요즘에는 시험공부 모드로 과제가 살짝 중단이 되어있어서
하드웨어에 입문하게 되면
가장 기초 중에 기초이면서도 난관인 ADC(Analog to Digital Converter)를 소개해봅니다.
우선 이론적인 내용을 긁어왔습니다. (만들기도 뭣한데 긁을만한 자료가 없어서 ,, 좀 오래된 느낌의 페이지를 갖고 왔습니다.)
세상은 모두 아날로그로 되어 있고, 이걸 디지털화시키면서, 디지털이라는 것이 생긴 겁니다 .따라서 모든! 기계나 제어장치에는
아날로그 디지털 컨버터가 들어갑니다.
하지만 요 개념이 처음에는 잘 와닫지 않습니다.
사실 직접 알려드리는 것이 훨 나을 듯 하지만,,,,
우선 블로그부터,,^^;
내용의 질이 좋지 못하군요^^
직접 만들기엔 양이 방대해서,,, 우선 좀 여기저기 있는 것 좀 정리했습니다.^^
다음 기회에 좀 더 보강해 보도록 하죠!!!
저는 DSP(Digital Signal Processing)시험이 있어서...ㅎㅎㅎ 요것도 아날로그를 디지털화 시킨다음 연산을 하는 이론입니다.^^
아날로그신호를 디지탈신호로 변환하는 여러 가지 방법이 있으나 그 주가 되는 3가지 방법에 관해서 회로구성, 동작원리, 특징 등을 설명한다. AD변환에는 입력 아날로그신호에 포함된 최고주파수의 2배 이상으로 샘플링하여야만 원신호를 재현할 수 있다는 사실이 알려져 있다(Nyquist 정리). 따라서 고주파신호일수록 고속 ADC를 요구한다. 또 ADC의 출력 2진수의 비트수가 많을수록 ADC의 분해능(resolution)이 높다고 말하며 입력 아날로그신호의 레벨이 더 세분화되어 디지탈신호로 표현된다.
병렬비교 ADC


이것은 병렬 비교형 ADC로써 flash형이라고도 불리우며 가장 속도가 빠른 ADC이다. 그림 17-1은 그 구조를 나타내며 아날로그 입력 전압
변환속도는 비교기 및 엔코더의 지연의 합에 의해서 결정되며, 현재 20ns이하의 ADC도 사용되고 있다. 4∼8비트(16∼256레벨)가 상용화되고 있으며 비트 수가 이 이상되면 구조가 너무 커진다. 1초에 변환할 수 있는 수를 변환율(conversion rate)이라 하고 변환속도의 역수와 같다.
이중적분형(dual slope) ADC

이것은 비교적 서서히 변하는 아날로그 신호를 정밀하게 디지탈신호로 변환하는 데 적합한 것으로써 그림 17-3에 표시한 바와 같이 적분기, 비교기, 카운터로 구성된다. 원리적으로 아날로그 전압에 비례하는 시간동안 클럭펄스를 카운트하여 그 카운트 수를 디지탈신호로 출력한다. 아날로그 입력전압에 비례하는 시간을 얻는 데 적분기를 쓴다. 그림에서 기준전압
이 회로는 RC에 무관하므로 R, C의 값이 정밀할 필요가 없다.
이 ADC는 아날로그 입력전압과 기준전압을 2회 적분하기 때문에 이중적분형이라고 부른다. 동작원리로부터 이 회로는 고속 AD변환에는 부적당함을 알 수 있다. 그러나 회로가 간단하고, 잡음에 강하므로(잡음을 적분하면 0이 된다 ; 또 1/60초 마다 한번씩 적분하면 60Hz의 방해도 제거된다) 저속 고정밀도 ADC에 흔히 쓰인다. 예컨대 6자리(999999 = 106-1 221 ; 21비트) 디지탈 전압계등은 이런 ADC를 이용한다.
DA 피드백 형 ADC
이것은 ADC의 츨력 디지탈 부호를 다시 DA로 변환하여 입력신호와 비교한다. 다음 3가지가 있다.
(1) 계단형 ADC(staircase ADC)

그림 17-4(a)에서 S/H된 아날로그신호
(2) 추적형 ADC(tracking ADC)

그림 17-5(a)는 그림 17-4(a)의 UP카운터를 UP/DOWN 카운터로 대치한 것으로써 이 그림에서 알 수 있듯이 작은 변화를 추적해가는 데 유용하다. 먼저와 같이 t=0에서 카운터는 0으로 세트된다. 따라서 DAC 출력전압
(3) 축차근사 ADC(successive approximation ADC)

이것은 카운터 대신 더 복잡한 디지탈회로를 포함한다. 처음에 모든 비트를 0으로 세트한다. MSB부터 시작하여 각 비트를 차례로 1로 세트한다. DAC의 출력은 비교기에서 입력신호
이 형의 ADC는 구조가 간단하고 비교적 정확하고 빠르기 때문에 많이 사용된다. 현재 8∼19비트의 AD변환 시간이 10μs되는 것들이 있다.
잘 이해가 되지 않으시리라 봅니다...ㅎㅎㅎㅎ
대충 이런 원리로 제작이 된다고 생각하시면 될 겁니다.
첨부파일로는 0809 ADC 컨버터 칩의 데이터 시트를 올려놓았습니다.
코딩은 이렇게 하는 겁니다...
--------------------------------------------------
ADC
- ADC0808 ADC로는 축차비교형인 ADC0808/0809를 사용하여 본다.
--@-- +5V | ------------------ | 11 | | Vcc | MSB AI0 -->>--| 26 21 |-->>-- D7 AI1 -->>--| 27 20 |-->>-- D6 AI2 -->>--| 28 19 |-->>-- D5 AI3 -->>--| 1 18 |-->>-- D4 AI4 -->>--| 2 8 |-->>-- D3 AI5 -->>--| 3 15 |-->>-- D2 AI6 -->>--| 4 14 |-->>-- D1 AI7 -->>--| 5 17 |-->>-- D0 | | Adr A0 -->>--| 25 6 |--<<-- Start Adr A1 -->>--| 24 9 |--<<-- Output Enable Adr A2 -->>--| 23 7 |-->>-- End of Conversion | | Adr -->>--| 22 10 |--<<-- Clock Enable | 12 |--<<-- Ref+ | GND 16 |--<<-- Ref- | 13 | ------------------ | @ - 사용 방법
- Clock은 외부에서 TTL 신호(최대 8 kHz)를 연결한다. Ref+ = 5 V. Ref- = 0을 연결한다.
- Adr Enable, Output Enable, Start를 0으로 한다.
- Adr A0, A1, A2는 8 개의 입력 channel을 선택하기 위한 것이다. 선택한 AIx에 analog 신호 (0 ~ 5 V)를 연결한다.
- Adr Enable울 1로 하고, Start를 1 로 하였다가 0으로 바꾼다.
- EoC가 1이 되면 Output Enable을 1로 한다.
ADC0808를 가동시키기 위하여는 Adr A0, Adr A1, Adr A2, Adr Enable, Start 및 Output Enable의 5 출력이 필요하다. parallel port의 DATA (8 outputs)를 이용하면 된다.
입력은 data 8 bits와 EoC으로 9 개가 필요하다. 따라서 STATUS 4~7을 data nibble로, CONTROL 3을 nibble select(출력)로 하고 STATUS 3을 EoC으로 연결하면 된다.
