.net framework 가장 처음 포스팅에서 말했던 부분을 다시 살펴봅시다~
.NET이라는 목표를 이루기 위해 실질적으로 돌아가는 Window기반의 응용프로그램을 개발하기 위한 기반이 되는 환경이 바로 .NET Framework라고 이야기 했었구요~
여기 목표라고 써있는 .NET이란 XML기반의 웹 서비스를 통해 서로 다른 시스템을 통합하기 위한 제반 환경 및 기반이라고 이야기 했었습니다.
자 대략적인 내부구조의 개괄적인 설명은 앞의 2포스팅에서 거의 다봤다고 생각이 드는데 XML이란 부분에서 약간 걸리는 것이 있네요 'XML기반의 웹 서비스'라고 할 때 XML이 뭔지 우선 알아야 할 법하여 간략히 정리해 보겠습니다. 아마 XAML이란 용어도 어디선가 들어보셨을 법하여 우선 제목에 같이 써놓았습니다.
XML?
우선 거창하게 영어 이름부터 풀어놓아보겠습니다. Extensible Markup Language. 해석하면 확장가능한 생성 언어 정도겠군요.
역사만 따져보면 XML은 1996년 W3C에서 제안하였구요 1998년 2월 W3C에서 처음으로 표준을 발표한 이래로 꾸준히 발전하면서 새로운 웹을 만들기 위한 여러 시도 중 한가지이면서 새로운 웹의 어찌보면 가장 기반이 되는 기술이라고 할 수 있을 정도로의 큰 부분이기도 합니다.
웹에서 가장 많이 기본으로 보는 것이 HTML입니다. 근데 ML부분이 일단 같은 약자입니다. 웹과 관련된 부분이니 역시 큰 연관관계가 있겠죠. 지금의 웹은 HTML로도 잘 돌아가고 있습니다. 여러 스크립트 언어나 서버 사이드 스크립트언어(PHP와 같은)언어들로 동적으로도 잘 돌아가고 있습니다. 하지만 곰곰히 생각해보면 문제가 있습니다.
최근 크롬이나 파이어폭스 등 브라우져가 널리 배포되면서 이곳저곳 페이지에 들어가보면 IE에서는 잘 돌아가던 페이지가 안되는 부분이 꽤있죠. 특히 초창기에 심했구요. 심지어 브라우저가 제작되던 초기에 IE와 넷스케이프도 자주 겪던 일인데 호환성의 문제가 있습니다. HTML은 분명 display를 위한 정적인 언어지만 이를 보완하기 위해 스크립트 등을 사용하다보니 각 스크립트, 제품별로 상호호환이 안되는 것이 큰 문제였고 지금 또한 그러한 문제가 남아있습니다.
또하나의 커다란 문제는 HTML은 display를 위한 언어, 즉 사용자가 눈으로 보고 읽을 수 만 있다면 컴퓨터는 그냥 뿌려주기만 하면 되는 역할을 가진 언어입니다. 동적으로 뿌려주는 부분은 프로그램으로 결국 클라이언트의 요청을 서버에서 처리하여 정적인 HTML 페이지를 클라이언트에게 보내주는 것일 뿐입니다. 하지만 이러다보면 문제가 자연스레 생깁니다. 요즘 검색엔진이 유난히 많아졌는데 검색어를 넣다보면 완전 엉뚱한 링크들이 모여있는 것을 볼 수 있습니다. 이게 바로 HTML로 이루어진 문서의 문제인데 검색어가 설령 HTML로 이루어진 페이지 속에 들어있다 하더라도 동의어나 문맥의 어떤부분인지 비중은 어떠한지에 대해 컴퓨터는 전혀 알 수 없기 때문에 검색을 하라고 컴퓨터에 시켜도 결국 정확한 값을 얻어오기는 힘들다는 것 입니다.
(이부분을 보완하기위해 수많은 알고리즘과 많은 테스트, 시도 등이 있었고 지금도 있습니다.)
또한 그외에도 HTML은 우선 태크가 한정적이기 때문에 구시대에는 그것만으로 모든 것을 표현 가능했을지 모르나 표준이 추가되지 않는한 확정성이 상대적으로 제한적입니다.
여튼 이런 문제들을 XML로 해결할 수 있다! 가 XML이 나오게 된 이유라고 할 수 있습니다. (즉 HTML의 문제점이 되는 부분을 해결할 수 있다.) 라는 것이죠.
