2008. 10. 23. 22:00 :: 알고리즘코딩기법
안녕하세요.
이번에는 지난 포스팅에 이어 알고리즘의 차수에 대해서 알아보겠습니다.
지난글의 마지막에 이번시간부터는 본격적으로 코딩기법에 대해서 포스팅하겠다고 했는데 생각을 해보니 일단 차수에 대해서는 언급을 하고 넘어가야 할 것 같아서 순서를 바꿨습니다 ^^
알고리즘의 분석
알고리즘이 문제를 얼마나 효과적으로 해결하는지를 결정하기 위하여 알고리즘을 분석할 필요가 있습니다. '알고리즘 코딩기법 1 - Introduction' 에서 소개했던 순차검색과 이분검색의 비교가 바로 알고리즘의 분석이라고 할 수 있고 분석결과 n이 커질수록 이분검색이 유리하다고 결론을 내렸었는데요, 이번 파트에서는 알고리즘의 분석에 대해서 좀 더 자세히 알아보겠습니다.
복잡도 분석(complexity analysis)
시간을 기준으로 알고리즘의 효율을 분석할 때 보통은 CPU에서의 실제 작동시간으로 분석을 하지는 않습니다. 왜냐하면 사용하는 컴퓨터의 성능에 따라 결과가 다르게 나타나기 때문입니다. 그 외에 알고리즘을 구현하는데 사용한 언어나 컴파일러, OS에 따라서도 시간이 다르게 측정될 수 있습니다. 따라서 알고리즘의 효율성을 분석하기 위해서는 위에서 언급한 것들과는 독립된 다른 기준이 필요합니다.
알고리즘의 시간복잡도를 분석할 땐 '1-Introduction' 에서 그랬듯이 입력크기 n에 대해서 알고리즘의 단위연산이 수행되는 횟수를 비교하여 분석하는 기법을 가장 많이 사용합니다. 일반적으로 알고리즘의 실행시간은 입력의 크기에 따라 증가하고, 총 실행시간은 단위연산이 몇 번 수행 되는가에 비례합니다. 따라서 단위연산이 수행되는 횟수를 입력의 크기에 대한 함수로 나타내어 알고리즘의 효율성을 분석할 수 있습니다.
입력크기(input size)
말 그대로 알고리즘으로의 입력의 크기를 의미합니다. 대부분의 알고리즘에서 입력을 크기를 구하기는 매우 쉽습니다. 예를 들어 n개의 아이템을 정렬하는 알고리즘에서 입력크기는 아이템의 갯수인 n이 됩니다. n번째 피보나치항을 구해야 하는 알고리즘의 시간복잡도는 n에 비례할 것입니다. (하지만 엄밀히 따지면 입력크기가 n이라고 말할 수는 없습니다)
단위연산(basic operation)
어떤 명령문이나 일련의 명령문의 집합을 선정하여, 알고리즘이 수행한 총 작업의 양을 이 명령문이나 명령문의 집합을 수행한 횟수에 대략적으로 비례하게 되었을 때, 이 것을 단위연산이라고 합니다. 예를 들어 버블소트 알고리즘에선 두 아이템을 비교를 하고 아이템을 위치를 바꾸는 작업을 하나의 단위연산으로 볼 수 있습니다.
시간복잡도 분석(time complexity analysis)
알고리즘의 시간복잡도 분석은 입력크기의 값에 대해서 단위연산을 몇 번 수행하는지를 구하는 것입니다.
차수
동일한 일을 하는 두 개의 알고리즘이 있습니다. 하나는 시간복잡도가 100n이고 나머지 하나는 0.01n^2 일 때, 어떤 알고리즘이 더 효율적일까요..
사실 두 알고리즘 중 어떤 알고리즘을 선택해야 하는지는 부등식으로 쉽게 풀 수 있습니다. 아래의 부등식을 봅시다.