Adr A0 |----<---------------------- D0 Adr A1 |----<---------------------- D1 Adr A2 |----<---------------------- D2 Adr Enable |----<---------------------- D4 Start |----<---------------------- D5 Output Enable |----<---------------------- D6 | EoC |------------------------>-- S3 (15) | | --------------- LSB D0 |-----| I1d S |--<-- /C3 (17) D1 |-----| I1c | D2 |-----| I1b | D3 |-----| I1a Qd |-->-- S4 (13) D4 |-----| I0d Qc |-->-- S5 (12) D5 |-----| I0c Qb |-->-- S6 (10) D6 |-----| I0b Qa |-->-- /S7 (11) MSB D7 |-----| I0a | ----------- --------------- ADC0808 74LS157 Parallel port - program 예제
PDATA% = &H378: REM &H278 or &H3BC PSTATUS% = PDATA% + 1 PCONTROL% = PDATA% + 2 AdrEn% = &H10 Start% = &H20 OutEn% = &H40 ADCCh% = 0 : 'ADC channel selection DBYTE% = 0 + ADCCh% OUT(PDATA%, DByte%) : 'Adr Enable, Output Enable, Start를 0으로 한다. DBYTE% = AdrEn% + Start% + ADCCh% OUT(PDATA%, DByte%) : 'Adr Enable, Start를 1 로 한다. DBYTE% = AdrEn% + Start% + ADCCh% OUT(PDATA%, DByte%) : 'Start를 0으로 한다. EoC% = 0 WHILE (EoC% = 0) : 'EoC = 1이 되기를 기다린다. DBYTE% = INP(PSTATUS%) DBYTE% = DBYTE% AND &H08 EoC% = DBYTE% \ 8 WEND DBYTE% = AdrEn% + OutEn% + ADCCh% OUT(PDATA%, DBYTE%) : 'EoC가 1이 되면 Output Enable을 1로 한다. OUT (PCONTROL%, &H08) : 'data의 low nibble 선택 LD% = INP (PSTATUS%) : 'low nibble을 읽는다. LD% = (LD% XOR &H80) \ 16 OUT (PCONTROL%, &H00) : 'data의 high nibble 선택 MD% = INP (PSTATUS%) : 'high nibble을 읽는다. MD% = (MD% XOR &H80) \ 16 DD% = MD% * 16 + LD% : 'byte로 바꾼다.
하드웨어 개발자의 종착역은 결국, 디바이스 드라이버가 됩니다.
처음엔 땜질을 하면서 이것저것 배우게 되고,
그 다음에는 기본적인 MCU를 배우게 됩니다.
이때 인터럽트라는 개념에서 한 번 뱅글뱅글 돌게 되지요.
그러다가 이제는 설정 레지스터 에서 뱅글뱅글 돌게 되고요...
이렇게 저렇게 발전 하다보면, OS의 필요성을 절실히 느끼게 됩니다.
그만큼 성장을 해서 관리해야할 자원들이 많아지거든요..
그럼 스 자원 관리를 위해서 OS를 올리게 되는데
일반적으로 TinyOS - RTOS - linux 순으로 올라가게 됩니다.
리눅스를 올리게 되면 커널을 통해서 디바이스를 제어하게 되므로,
결국 리눅스 커널상에서 디바이스 드라이버가 돌아가게 만들어야 합니다.
아래 내용은 그 디바이스 드라이버에 대해서 간단하게나마 개념을 잡아주도록 설명을 해주고 있습니다.^^
디바이스 드라이버
아주 오래 전에는 컴퓨터에 달린 모든 장치에 대해 프로그래머가 모든 장치 제어에 대해 프로그램을 직접 작성해야 했습니다. 이러다 보니 프로그래머나 판매자, 사용자 모두 힘들었습니다. 예를 들어 아무리 좋거나 저렴한 프린터라도 프로그래머가 제어할 방법을 모른다면 사용할 수 없었습니다. 만일 사용자가 특정 제품을 사용하겠다고 고집하면 하는 수 없이 프로그래머는 학습과 코딩 수정이 필요했습니다.
그러나 디바이스 드라이버라는 개념이 생긴 후로는 프로그래머는 자신의 프로그램에 더욱 충실할 수 있었습니다. 즉, 외부 장치에 대해서는 제품을 만든 회사에서 함께 제공되는 드라이버를 이용하면 되기 때문입니다.
거기다가 이 드라이버를 사용하는 방법이 완전히 같지는 않아도 대동소이 하다면 그야말로 프로그래머는 장치에 대한 부담에서 많이 자유로워 질 것입니다.
|
그러나 장치에 따라 디바이스 드라이버도 서로 다릅니다. 만들어진 회사도 다를 수 있습니다. 장치를 쉽게 다룰 수 있도록 디바이스 드라이버까지 만들어서 제공해 준 것 까지는 좋은데, 사용하는 방법이 디바이스 드라이버 마다 매우 다르다면 응용 프로그래머에게는 부담이 매우 클 것입니다. |
|
|
 우리가 흔히 디바이스 드라이버를 설명할 때 그리는 그림입니다. 하드웨어가 있고 그 안에 응용 프로그램이 실행되는데, 응용 프로그램에서 직접 하드웨어를 제어하는 것이 아니라 다비이스 드라이버를 통해 하드웨어를 제어합니다.
우리가 흔히 디바이스 드라이버를 설명할 때 그리는 그림입니다. 하드웨어가 있고 그 안에 응용 프로그램이 실행되는데, 응용 프로그램에서 직접 하드웨어를 제어하는 것이 아니라 다비이스 드라이버를 통해 하드웨어를 제어합니다. 리눅스에서는 모든 장치를 파일을 다루듯이 사용할 수 있다라는 말씀을 많이 들으셨을 것입니다. 리눅스에서는 디바이스 드라이버를 파일처럼 다룰 수 있도록 가상 파일 시스템(Virute File System)을 제공하기 때문에 가능한 것입니다.
리눅스에서는 모든 장치를 파일을 다루듯이 사용할 수 있다라는 말씀을 많이 들으셨을 것입니다. 리눅스에서는 디바이스 드라이버를 파일처럼 다룰 수 있도록 가상 파일 시스템(Virute File System)을 제공하기 때문에 가능한 것입니다. 디바이스 드라이버 사용 예
가상 파일 시스템이라는 내용을 이해해 보도록 하겠습니다. 이전에 시리얼 통신 강좌 시리즈 중에 시리얼 통신 - 통신포트 열기 글에서 디바이스 드라이버에 대해 말씀을 드린 적이 있습니다. 그 중에 일부를 올립니다.
시리얼 포트의 장치명
/dev 디렉토리에 있는 시리얼 포트의 목록을 보면 아래와 같은 내용이 출력됩니다. 도대체 뭔소리인지 하나씩 알아 보겠습니다.
crwxrwxrwx 1 root tty 4 64 Jan 1 2006 ttyS00 crwxrwxrwx 1 root tty 4 65 Jan 1 2006 ttyS01 crwxrwxrwx 1 root tty 4 66 Jan 1 2006 ttyS02 crwxrwxrwx 1 root tty 4 67 Jan 1 2006 ttyS03 (1) 접근 권한을 보면 crwxrwxrwx 로 c로 시작하는 것은 장치가 "문자 장치"임을 알려 줍니다. c 가 아닌 b로 시작한다면 "블록 장치"를 말하는데, 예로 하드디스크와 같이 블럭 단위로 읽거나 쓰기를 하는 장치가 되겠습니다.
(5) 의 4는 메이저 장치 번호, (6)의 64, 65, 66 등은 마이너 장치 번호입니다. 우리가 작성하는 프로그램은 하드웨어 장치를 직접 제어하는 것이 아니라 커널을 통해 제어하게 됩니다. 하드웨어를 파일 개념으로 처리할 수 있는 것도 중간에 커널이 가상 파일을 만들어서 제공하기 때문에 가능 한 것입니다.
프로그램에서 하드웨어 장치에 대해 어떤 작업을 커널에게 요청하면, 커널은 메이저 번호를 가지고 어떤 디바이스 드라이버 사용할 지를 결정하게 됩니다. 디바이스 드라이버는 커널로부터 받은 정보 중 마이너 장치 번호를 가지고 자기에게 할당 된 장치 중 어떤 장치를 제어할 지를 결정하게 됩니다.