물론 이런 문제점을 보완하기 위해서 제시된 표준이 XML이 최초는 아닙니다. SGML(표준화된 일반 마크업 언어)라고 하여 정부기관 등에서 많이 사용된 언어가 있습니다. 하지만 덩치가 크고 무거운 표준이고 웹이 발달하기 전의 언어라 웹에 대한 지원이 부족하기 때문에 웹에 사용하기에는 부적합했습니다. 하지만 결국 이것이 XML의 모태라고 해도 될 것 같습니다. XML은 현재 SGML의 많은 기술적인 부분을 받아들여 발전해 나가고 있습니다. 간략하게 둘을 비교하자면 아래의 그림과 같습니다.
그럼 다시 정리해서 XML의 장점은 뭐냐! 이렇게 물어본다면

1. 문서의 내용, 디자인이 완전히 분리되어 있다는 겁니다.
(문서의 구조는 XML문서를 통해서 트리구조의 구조적인 형태로 나타냅니다. 그리고 출력, 포매팅은 XSL 문서를 통해서 나타낼 수 있습니다.)2. 다양한 방식의 링크 기능을 제공합니다.
(XLink, XPointer를 이용하면 기존 HTML에서 이용하던 하이퍼링크 이상의 기능을 발휘할 수 있습니다.)3. 표준화된 DTD를 통해서 모든 분야에서 사용이 가능합니다.
(많이 사용되는 WML, SMIL, SVG등이 모두 XML에 기반을 둔언어입니다. 이것은 XML의 DTD를 선언하고 모든 사용자가 그 규칙에 맞추어 사용하면 컴퓨터나 사람이 모두 해석할 수 있는 메타 언어가 된다는 거죠.)
장점을 써놓았지만 처음보시는 분이 딱보고 2가지 이상이해 하셨으면 성공입니다~ 나머지는 차근차근 알아가면되겠구요
자 그럼 XML이란 것이 HTML로 이루어진 문서보다 낫다라는 식으로 앞에서 이야기 했던것은 다름이 아니라 어떤 신문기사에 나온 내용을 XML로 가지고 있다면 이를 다른 미디어로 보내는 것은 XML 포매팅만 새롭게 해준다면 기존의 XML문서를 이용해서 쉽게 할 수 있습니다. (<- 한번만 더 읽어보시고 잘 생각해보세요. 기존의 신문기사를 보고 만약 다른 미디어로 이를 재현하려면 어떠한 노력이 들지를 생각해보세요)
이런 것이 가능한 이유는 XSLT라는 W3C에서 발표한 XML표준안 때문입니다. 각 밴더들이 이에 대한 솔루션을 내놓고 있구요. 예시를 들자면 XSL의 포매팅 객체 (Formatting Object)를 이용해서 PDF파일(아크로뱃리더)형식과 HTML과 WAP의 3가지 형태로 출력하는 외국의 사이트를 본적이 있네요.. (http://www.renderx.com/)
이런 식으로 최근에는 XML이 보편화 되어가고 있습니다.
이렇게 좋은 것을 왜 널리 안쓰고 있느냐라고 하지만 XML은 현재 제한된 부분만 구현되어있고 개발되어지고 있다라는 것을 알고 이번 포스팅은 여기까지 하도록 하겠습니다. (표준이 제시되었다고 해서 완성된 것은 아니죠)
Referenced by XML DeveloperGroup Community & Wikipedia
저번 포스팅에서 예고해드린데로 이번에는 재귀호출에 대해서 다뤄볼까합니다.
물론 멤버십에 계신분들중에 재귀호출을 어려워 하실 분들은 없으리라 생각하는데요, 학교에서 주위를 살펴보면 재귀호출을 잘 못하는 친구나, 후배나, 등등 많은 것 같습니다. 그 만큼 재귀호출이 직관적으로 이해가 잘 안되는 부분인가 봅니다. C++과 싸우다 보면 포인터에서 한 번 좌절을 하게 되고 포인터를 넘고나면 재귀호출이 또다시 태클을 건다는.. 뭐 그런 전설이 내려오는데요.. 저도 지금 재귀호출을 어떻게 다뤄야할지 막막합니다 ㅠㅠ
뭐.. 어쨌든..... 각설하고 시작하겠습니다.