100n < 0.01n^2
부등식을 풀면 n > 10,000 이 됩니다. 해석해보면 n이 1만 이상일때 두 번째 알고리즘의 시간복잡도가 더 크다(더 느리다)라는 말이 됩니다. 따라서 n이 1만 이하일 때는 두번째 알고리즘을 선택하고 이상일 때는 첫번째 알고리즘을 선택하는 것이 유리합니다.
궁극적으로는 100n의 시간복잡도를 가진 첫번째 알고리즘이 더 효율적인 알고리즘이 됩니다. 왜나하면 입력크기가 어떤 임계값을 넘으면 그 후로는 항상 첫번째 알고리즘이 효율적이기 때문입니다.
위의 예에서 100n과 같은 시간복잡도를 가진 알고리즘을 1차시간 알고리즘(linear-time algorithms)이라고 하고 0.01n^2과 같은 시간복잡도를 가진 알고리즘을 2차시간 알고리즘(quadratic-time algorithm)이라고 힙니다. 궁극적으로는 어떤 1차시간 알고리즘도 어떤 2차시간 알고리즘보다 항상 효율적입니다.
이해를 돕기위해 시간복잡도가 아래와 같은 세 개의 알고리즘을 살펴봅시다.
algorithm1의 시간복잡도: n
algorithm2의 시간복잡도: 0.1n^2
algorithm3의 시간복잡도: 0.1n^2 + n + 100
algorithm2의 시간복잡도: 0.1n^2
algorithm3의 시간복잡도: 0.1n^2 + n + 100
n이 커짐에 따라 각 알고리즘의 단위연산 수행횟수를 살펴보면 다음과 같습니다.
| n | algorithm1(n) | algorithm(0.1n2) | algorithm3(0.1n2+n+100) |
| 10 | 10 | 10 | 120 |
| 20 | 20 | 40 | 160 |
| 50 | 50 | 250 | 400 |
| 100 | 100 | 1,000 | 1,200 |
| 1,000 | 1,000 | 100,000 | 101,100 |
표에서 볼 수 있듯이 n이 커지면 커질수록 시간복잡도는 시간복잡도 함수의 최고차항의 영향을 가장 크게 받는다는 것을 알 수 있습니다. 즉 다른 항들의 값은 최고차항의 값에 비해 궁극적으로 대수롭게 되기 때문에 알고리즘의 효율성을 비교할 때는 보통 최고차항의 차수를 봅니다.
가장 흔하게 나타나는 복잡도 카테고리와 그래프를 보시겠습니다.
| θ(lg n) < θ(n) < θ(n lg n) < θ(n2) < θ(n3) < θ(2n) < θ(n!) |
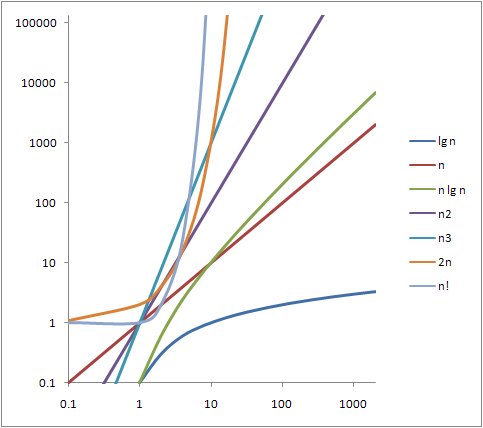
주어진 시간복잡도에 대한 알고리즘의 실행시간은 대략 아래의 표와 같은 비율을 나타냅니다.