위의 장치 목록을 보시면 메이저 번호가 모두 4 로 똑 같습니다. 대신에 마이너 번호만 다르죠. 커널은 메이저 번호로 따라 디바이 드라이버를 선택하고 다음 처리를 넘기면 디바이스 드라이버는 마이너 번호를 가지고 어느 장치를 사용할 지를 결정한다는 얘기가 되겠습니다.
이렇게 하드웨어 장치 제어 흐름을 본다면 ttyS0, ttyS1 과 같은 이름은 별로 중요하지 않죠. 중요한 것은 메이저 장치 번호와 마이너 장치 번호가 되겠습니다.
위 내용을 조금 더 쉽게 이해하기 위해 통신 포트를 open 하는, 즉 통신 포트를 사용하기 위한 프로그램 코드를 보겠습니다.
fd = open( "/dev/ttyS0", O_RDWR | O_NOCTTY | O_NONBLOCK );
통신 포트라는 장치를 사용하기 위해서 /dev/ttyS0를 open했습니다. 그렇다면 /dev/ttyS0 가 디바이스 드라이버일까요? 디바이스 드라이버도 응용프로그램과 장치 사이에서 실행되는 프로그램이라고 생각한다면 /dev 에서 장치 목록을 출력할 때, 주 장치 번호와 부 장치 번호 뿐만 아니라 파일 사이즈도 나와야 할 것입니다. 파일 사이즈도 파이에 대한 중요 정보이니까요.
그리고 만약에 /dev/ttyS0 가 디바이스 드라이버라면 문제가 있습니다. 예로 시리얼포트가 8개가 있다고 한다면,
]$ ls -al | grep ttyS crw-rw---- 1 root uucp 4, 64 7월 3 14:18 ttyS0 crw-rw---- 1 root uucp 4, 65 7월 3 14:18 ttyS1 crw-rw---- 1 root uucp 4, 66 7월 3 2007 ttyS2 crw-rw---- 1 root uucp 4, 67 7월 3 2007 ttyS3 crw-rw---- 1 root uucp 4, 68 7월 3 2007 ttyS4 crw-rw---- 1 root uucp 4, 69 7월 3 2007 ttyS5 crw-rw---- 1 root uucp 4, 70 7월 3 2007 ttyS6 crw-rw---- 1 root uucp 4, 71 7월 3 2007 ttyS7
이렇게 통신 포트별로 이름을 바꾸면서 다비이스 드라이버를 작성해서 올려야 합니다. 포트 번호만 다르고 처리하는 방법은 같은데, 통신 포트 개수만큼 소스를 수정하고 모두 컴파일해서 등록해야 된다면 매우 불편할 것입니다.
insmod
그래서 실제로는 하나의 디바이스 드라이버를 만들어서 커널을 올립니다. 커널을 올릴 때, 다른 디바이스 드라이버와 구별할 수 있도록 번호를 앞 가슴에다 부착하고 커널에 올립니다. 이 번호가 주 장치 번호, 주 번호가 되겠습니다.
insmod user_device_name
이렇게 insmod 명령을 실행하면 user_device_name 디바이스 드라이버 안에 주 번호를 몇 번으로 등록할 지 커널에 요청하는 코드가 들어 있습니다. 즉, user_device_name 디바이스 드라이버를 만들 때부터 프로그래머에 의해 주 장치 번호가 경정됩니다. 커널은 디바이스 드라이버에서 요청하는 장치 번호로 user_device_name 디바이스 드라이버를 커널 영역으로 로드합니다.
여기 글에서는 user_device_name 가 주 번호를 250을 사용한다고 하겠습니다.
mknod
이제 커널에서는 디바이스 드라이버를 사용할 준비가 되었습니다. 그러나 아직 커널만 알고 밖에서는 아무도 모릅니다. 커널 밖에서도 이 디바이스 드라이버를 사용할 수 있도록 공개해 주어야 하는데, 그냥 공개하기 보다는 응용 프로그램이 접근하기 쉽도록, 또한 같은 장치이면서 내부에 처리하는 번호가 다르다면 하나의 디바이스 드라이버에서 모두 처리할 수 있도록, 결국 응용프로그램에서 쉽게 사용할 수 있도록 가상 파일 시스템으로 제공해 줍니다.
그것이 바로 /dev/장치명이 되겠습니다.
]# mknod /dev/user_device_S0 c 250 0
]# mknod /dev/user_device_S1 c 250 1
]# mknod /dev/user_device_S2 c 250 2
]# mknod /dev/user_device_S3 c 250 3
]# mknod /dev/user_device_S4 c 250 4
/dev 안에 있는 아이템을 계속 장치명이라고 말씀드렸습니다만 정확한 명칭이 node 라고 하더군요. 그래서 명령어 이름이 mknod 인것으로 생각됩니다.
응용프로램과 커널 그리고 디바이스 드라이버
자, 이제 응용프로그램에서 다시 보겠습니다.
fd = open( "/dev/ttyS0", O_RDWR | O_NOCTTY | O_NONBLOCK );
프로그램에서는 /dev/ttyS0 만 언급햇습니다. 실제 디바이스 드라이브 파일 명이 아닙니다. 이 프로그램 코드는 당연히 커널로 전송되어지고 커널에게 부탁하게 됩니다. 커널은 /dev/ttyS0에서 주 장치 번호를 확인합니다. 또한 주 장치를 보고 커널에 등록된 디바이스 드라이버중에 장치 번호에 해당하는 디바이스 드라이버를 찾아서 응용 프로그램의 open()에 대한 명령을 전송해 줍니다. 이때, 함께 전송되는 것이 /dev/ttyS0에 해당하는 부 장치 번호입니다.
디바이스 드라이버는 커널로부터 받은 부 장치 번호를 가지고 자신이 처리하는 여러 장치 중 어느 장치를 처리할 지를 파단하게 됩니다.
|
(1) |
(2) |
(3) |
(4) |
(5) |
(6) |
(7) |
(8) |
(9) |
(10) |
| crwxrwxrwx | 1 | root | tty | 4 | 64 | Jan | 1 | 2006 | ttyS0 |
| crwxrwxrwx | 1 | root | tty | 4 | 65 | Jan | 1 | 2006 | ttyS1 |
| crwxrwxrwx | 1 | root | tty | 4 | 66 | Jan | 1 | 2006 | ttyS2 |
| crwxrwxrwx | 1 | root | tty | 4 | 67 | Jan | 1 | 2006 | ttyS3 |
즉, /dev/ttyS0 장치를 사용한다면,
- 커널은 /dev/ttyS0 의 주 장치 번호 4번에 해당하는 디바이스 드라이버를 찾고
- 디바이스 드라이버에 부 장치 번호 64를 전송해 주면,
- 디바이스 드라이버는 자기가 처리하는 여러 통신 포트 중에 부 장치 번호인 64로 처리할 포트를 알게 됩니다.
안녕하세요. 박진영입니다.
제가 올린 글들을 주욱 보았는데,,하드웨어를 잘 모르시는 분들이 보시면 일관성이 없어보일듯 하여서,
제가 올리고 있는 글들에 대해서 설명을 잠시 할까 합니다.
우선 제가 하고 있는 블로그의 중점은 오실로스코프 만들기 입니다.
- 제가 하고 있는 프로젝트이죠.^^
그에 대해서 필요한 하드웨어와 기본적인 이론 지식들을 정리하고 있는 것 입니다.
우선 ARM 이라는 코어를 활용해서 그래픽 쪽을 담당하게 됩니다.
그리고 FPGA를 이용해서 필요한 신호의 측정 연산을 하게 됩니다.