재귀(Recursion)
주어진 문제를 재귀적으로 푼다는 말은 문제의 답이 그 문제와 동일한 형태의 더 작은 부분문제(sub problem)의 답에 의존적(dependency)이다 라는 의미를 가지고 있습니다.
흠.. 무슨말인지 모르겠습니다. 이해를 돕기 위해 쉬운 예를 들어 보겠습니다.
누가 저 작품에 레고블럭이 몇 개가 쓰였는지 물어봅니다.
도저히 한눈에 레보블럭이 몇 개가 쓰였는지 알지 못하겠습니다.
레고를 쪼갭니다.
아직 각각이 몇개씩인지 모르겠습니다.
다시 레고를 쪼갭니다.
아직 모르겠습니다.
다시 레고를 쪼갭니다.
...
...
이제 몇 개인지 눈에 보입니다.
쪼갰던 레고를 합칩니다.
각각의 답도 같이 합칩니다.
쪼갰던 다른 레고를 합칩니다.
각각의 답도 같이 합칩니다.
계속 합칩니다.
...
처음의 레고 작품으로 돌아왔습니다.
이제 이 작품에 레고블럭이 몇 개가 쓰였는지 압니다.
위의 과정을 분할정복(Divide and Conquer)라고 합니다.
재귀호출은 분할정복, 백트레킹 뭐 이런 녀석들이랑 땔래야 땔 수 없는 사이인데요, 이 녀석들의 특징이 주어진 문제를 더 작은 문제로 분할하여 문제를 해결한다는 점에서 동일한 특성을 가지고 있기때문입니다. 실제로 거의 대부분의 경우 D&C나 백트레킹은 재귀함수로 구현하는 경우가 많습니다.
재귀함수(Recursive Function)
재귀적으로 문제를 푸는 함수를 재귀함수라고 하고 직간접적으로 자기자신을 호출합니다.
재귀적으로 문제를 푼다(동일한 형태의 다 작은 부분문제를 풀어나감)는 것을 생각해 봤을 때, 반복이 진행될 때마다 동일한 작업을 해야 한다는 것을 짐작할 수 있습니다.(동일한 형태의 문제를 푸니깐;) 그리고 더 이상 문제를 쪼개지 않아도 되는 상황에 언젠가는 도달해야 합니다. 따라서 재귀함수는 자기자신을 호출하고(동일한 형태) 언젠가는 종료를 해야합니다.
또.. 무슨 말인지 모르겠습니다. 프로그래머는 코드로 말한다고 코드를 보는게 더 쉽겠네요
수도코드보기
Begin
If It can possible to solve this problem then
Solve problem
Return solution
Else
Divide problem to subproblem1 and subproblem2
// 쪼갠 문제를 가지고 재귀호출 ㄱㄱㅆ
Type res2 = RecursiveFunction(subproblem2)
// 쪼개진 문제의 답을 조합하여 이 문제의 답을 구해 리턴
Return compose res1 and res2
현실적인 예를 들기위해 n!을 재귀적으로 구해보도록 합시다.
여러분은 10!이 얼마인지 아십니까?? 모르겠죠?? 저도 모릅니다. 그래도 10! 은 9!에다가 10을 곱했다는 거는 알 것 같습니다.. 모르시면 중학교 수학책을 찾아보십시오.
코딩을 하기 위해서는 수식을 일반화할 필요가 있는데요 지금껀 일반화하기 그닥 어렵지 않습니다.
= (n-1) * n (n >= 2) - 재귀호출
위와 같은 식을 점화식(Recurrence relation)이라고 합니다. 고등학교 수학시간에 수열의 일반항을 구할때 많이 들었던 용어일겁니다. 각설하고 점화식을 알았으면 바로 그래도 코드로 옮겨주면 됩니다.
- int fac(int n)
- {
- if (n <= 1) return 1;
- return n * fac(n-1);
- }
제가 주로 사용하는 언어가 C++인 관계로 C++로 코딩했습니다. 뭐 근데 생각해보니 저 함수는 자바나 C#으로 짜도 저렇게 나오겠네요 쿨럭; 여튼 앞으로도 계속 C++로 작성하겠습니다.