| n | lg n | n | n lg n | n2 | n3 | 2n | n! |
| 10 | 0.003 μs | 0.01 μs | 0.033 μs | 0.10 μs | 1.0 μs | 1 μs | 10.87 ms |
| 20 | 0.004 μs | 0.02 μs | 0.086 μs | 0.40 μs | 8.0 μs | 1 ms | 23 years |
| 30 | 0.005 μs | 0.03 μs | 0.147 μs | 0.90 μs | 27.0 μs | 1 s | 2.5 x 1016 years |
| 40 | 0.005 μs | 0.04 μs | 0.213 μs | 1.60 μs | 64.0 μs | 18.3 min | |
| 50 | 0.006 μs | 0.05 μs | 0.282 μs | 2.50 μs | 125.0 μs | 13 days | |
| 102 | 0.007 μs | 0.10 μs | 0.664 μs | 10.00 μs | 1.0 ms | 4 x 1013 years | |
| 103 | 0.010 μs | 1.00 μs | 9.966 μs | 1.00 ms | 1.0 s | ||
| 104 | 0.013 μs | 10.00 μs | 130.000 μs | 100.00 ms | 16.7 min | ||
| 105 | 0.017 μs | 0.10 ms | 1.670 ms | 10.00 s | 11.6 days | ||
| 106 | 0.020 μs | 1.00 ms | 19.930 ms | 16.70 min | 31.7 years | ||
| 107 | 0.023 μs | 0.01 s | 0.222 s | 1.16 days | 31709 years | ||
| 108 | 0.027 μs | 0.10 s | 2.660 s | 115.70 days | 3.17 x 107 years | ||
| 109 | 0.030 μs | 1.00 s | 29.900 s | 31.70 years |
표에서 알 수 있듯이 차수가 올라갈수록 입력 크기가 증가함에 따라 알고리즘의 수행시간은 기하급수적으로 오래걸린다는 것을 알 수 있습니다. 알고리즘의 선택이 중요한 이유가 여기에 있습니다. 10억개의 아이템을 정렬해야 하는데 버블정렬을 사용했다면 31년이나 걸렸겠지만 다행히 O(n log n)에 정렬을 하는 알고리즘이 존재하기 때문에 그 알고리즘을 선택을 하면 29.9초만에 정렬을 완료 할 수 있습니다.
만약 어떤 문제를 해결하는데 2^n의 시간복잡도를 가지는 알고리즘은 금방 생각해 낼 수 있는데 입력크기가 1000이라면 어떨까요? 아마 우주가 멸망할때까지 2^n의 알고리즘으로는 문제의 답을 볼 수 없을것입니다. 이럴때에는 더 좋은 알고리즘(차수가 n^3이하인 알고리즘)을 찾아보거나 최적화알고리즘을 선택해야 합니다.
이상으로 알고리즘의 차수와 효율적인 알고리즘의 선택이 중요한 이유에 대해서 간략히(??) 살펴보았습니다.
Big-O 표기법에 대해서도 살펴보려 했으나 수식이 좀 들어가는 관계로 생략하겠습니다. 혹시나(설마??) 요청이 있다면 다음 기회에 Big-O 표기법에 대해서도 다뤄보겠습니다.
그리고 지금까지는 알고리즘의 효율성을 분석하면서 시간복잡도에 대해서만 고려했는데 메모리가 제약적인 임베디드시스템 같은 경우에는 시간복잡도보다 공간복잡도를 더 중요하게 다뤄야 할 상황도 있습니다. 하지만 대부분의 경우에 메모리가 훨씬더 싸고 공간복잡도는 시간복잡도만큼이나 기하급수적으로 증가하지 않기 때문에(알고리즘의 선택에 따라 공간복잡도도 엄청난 차이를 보이지만 시간복잡도에 비하면 새발의 피라고 표현하고 싶네요) 생략하겠습니다.
지난번에 이어 이번 포스팅까지 머리아픈 글로만 채워진 지루한 포스팅이었는데요..
다음 포스팅에는 정말로 시그 주제에 맞게끔 코딩주제로 넘어가 제귀호출의 코딩과 그 동작원리에 대해서 살펴보도록 하겠습니다.
참고: Foundations of Algorithms / Richrd E. Neapolitan