하지만 FPGA 쪽을 담당하는 분이 계셔서 저는 FPGA를 제외한 부분의 배경지식들을 알려드리려고 합니다.
그럼 제가 올리려는 분야의 크게 본다면,
1. 오실로 스코프의 기능
2. 오실로 스코프의 제작시 필요한 이론들
3. ARM을 제어하기 위한 기본적인 지식
4. ARM을 이용한 개발보드 EZ-S2410의 지식들이 되겠습니다.
- 2410을 이용한 디바이스 드라이버 작성
오늘은 저번 시간에 이어서 ARM 내용을 말씀드리려고 합니다.
그 중에서도 크로스 컴파일러에 대하여 소개해 드립니다.
----------------------------------------------------------
우선, 크로스 컴파일러의 개념에 대해서 네이버 사전을 찾아봅시다.
| 본문 |
| 원시 프로그램의 번역이 이루어지는 컴퓨터와 번역된 기계어에 이용되는 컴퓨터가 서로 다른 기종의 컴퓨터일 때 사용하는 컴파일러의 한 가지. 어떤 컴퓨터에서 동작하는 프로그램을 만들기 위해 다른 컴퓨터의 개발 환경을 사용해서 프로그램을 작성하는 경우에 사용된다. 동작 속도가 느린 컴퓨터, 완성되어 있지 않은 컴퓨터, 개발 환경 구축이 불가능한 컴퓨터용의 실행 프로그램을 만드는 경우 등에 사용한다. 예를 들면, 마이크로프로세서의 프로그램 개발 또는 게임기의 프로그램 개발은 이와 같은 방법을 채택하는 경우가 많다. |
역시 이것은 FALINUX 회사에서 알려주는 크로스 컴파일러의 개요 입니다.
--------------------------------------------------------------------------------------------일반적으로 컴파일러는 자신의 실행되고 있는 시스템에서 실행되는 바이너리코드를 만듭니다. 예를 들어 x86의 시스템에서 gcc를 사용하여 컴파일하면 x86에서 실행되는 실행 바이너리 파일이 생성됩니다. 이렇게 자신이 실행되고 있는 시스템에 실행할 수 있는 실행 파일을 만드는 컴파일러를 네이티브 컴파일러라고 합니다.
역시 임베디드 리눅스가 설치된 장치에서 실행되는 프로그램을 만들기 위해서는 임베디드 리눅스용 네이티브 컴파일러가 필요합니다. 그러나 임베디스 시스템은 열악한 환경을 위해 만들어진 시스템이기 때문에 프로젝트 소스를 에디트하면서 네이티브 컴파일러를 운영하기 위한 리소스가 매우 부족한 경우가 많습니다.
그러므로 임베디드 보드에서 직접 프로그램을 작성하기 보다는 개발 작업이 용이한 일반 PC를 개발용 호스트로 운영하면서 프로그램 소스 작성 뿐만 아니라 임베디드 리눅스 보드. 즉, 타겟 보드에서 실행되는 실행파일을 만들어 주는 컴파일러를 사용하여 프로그램을 생성합니다.
이렇게 자신이 실행되고 있는 환경과는 전혀 다른 환경에서 실행되는 프로그램을 만들어 주는 컴파일러는 크로스 컴파일러라고 합니다. 또한 크로스 컴파일러는 타겟보드의 CPU에 따라서 다양한 컴파일러가 있습니다.
크로스 컴파일 환경에 포함되는 내용은 아래와 같습니다.
- 어셈블러 및 로더 기타 툴
binutils- 컴파일러
gcc- 크로스 컴파일 구축을 위한 라이브러리 및 일반 라이브러리
- glibc
크로스 컴파일러란 리려는 대상의 칩에 따라서 PC의 프로그램(컴파일러)이 달라진다는 정도로 이해하셔도 도움이 되실 듯 합니다.
밑에서 부터는 제가 사용하고 있는 개발보드의 크로스 컴파일러 설치 과정입니다.
사실 크로스 컴파일러의 설치는 어렵지 않습니다.
AVR128 같은 경우에는 위도우에서 AVR-studio를 설치하는 것으로 끝입니다.
ARM7TDMI기반의 AT91SAM7S시리즈의 경우에는 ADS프로그램과 SAM-BA프로그램을 까는 것 정도로 크로스컴파일러를 포함한 개발환경을 모두 구축할 수 있게 됩니다.
하지만 제가 사용하는 개발보드의 경우에는 FALINUX라는 회사에서 ARM에다가 커널을 올려놓아버렸기 때문에,,,^^
ARM기반의 리눅스에 맞는 방식으로 컴파일을 해줘야 합니다.
그래서 PC에 리눅스를 깔고 ,gcc를 깔고,, 그외 기타 부수적인 것들을 설치하게 되는데,,,,,,
이걸 통째로 묶음으로 회사에서 제공을 하게 됩니다. 그래서 그걸 깔면 대부분의 작업들이 간편하게 완료됩니다.
--------------------------------------------------------------------------------------------
개발 호스트에 크로스 컴파일러를 설치하기 위해서는 크로스 컴파일러 소스를 구해서 직접 컴파일하여 설치해야 하기 때문에 쉽지 않습니다. 이에 저희 (주)FALINUX는 용이하게 설치할 수 있도록 Tool Chain 압축 파일을 제공하고 있으며, 이 압축 파일을 풀기만 하면 설치가 완료됩니다.
크로스 컴파일러를 아래의 순서에 따라 설치하십시오.
- Tool Chain 압축 파일을 구한다.
- root 권한으로 루트 디렉토리(/)에 압축 풀기를 한다.
- 컴파일러가 제대로 설치되었는지 확인하다.
구매하신 제품 중에 동봉된 CD에서 Tool Chain 파일을 구하실 수 있습니다.
EZ 보드 Tool Chain 압축 파일 EZ-PXA270 cross_compiler/arm-toolchain-3.4.3.tar.gz EZ-AU1200 cross_compiler/mipsel-toolchain-3.4.4.tar.gz EZ-S3C2440 cross_compiler/arm-toolchain-3.4.3.tar.gz ESP-MMI cross_compiler/arm-toolchain-3.4.3.tar.gz
EZ-X5 cross_compiler/rpm-wow7.1
cross_compiler/rpm-wow7.3
cross_compiler/rpm-wow8.0
cross_compiler/src
또는 FALINUX 포럼 자료실>>ToolChain 페이지에서 내려 받으실 수 있습니다.
또한 FALINUX 포럼 자료실에는 EZ 보드별로 따로 페이지를 구성해 놓았습니다. 구매하신 EZ 보드의 모델 이름에 해당하는 링크를 클릭하시면 "ToolChain & Ram disk" 리크가 있습니다. 이 링크를 이용하셔도 ToolChain 을 구하실 수 있습니다.
EZ-X5, EZ-S3C2440, 설치 방법은 CD에서 복사한 Tool Chain 압축 파일을 root 권한으로 루트(/)에서 압축을 풀기만 하면 설치가 완료됩니다.
본 설명에서는 제품과 동봉된 CD의 Tool Chain 압축 파일을 이용하여 크로스 컴파일러를 설치하도록 하겠습니다.
]$ su - // 반드시 root 권한으로 작업합니다. 암호: ]# cd / // 반드시 루트 디렉토리로 이동합니다. ]# mount /dev/dcdrom /mnt/cdrom mount: block device /dev/cdrom is write-protected, mounting read-only ]# tar zxvf /mnt/cdrom/cross_compiler/arm-toolchain-3.4.3.tar.gz 리눅스 설치 본에 따라 /mnt/cdrom이 없는 경우가 있습니다. CentOS 같은 경우 /mnt/cdrom 대신에 /media 가 사용됩니다. 그러므로 /media로 마운트합니다. ]# mount /dev/dcdrom /media mount: block device /dev/cdrom is write-protected, mounting read-only ]#tar zxvf /media/cross_compiler/arm-toolchain-3.4.3.tar.gzARM 용 크로스 컴파일러는 arm-linux-gcc 입니다. 컴파일러가 옳바르게 설치되었는지 확인하기 위해 아래와 같이 컴파일러의 버전 번호를 확인해 봅니다.