호출이 일어나는 순서를 도식화 하면 더 알기 쉽겠죠?
fac(5)를 호출했을 때 상태의 변화를 도식화하면 아래와 같습니다.
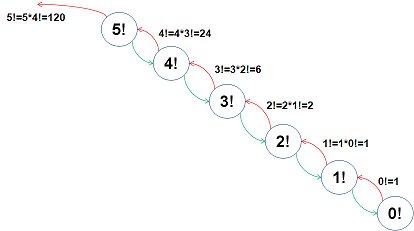
뭐 여기까지 이미 다 알고계신 내용이었을테구요..
재귀함수를 작성하다 보면 의도하지 않은 크리티컬한 문제에 봉착하게 되는 경우가 있습니다. 아래의 예를 봅시다.
공대를 다니면서 절대 피할수 없는 수열이 있습니다. 바로 피보나치수열인데요. 점화식은 아래와 같습니다.
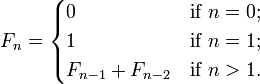
점화식대로 재귀함수를 코딩하면 이렇게 나오죠
- int fib(int n)
- {
- if (n <= 1) return n;
- return fib(n-1) + fib(n-2);
- }
그런데 여기에 엄청난 문제가 있습니다.. 눈치 채셨습니까??
함수의 콜 상태를 도식화 해보면 이렇습니다.
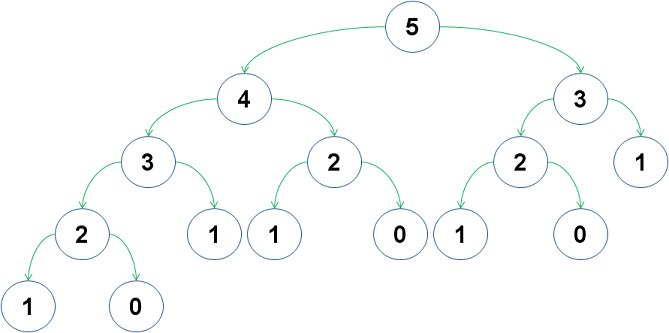
이 엄청난 문제 눈치채셧습니까??
그림을 잘 보면 fib(3)이 두번 계산 되는걸 알 수 있습니다. fib(2)는 3번이구요 fib(1)은 5번이나 호출되네요..
저게 fib(5)를 구하는 그림이라 그렇지 fib(50)을 구한다고 생각해보십시오.. 끔찍합니다..
분석을 해보면 저런식으로 함수를 구현하게 되면 fib(n)을 구하는데 대략 2^n번의 함수 호출이 발생합니다. fib(50)을 구한다면??또 이 표현 안할수가 없네요. 지구가 멸망할때까지 답을 못봅니다
다행이도 이런 문제를 해결하는 Memoization이라는 기법(Memorization이 아닙니다)이 있는데요, 언젠가 포스팅을 하겠습니다.
하노이의 탑
마지막으로 하노이 탑을 옮겨보도록 하겠습니다.
하노이의 탑 하러가기
하노이의 탑은 세개의 공간 중 한 공간에 쌓여진 탑을 한 번에 하나의 층만 이동하여 다른 공간으로 이동하는 문제인데요 이동하는 도중에 크기가 더 큰 층이 작은 층 위에 올라올 수 없습니다.
최소의 횟수로 하노이의 탑을 옮기는 방법은 단 한가지가 존재하는데 옮기는 횟수가 무려 2^n-1 번이나 됩니다.
인도의 베레니스에 있는 한 사원에 64층의 하노이 탑이 있는데 이 탑을 위의 규칙에따라 옮기면 탑은 무너지고 세상은 종말한다라는 예언이 전해오는데요.. 사실 64층의 탑을 사람의 힘으로 옮기려면 영겁의 세월이 걸립니다. 그 전에 세상이 종말하겠죠;
그럼 본격적으로 하노이 탑을 옮겨보도록 하겠습니다.
source(S)에 있는 n층의 하노이탑을 destination(D)으로 옮기고자 합니다. 그리고 이를 위해 temp(T)라는 공간이 준비되어 있습니다.
크게 생각해보면 n층의 하노이 탑을 옮기려면 n-1층까지 모든 블록을 S->T로 옮기고 젤 마지막 조각을 S->D로 옮긴 다음에 T에 있는 n-1층의 하노이탑을 D위에 쌓으면 됩니다. 그럼 여기에서 n-1층의 하노이 탑을 옮기는 과정(S->T, T->D)이 필요한데, 이 과정은 n층의 하노이 탑을 옮기는 과정과 방법이 같습니다.
