하겠습니다.
선정되신 세분에게는 상품으로 벌금 1회 무효권을 제공하겠습니다 !!
p.s 위 사항은 운영자님에게 받은 피드백이며, 이번주 일요일까지 선정하도록 하겠습니다.
4. 벌금은 회식 일주일전에 부터 일괄적으로 받겠습니다. ㅋ
지금은 일단 죽음의 카운트만 올라갈 뿐입니다.
p.s 현재 , 박상용님(2회), 차주민님(1회), 박진영님(1회), 서상원님(1회)
박은병님 (1회) 박윤성님 (1회) 유광현님(1회) 채은석님(1회) 김지혜(1회)
5.
시그의 종료일은 12월 25일로 잡고 있습니다.
일주일에 1개이상씩의 포스팅을 한다고 하신다면 종료일까지 10~11개의 포스팅을 하셔야합니다.
최악의 경우 5만원... ㄷㄷㄷ 한 벌금이 부여됩니다.
하지만 우리 시그의 목적이 벌금을 걷어 회식을 하자. 가 아닌
각자 공부하고 있는 내용을 정리하고, 하나의 레퍼런스를 만들어 보자는 취지이기 때문에
벌금보다는 포스팅에 목말라 있습니다.
그래서 룰하나를 추가합니다.
앞으로 지각은 있되, 포스팅은 빼먹지 않는것으로 하겠습니다.
지각은 벌금 5000원이고요 (기존과같음) 지각의 한계는 없습니다만,
12월 25일 시그 종료일에 확인하여 10개이상의 포스팅이 되지 않으신 분은 지극히 개인적인 면담들어갑니다 ㅋㅋ.
장난아닙니다 -_-;; 무서운면담 ㄷㄷㄷ ㅋㅋㅋ
.... 이렇게 강압적으로 나가고 싶진않았지만,,, 원활한 시그활동을 위하여 강압적으로 한번 해겠습니다.
(근데 저부터 잘해야할텐데 말이지요 ㄷㄷㄷ)
^^*
아참, 시그종료인원이 되지 않으셔도,,, 벌금은 ,,, 걷을지도,,,
죄송합니다. 그래도 우리 열심히해보아요~!
6. 포스팅의 질 여부는 판단하기가 오묘하다 생각하여 구지 태클걸지 않는 편입니다만,,,
(사실 다들 양질의 포스팅을 해주시고 계셔서 구지 태클걸 필요는 없습니다만,,,)
앞으로는
처음부터 끝까지 모든 내용을 복사 붙여넣기 하시는 포스팅은,
포스팅 안하신걸로 체크하여 벌금을 받도록 하겠습니다
(지각벌금 5000원) .
물론 참고하시는 것은 좋습니다. 말씀드린것 처럼 처음부터 끝까지 모든 내용의 복사붙여넣기입니다.
^^양질의 포스팅 부탁드립니다.
잔소리가 너무 길어졌네요,,,,
-_ㅠ,,
이거 뭐 대충해도 되는 시그인줄알았는데 아니잖아 ㄷㄷㄷ .. 죄송하구욤 ㅠ
모두모두 많은것을 얻어갈 수 있는 시그가 되길 바라면서... 요기까지 잔소리를 줄이도록 할께요!!
p.s 하시고싶으신 말씀은 리플로 ㅋㅋㅋ
p.s2 아참, 시그활동을 해주시는 모든분들.
포스팅을 열심히 해주시는 시그원분들 -_ㅠ
제가 정말 감사하고 있다는걸 꼭.꼭.꼭.알아주셨음 좋겠어요 !!
정말 감사해요! ^-^*