]# arm-linux-gcc --version arm-linux-gcc (GCC) 3.4.3 Copyright (C) 2004 Free Software Foundation, Inc. This is free software; see the source for copying conditions. There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. ]#이와 같이 컴파이러 버전 정보가 출력되었다면 정상적으로 설치된 것입니다.
설치 방법은 CD에서 복사한 Tool Chain 압축 파일을 root 권한으로 루트(/)에서 압축을 풀기만 하면 설치가 완료됩니다.
본 설명에서는 제품과 동봉된 CD의 Tool Chain 압축 파일을 이용하여 크로스 컴파일러를 설치하도록 하겠습니다.
]$ su - // 반드시 root 권한으로 작업합니다. 암호: ]# cd / // 반드시 루트 디렉토리로 이동합니다. ]# mount /dev/dcdrom /mnt/cdrom mount: block device /dev/cdrom is write-protected, mounting read-only ]# tar zxvf /mnt/cdrom/cross_compiler/mipsel-toolchain-3.4.4.tar.gz 리눅스 설치 본에 따라 /mnt/cdrom이 없는 경우가 있습니다. CentOS 같은 경우 /mnt/cdrom 대신에 /media 가 사용됩니다. 그러므로 /media로 마운트합니다. ]# mount /dev/dcdrom /media mount: block device /dev/cdrom is write-protected, mounting read-only ]#tar zxvf /media/cross_compiler/mipsel-toolchain-3.4.4.tar.gz컴파일러가 옳바르게 설치되었는지 확인하기 위해 아래와 같이 컴파일러의 버전 번호를 확인해 봅니다.
]# mipsel-linux-gcc --version mipsel-linux-gcc (GCC) 3.4.4 Copyright (C) 2004 Free Software Foundation, Inc. This is free software; see the source for copying conditions. There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. ]#이와 같이 컴파이러 버전 정보가 출력되었다면 정상적으로 설치된 것입니다.
실제로 써보게 되면 여기서 알려주는 명령어들을 많이 접하기는 힘들지만,
그래도 배경지식 + 기본 개념 잡는데에는 도움이 많이 됩니다.^^
ARM7강좌입니다.
----------------------------------------------------------------------
ARM7 강좌 [1] : 강좌 소개
----------------------------------------------------------------------
* 강좌 소개
RISC칩 중에 가장 널리 사용되고 있는 것의 하나인 ARM7에 대하여 다루어
보려고 합니다. 부족한 점이 많겠지만, 이 강좌를 통해 ARM7을 공부하시
는 분들에게 조금이나마 도움이 되었으면 하고, 아울러 저 역시 어떤 보
람을 얻을 수 있었으면 합니다.
* 강좌에서 다루고자 하는 내용들
- 개요
- 구조
- 레지스터
- Exception(1)
- Exception(2)
- Instruction Set(1)
- Instruction Set(2)
- Instruction Set(3)
- StrongARM
사실 ARM 아키텍춰의 경우엔 관련 문서가 아주 잘 만들어져 있습니다.
www.arm.com 사이트에 들어가면 해당 문서를 PDF형태로 받아 볼 수 있고
내용도 아주 잘 정리되어 있습니다. 강좌를 통해 어느정도 기본을 익히
고 해당 자료를 찾아 공부하신다면, 빠른 시일내에 ARM을 익힐 수 있으
리라 생각됩니다.
----------------------------------------------------------------------
ARM7 강좌 [2] : 개요
----------------------------------------------------------------------
* ARM7의 특징
ARM의 가장 큰 특징은 전력을 조금만 소모한다는 것입니다. 일설에 의하
면, ARM을 설계할 때, 요즘 CPU를 설계하는 방법처럼 VHDL등을 사용한 것
이 아니라 일일이 회로를 그려가면서 했다는 설도 있습니다. 사실이야 어
떻든, ARM의 저전력 설계기술은 널리 알려진 사실입니다. 이런 이유 때문
에, ARM CPU는 상대적으로 전력이 중요하게 여겨지는 휴대용 단말기에 많
이 채택되고 있습니다.
이제 이런 일반적인 내용 말고, 좀 구체적인 내용으로 들어가 보겠습니
다. 다음은 ARM7의 특징들 입니다.
1. 32 Bit RISC 프로세서
: ARM7은 내부적으로 32Bit의 데이터 버스와 32Bit의 어드레스 버스를
제공합니다. 내부적이란 말은, ARM7이 Core 형태로 여러 종류의 칩
에 탑제되기 때문인데, 어떤 칩은 어드레스 라인을 내부적으로는 32
비트를 사용하고 외부적으로는 메모리 메니지먼트 유닛을 통해 24비
트를 사용하기도 합니다. 그리고 잘 알려져 있듯이 ARM은 대표적인
RISC 코어입니다.
2. Big/Little Endian 모드지원
: 엔디안이라는 것은, 흔히 역워드 방식이라고 말하는 것과 관련이 있
습니다. 인텔 계열의 CPU에서는 메모리에 여러바이트의 내용을 저장
할 때, 하위 바이트가 먼저 오고 상위 바이트일 수록 뒤에 오는데,
이런 형태를 Little Endian이라고 합니다. 또 모토롤라 계열의 CPU
처럼 가장 상위 바이트가 먼저 오는 방식이 Big Endian입니다.
해당 설정은 ARM7이 구현된 칩에 따라 틀리지만, 보통 칩외부에서
핀입력을 받아 결정됩니다.
3. High Performance RISC
: ARM7 의 경우 3V를 사용하고 25MHz의 클럭을 사용할 때 약 17MIPS가
나온다고 합니다.
4. Fast Interrupt Response
: 인터럽트 처리를 빠르게 해 줄수 있는 FAST인터럽트 기능이 있습니
다. 후에 레지스터 부분에서 자세히 다루겠지만, 레지스터 셋을 따
로 제공해서, 인터럽트 처리루틴에서 레지스터를 저장, 복구하는 시
간을 줄이는 방식입니다.
5. Excellent high level language support
: 인스트럭션 셋을 살피면, C나 다른 언어에서 일반적으로 사용하는
기능들을 바로 구현할 수 있는 명령어들이 제공됩니다. 예를 들어
변수의 앞, 뒤에 ++나 --를 붙이는 형식의 오퍼레이션을 제공합니
다.
6. Simple & Powerful Instruction Set
: ARM의 명령어는 그 종류가 적으면서도, 다양하게 적용시킬 수 있는
특징이 있습니다. 이후에 다루게 되면 여러분들도 느끼시겠지만, 배
우기 쉽고, 또 강력한 기능을 제공합니다.
오늘은 ARM7의 전반적인 내용에 대해 간단히 언급했습니다.
사실 ARM을 개인적으로 사용하기는 쉽지 않은 일입니다. 왜냐하면,
ARM을 사용한 칩을 구하기가 쉽지 않기 때문인데요, 최근 CPU인
만큼, 나오더라도 SMD타입으로 나오는 것이 많고 소량으로 구매하
기가 쉽지가 않습니다.
하지만, 여러분들이 회사에서 일을 하게 되면, 사정이 달라 집니다.
ARM은 비교적 저렴하면서도 가격에 비해 좋은 성능을 보이고, 게다
가 저전력 소모라는 강력한 장점을 가지고 있기 때문입니다.