우선 n-1층의 탑을 S->T로 옮기는 것을 생각해봅시다. 이경우 S가 원본이되고 T가 목적지가 됩니다. 각각 S'과 D'이라고 하고 남은 슬롯인 D를 이 경우에서는 임시공간으로 사용하므로 T'이라하면, 우선 n-2층까지 S'->T'으로 옮기고 n-1층을 S'->D'으로 옮깁니다. 그 후 T'에 있는 n-2층까지의 블록을 D'위로 옮겨놓으면 됩니다. 여기에서 또 n-2층을 옮기는 방법을 알아야 하는데요 n-1층을 옮기는 방법과 똑같이 하면 됩니다. 이 과정을 1층이 될때까지 재귀적으로 수행하면 됩니다.
그림보기
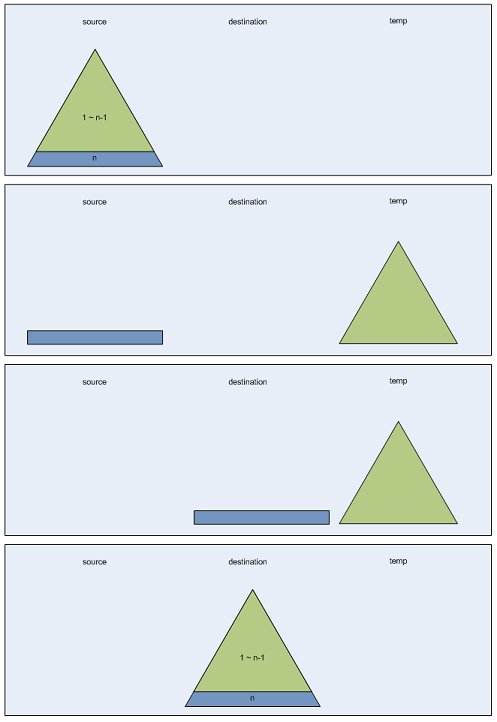
이제 위의 과정을 함수로 작성해봅시다.
함수 TowerOfHanoi(int n, int a, int b, int c) 을 n층의 하노이이 탑을 a에서 b로 c의 임시공간을 이용해서 옮기는 함수라고 정의하면 함수의 몸체는 위에서 설명한 세단계(n-1층까지 a->c로 옮김, n층을 a->b로 옮김, n-1층까지 c->b로 옮김)으로 구성됩니다. 이 세 단계를 모두 재귀호출을 이용하여 구현하면 하노이의 탑은 아래와 같이 간단하게 구현됩니다.
- // 하노이의 탑
- // n층의 탑을 a에서 b로 옮긴다. c는 여유공간
- void TowerOfHanoi(int n, int a, int b, int c)
- {
- // 종료조건
- if (n == 1)
- {
- printf("%d -> %d\n", a, b);
- return;
- }
- // 1~n-1층까지 a->c로 옮긴다
- TowerOfHanoi(n-1, a, c, b);
- // n번째 층을 a->b로 옮긴다
- TowerOfHanoi(1, a, b, c);
- // 1~n-1층까지 c->b로 옮긴다
- TowerOfHanoi(n-1, c, b, a);
- }
TowerOfHanoi(4, 1, 2, 3); 을 실행한 결과는 다음과 같습니다.
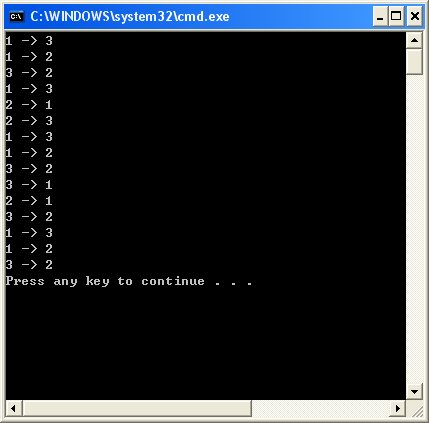
답이 제대로 나온 것 같나요??
다음에는 바이너리서치를 구현하는 방법에 대해서 얘기해보겠습니다.