국내 반도체 업계에서도 LG,삼성,현대 등, 모두 ARM 코어를 사용한
칩을 생산하고 있습니다.
그리고, ARM을 사용할 때의 장점중의 하나는, ARM사에서 개발환경
과 도큐먼트 등을 제공한다는 것입니다.
내용은 되도록이면 쉽게 쓰려고 노력했는데, 어땠는지 모르겠군요.
그러면 다음 강좌에서 뵙겠습니다. 다음 강좌에서는 ARM7의 블럭
구조에 대해서 살펴볼 생각입니다.
----------------------------------------------------------------------
ARM7 강좌 [3] : ARM7의 구조
----------------------------------------------------------------------
* ARM7의 구조
1. 레지스터
: ARM7에는 31개의 32Bit 레지스터가 있습니다. 또, 동작모드에 따르는
-여기서 동작모드는 Exception부분에서 자세히 다루겠습니다.- 6개의
Status 레지스터가 있습니다.
2. ALU
: 32Bit 연산이 가능한 ALU가 제공됩니다. 그런데 특이한 것은 ALU의
한쪽 입력은 Barrel Shifter라는것이 연결되어 있어서 ALU의 인수
하나는 레지스터에서 바로 들어오고, 다른 하나는 레지스터나 버스에
서 Barrel Shifter라는 것을 거쳐 입력되도록 되어 있습니다. 이런
이유로 ARM7에서는 제 2 오퍼랜드를 지정할 때, 해당 값을 쉬프트 시
켜서 사용할 수 있습니다. 보통 다른 CPU에서는 쉬프트 명령이 따로
있었는데, ARM7에서는 따로 존재하는 것이 아니라 대부분의 명령에서
옵션으로 적용시킬 수 있습니다.
3. Booth's 곱셈기
: 곱셈 기능을 제공하는 32 비트 Booth's 곱셈기가 있습니다. 곱셈기는
32 비트 연산을 지원하며, 32비트의 두 입력을 받아서 곱하여, 결과
가 32비트를 넘더라도 넘는 부분은 버리고 32비트만을 남깁니다.
이밖에 인스트럭션 디코더와 인크리먼터가 달린 어드레스 레지스터 등이
있고, 내부적으로는 지난번에도 말했듯이 32비트의 어드레스 & 데이터 버
스로 연결됩니다. 또, ARM7은 파이프 라인을 제공하고, 추가적으로 스트
롱 ARM과 같은 칩에서는 캐쉬 기능과 MMU기능등도 제공합니다.
전에 말씀 드렸지만, ARM7은 CPU의 코어를 말합니다. 즉, 특정 칩을 일컽
는 것이 아니기 때문에, 흔히 CPU를 접할 때 다루게 되는 I/O제어나 타이
머, 인터럽트 부분 등은 강좌에서 소개되지 않습니다. 왜냐하면, 같은
ARM7 코어의 CPU라 하더라도 해당 부분들이 각기 다르기 때문입니다.
따라서 여러분들이 ARM7 코어를 사용한 칩을 공부하시고자 할 경우엔, 먼
저 이 강좌의 내용인 ARM7 코어에 대한 부분을 공부하고, 다음에 해당 칩
의 데이터시트를 보셔야 합니다.
참고로, 제가 공부했던 칩은 샤프에서 나온 LH77790 이라는 칩과 Strong
ARM 코어를 사용한 인텔의 SA1100 이라는 칩 두가지 입니다.
스트롱 암은 Digital 사에서 ARM7 코어를 라이센스하여 확장한 형태인데,
기본적으로는 거의 유사하고 MMU같은 기능들이 추가가 된 코어입니다.
현재는 Intel이 Digital 로부터 라이센스를 구입하여 생산하고 있고,
SA110 이나 SA1100, SA1111 등의 칩으로 제작되어 판매되고 있습니다.
현재 생각으로는 강좌의 끝부분에 가서 StrongARM 인 SA1100에 대해서도
조금 다루어 볼 생각입니다.
그럼 오늘 강좌는 이만 줄이도록 하겠구요, 다음 강좌에서는 ARM7의 레지
스터에 대한 내용을 다루겠습니다.
----------------------------------------------------------------------
ARM7 강좌 [4] : 레지스터
----------------------------------------------------------------------
* ARM7의 레지스터
지난 강좌에서 ARM7에는 31개의 General Purpose 레지스터와 6개의Status
레지스터가 있다고 말씀드렸습니다. 물론 모두 32비트 레지스터 입니다.
그런데 ARM7의 어셈블러에서 사용하는 범용 레지스터 키워드는 r0 에서
r15 까지 16개 밖에는 되지 않습니다. 즉, 다시 말해서 사용자가 한번에
사용할 수 있는 레지스터는 16개 입니다. 그중에 몇개는 프로그램 카운터
(PC) 나 스택 포인터(SP) 등의 용도로 사용됩니다. 나머지 레지스터는
CPU 동작 모드(Exception)과 관련되어 r0-r15로 리맵핑 되어 사용되는데
이는 다시 설명 드리겠습니다.
1. Special Purpose General Register
윗부분에서 잠시 설명드렸지만, 유저가 프로그램 할때 레지스터 지정을
위해 사용할 수 있는 키워드는 r0에서 r15 까지 입니다. 그중에 몇 가지
는 특별한 목적을 위해 사용됩니다.
- Program Counter (r15)
: r15는 다른 CPU에서 PC와 같은 역할을 합니다. 다만 차이가 있다면
r15를 일반 다른 레지스터처럼 오퍼랜드로 사용할 수 있다는 점이고
(다른 CPU도 마찬가지 인가요?) ARM어셈블러에서는 pc라는 키워드와
r15를 동일하게 취급합니다.
- Stack Pointer (r13)
: ARM7에는 Stack을 위한 명령어가 따로 없습니다. 즉, Push 나 Pop등
의 명령어가 제공되지 않습니다. 그러나 sp라는 키워드를 사용하여
r13을 쓸 수 있는데, 묵시적으로 r13을 스택포인터로 사용할 수 있도
록 정해 놓은 듯 합니다. 그러면 왜 하필이면 r0 나 r1 이 아니고
r13을 sp라고 칭하느냐면, 역시 Exception 과 관련된 부분이므로 잠
시 후에(혹은 다음강좌에) 설명하도록 하지요. 그리고, Push 명령이
나 Pop 명령이 없으므로, ARM7에서는 같은 기능을 일반 데이터 전송
명령을 통해 해결 합니다. ARM7의 데이터 전송명령은 Auto Increment
기능이 있어서 하나의 인스트럭션으로 Push나 Pop과 동일한 기능을
수행 할 수 있습니다.
- Link Register (r14)
: r14는 링크 레지스터라고 부릅니다. 이 레지스터는 8086 등 에서는
보지 못했던 기능의 레지스터 입니다. 8086등의 프로세서는 서브루틴
을 호출할 경우 CALL을 사용하면 다음에 수행될 프로그램 카운터를
스택에 넣고, 호출될 번지를 프로그램 카운터에 넣는 동작을 하는데,
ARM7에서는 CALL과 RET와 같은 명령이 없습니다. 대신 Branch with
Link 라는 명령(BL) 이 있는데, 해당 명령을 수행하면, CALL과 비슷
하게 다음에 수행될 pc(r15)값을 스택이 아니라 lr(r14)에 넣고 분기
번지를 pc(r15)에 넣어 분기합니다. 즉, 스택을 사용하지 않는 것이
지요. 복귀할 때는 RET대신 mov pc,lr 이라는 데이터 전송명령으로
복귀합니다.
이런 방식은 나름대로 장단점이 있습니다. 우선 단점을 말하자면, 어
떤 서브루틴이 콜 되었을 때, 서브루틴에서는 복귀번지가 r14에 들어
있는 상태가 됩니다. 문제는 해당 서브루틴에서 다시한번 다른 서브
루틴을 콜 한다면, 원래 r14에 보관되어 있던 복귀 번지값이 덮어씌
워지는 결과가 생깁니다. 이런 경우엔, 수동으로 sp(r13)를 이용하여
스택에 r14 값을 보관해 두어야 합니다. 즉, Call하기 전에 r14를 스
택에 보관해 두고, 리턴해서 복구하는 과정을 거치는 셈이지요.
그러면 구태여 왜 이런 방법을 사용할까요. 이미 눈치채신 분들도 계
시겠지만, 그렇게 Call을 연속적으로 하는 경우가 아닌, 한번만 Call
하는 경우라면, 스택을 사용하지 않고 레지스터를 사용함으로써, 그
속도에서 이익을 얻게 되는 것이죠.
개인적으로는 기능이야 어떻든, Call과 Ret 마저 없어서 코드를 읽기
가 상당이 좋지 않다는 생각입니다. 코드를 보고 어디서 어디까지가
한 프로시져 인지 쉽게 분간이 안갈 경우가 많거든요.
2. ARM7 Status Register
이제 스테이터스 레지스터를 살펴보려고 합니다. ARM7에는 32비트의 스테
이터스 레지스터가 6개가 있습니다. 그러나 6개 모두를 한꺼번에 사용하
지는 못하고, 또 그럴 필요도 없죠. 일단은 하나의 32비트 Status 레지스
터만 생각하면 됩니다.
스테이터스 레지스터는 PSR이라고 부릅니다. 그리고 일반적으로 CPSR이라
고 하여 Current Processor Status Register 로 부릅니다.
PSR은 크게 Flag Bits부분과 Control Bits부분으로 나뉩니다.
- Flag Bits
: 어떤 인스트럭션의 결과 등을 나타내는 부분으로 4 비트가 있습니다.
다른 CPU의 그것과 유사한데, 각각 N, Z, C, V 의 4가지 입니다.
1) Negative/Less Than Flag
: N 으로 표기되는 이 플래그는 연산의 결과가 마이너스인 경우에
세트됩니다.
2) Zero Flag
: Z 으로 표기되는 이 플래그는 연산의 결과가 0이 되었을 경우에
세트됩니다.
3) Carry/Borrow/Extend Flag
: C 로 표기되는 이 플래그는 자리올림이나 내림이 발생한 경우,
그리고 Shift 연산 등에서 사용됩니다.
4) Overflow Flag
: V 로 표기되는 이 플래그는 연산의 결과가 오버플로우 되었을
경우 사용됩니다.
이상의 Flag Bit들은 다른 칩의 상태 레지스터와 다르지 않습니다.
따라서 이해를 하는데에도 별 무리가 없으리라 생각되며, 더 자세히
알고 싶으시다면, 각 명령어와 관련된 문서를 참조하시길 바랍니다.
- Control Bits
: 컨트롤 비트들은 인터럽트를 제어하는 비트와 계속해서 언급되기만
하고 실체를 드러내지 않고 있는 Exception 과 관련된 CPU 동작모드
를 설정하거나 확인할 수 있는 기능을 가진 Bit 가 있습니다.
1) IRQ / FIQ Disable Bit
: ARM7의 인터럽트중에서 IRQ와 FIQ 를 금지시킬 수 있는 플래그
입니다. 인터럽트의 종류는 이밖에도 몇가지가 더 있는데, 그중
에서 IRQ, FIQ는 PSR을 통해 금지시키거나 가능하도록 설정할
수 있습니다.
2) Mode Bits
: M0 에서 M4까지의 모드 비트는 CPU의 6개의 동작 상태를 나타냅
니다. 즉, 간단히만 말하자면 ARM7은 6개의 동작 모드를 가지는
데, 이를테면 유저모드와 인터럽트 모드 등 입니다. 역시 자세
한 내용은 다음 강좌를 통해 말씀드리겠습니다.
이제 스테이터스 레지스터를 한번 그려보겠습니다.
------------------------------------------------------------------
| N | Z | C | V | ... | I | F | | M4 | M3 | M2 | M1 | M0 |
------------------------------------------------------------------
Bit 31 30 29 28 7 6 4 3 2 1 0
오늘은 ARM7의 레지스터에 대해 기본적인 내용을 알아보았습니다. 하지만
많은 부분에서 ARM7 의 동작 모드와 관련되는 부분이 나왔지요. 때문에 다
음 시간으로 미룬 부분들이 많군요.
다음 강좌에서는 ARM7 Exception 에 대해서 다루려고 합니다. 오늘은 이만
줄이겠습니다.
----------------------------------------------------------------------
ARM7 강좌 [5] : Exception(1)
----------------------------------------------------------------------
* Exception
우선 Exception이 무엇을 말하는지부터 정리해 보고자 합니다. 일반적으
는 인터럽트와 유사한 개념으로 사용합니다. 어떻게 보면 인터럽트 보다
는 조금 큰 개념이랄 수도 있고, 정확한 정의에 대해서는 말씀을 드리지
못하겠군요. 개념을 ARM7에서의 Exception으로 한정해서 말씀드리겠습니
다.
구체적으로 ARM7에는 FIQ(Fast Interrupt reQuest)와 IRQ(Interrupt reQu-
est), Abort, Software Interrupt, Undefined Instruction Trap 의 5가지
Exception이 있고, 각각 Exception이 발생하면 CPU는 대응하는 동작모드
로 전환됩니다. 여기에 보통 동작상태인 User 동작모드가 추가되어 동작
모드는 총 6개가 있습니다.
- IRQ
: 일반적으로 I/O 장치로부터의 입력이 들어오면 반응을 하는 흔히 말
하는 인터럽트 Exception입니다. IRQ의 종류로는 내부 타이머나 시리
얼, 혹은 외부 IRQ입력 등이 될 수 있습니다.
- FIQ
: 개념적으로는 IRQ와 거의 유사한데, 다만 보다 빠른 처리를 할 수 있
도록 제공되는 Exception입니다. IRQ의 소스는 대부분 FIQ로도 맴핑
될 수 있습니다. 즉, 타이머 인터럽트를 IRQ로 처리하거나, 혹은
FIQ로 처리할 수도 있다는 의미입니다.
- Abort
: CPU가 메모리로부터 인스트럭션을 가져오거나, 혹은 인스트럭션을 동
작시키면서 데이터를 가져오려고 할 경우, 해당 메모리를 억세스 할
수 없다면 Abort Exception이 발생합니다. 위에 제시한 두가지 경우
에 대응하여 Prefetch Abort와 Data Abort로 구분할 수 있습니다.
- Software Interrupt
: 프로그램에서 임의로 인터럽트를 호출하는 경우입니다. ARM 인스트럭
션 SWI 가 이에 해당합니다. 이 Exception이 발생하면 CPU동작모드가
Supervisor 모드로 바뀌도록 되어 있고, 보통 OS의 시스템 Call을 구
현하기 위해 사용됩니다.
- Undefined Instruction Trap
: ARM7 에 정의되어 있지 않은 명령어를 만났을 경우 발생하는 Except-
ion입니다. 이 기능은 코프로세서를 사용하는 경우와 관련되어 사용
된다고 합니다.
위에서 언급한 5종류의 Exception에 몇가지를 더하여, 해당 처리를 위해
ARM7은 0번지에 벡터 테이블을 유지합니다. 즉, 해당 Exception이 발생하
면 정해져 있는 벡터 번지로 실행을 옮깁니다. 해당 번지는 다음과 같습
니다.
Address Exception Mode on entry
-----------------------------------------------------
0x0000.0000 Reset Supervisor
0x0000.0004 Undefined Instruction Undefined
0x0000.0008 Software Interrupt Supervisor
0x0000.000C Abort(prefetch) Abort
0x0000.0010 Abort(data) Abort
0x0000.0014 --reserved-- --
0x0000.0018 IRQ IRQ
0x0000.001C FIQ FIQ
한가지 주의할 점은 8086의 경우엔 해당 벡터에 ADDRESS를 넣어 두면, 인
터럽트 발생시에 해당 주소를 가져다가 PC에 넣어주는 일이 발생하지만,
ARM7의 경우엔 그냥 해당 벡터로 점프를 합니다. 예를 들어 IRQ가 발생했
다면 다음순간의 pc(r15)값은 0000.0018 이 됩니다. 따라서 해당 벡터 번
지에는 단순히 번지가 들어가는것이 아니라 점프명령 같은것이 들어갑니
다.
* 동작모드
위의 Exception과 관련되어 CPU의 동작모드 몇 가지가 나타나 있습니다.
전에도 몇번 말했듯이 ARM7에는 6가지의 동작 모드가 있습니다. 해당 모
드는 User Mode, FIQ Mode, IRQ Mode, Supervisor Mode, Abort Mode,
Undefined Mode 등의 6가지 입니다.
- 동작모드와 범용 레지스터
동작모드가 왜 있는걸까요? ARM7은 각 동작모드에 따라서 몇가지 기능
을 제공합니다. 가장 큰 것으로 레지스터를 리맵핑시키는 기능이 있습
니다. 좀 다르게 설명하면, 각 모드마다 전용 레지스터가 따로 있다고
도 표현할 수 있겠는데요, 차근차근 설명해 보도록 하겠습니다.
CPU의 동작모드는 보통때는 User 모드 입니다. 이 때는 기본적으로 r0
에서 r15 까지를 사용하고 있겠죠. 그러다 가령 FIQ가 발생했다고 치면
동작 모드가 FIQ 모드로 바뀌게 됩니다. 이와 동시에 r8 부터 r14 까지
의 7개의 레지스터는 FIQ 전용 레지스터로 리맵핑 됩니다. 즉, User모
드의 레지스터와는 별개였던 레지스터 7개가 r8부터 r14까지의 위치에
배치되는 것이죠. 물론 기존의 User모드에서 사용하던 r8-r14까지의 레
지스터와는 별개의 레지스터 입니다.
이렇게 하는 장점을 생각해 보겠습니다. 흔히 인터럽트 처리루틴을 작
성할 경우 인터럽트 발생시 가장먼저 하는일이 사용중이던 레지스터를
스택에 저장하고, 또 처리루틴이 종료될 때는 다시 복구시키는 일이었
습니다. 그러나 ARM7에서 FIQ의 경우를 살피면, FIQ 처리 루틴의 코딩
시에는 r8부터 r14까지를 자유롭게 사용할 수 있고, 또 저장과 복구과
정을 생략해도 좋습니다. CPU모드가 바뀜에 따라 레지스터 자체가 별개
의 다른 것으로 바뀌었기 때문입니다.
해당 내용을 정리해 보도록 하겠습니다.
-----------------------------------------------------
User FIQ Super Abort IRQ Undefined
-----------------------------------------------------
r0 . . . . .
r1 . . . . .
r2 . . . . .
r3 . . . . .
r4 . . . . .
r5 . . . . .
r6 . . . . .
r7 . . . . .
r8 r8_fiq . . . .
r9 r9_fiq . . . .
r10 r10_fiq . . . .
r11 r11_fiq . . . .
r12 r12_fiq . . . .
r13 r13_fiq r13_svc r13_abt r13_irq r13_und
r14 r14_fiq r14_svc r14_abt r14_irq r14_und
r15(PC) . . . . .
-----------------------------------------------------
위의 그림이 각 모드에 따라 리맵핑 되는 레지스터들을 나타낸 그림입
니다. FIQ모드에서는 7개, 그리고 나머지 모드에서는 2개씩의 레지스터
가 리맵핑됩니다.
이 개념이 이해하기가 좀 어려울런지도 모르겠군요. 시간을 가지고 차
근 차근 생각해 보시길 바랍니다.
그러면 왜 다른 모드들에서는 r13과 r14를 따로 두었을까요? 그것은 그
레지스터들이 특별한 목적을 위해 사용되는 레지스터 이기 때문입니다.
레지스터차원에서 이번에는 IRQ가 발생한 경우를 가지고 설명해 보겠습
니다.
r14는 Link 레지스터로써 Call과 같은 인스트럭션이 발생할 경우 복귀
할 번지를 저장해 두는 레지스터 입니다. 다음은 IRQ 발생 과정입니다.
1) User모드에서 r0-r15를 사용하고 있다.
2) IRQ 발생
3) ARM CPU는 동작모드를 IRQ 모드로 바꾼다.
( 이때 r13과 r14는 IRQ 전용 레지스터로 대치된다.)
4) 이 시점의 PC 값은 IRQ 처리 이후 복귀할 번지이다. 그 값을
r14 (이미 IRQ모드가 되었으므로 r14_irq ) 에 넣는다.
5) 만약에 r0부터 r12까지를 IRQ처리 루틴에서 사용하고자 한다면
해당 레지스터를 sp(r13, 역시 r13_irq)를 사용하여 스택에 넣
는다.
.....
여기서 5)번 과정을 눈여겨 볼 필요가 있을 듯 합니다. r13이 스택 포인
터로 사용됨은 지난 강좌에서 말씀드렸었습니다. 그런데, 각 모드마다
r13을 따로 가지고 있으므로, 스택을 CPU 동작모드마다 따로 관리할 수
있게 되는 것입니다.
그림이라도 그려서 설명을 드리면 좋을 듯 한데, 텍스트로만 설명하기가
쉬운일이 아니군요.
r14는 복귀번지가 들어가기 때문에 항상 디폴트로 사용되므로 여분의 레
지스터가 필요하겠죠. 그런 이유로 r13과 r14를 각 모드마다 따로 둔 것
입니다. 혹시 이해가 되시나요?
FIQ모드는 그 이름에서도 나타나 있듯이 7개의 레지스터를 따로 두어서
레지스터 저장 복구 과정을 거의 생략할 수 있도록 한 것이죠.
그리고 참고로 Exception에서 복귀할 경우엔 기본적으로는 해당 모드의
r14 번지의 내용을 r15번지로 넣는데, 각 모드마다 조금씩의 차이가 있
습니다.
맨 처음 ARM7 을 소개할 때 범용 레지스터가 31개라고 말씀드렸었는데,
지금 다시 계산을 해보면, User모드의 디폴트 16개 + FIQ 모드 7개 +
나머지 4개의 모드 *2 =8개 해서 16+7+2+2+2+2=31 개로 계산이 됩니다.
- 동작 모드와 PSR(스테이터스 레지스터)
범용레지스터와 비슷하게 PSR 역시 동작모드마다 따로 관리가 됩니다.
해당 레지스터는 뒤에 모드 이름을 붙여서 SPSR_fiq, SPSR_svc,
SPSR_abt, SPSR_irq, SPSR_und 와 같은 이름으로 부릅니다. 따라서 PSR
개수는 CPSR을 포함하여 총 6개가 됩니다.
SPSR은 CPSR값을 저장해 두는 역할을 합니다. 범용레지스터가 아예 맵핑
이 바뀌는데 반해, 모드가 바뀔 경우, 예를 들어 IRQ가 발생했다면, 기
존에 User모드에서 사용하는 CPSR값을 SPSR_irq에 저장을 합니다. 그리
고 IRQ 모드에서는 CPSR과 SPSR_irq를 둘다 볼 수 있습니다. 후에 IRQ가
끝나는 시점에서 SPSR_irq의 내용을 CPSR로 복구하면 원래의 CPSR값이
유지되는 것이죠.
가만히 생각해보면 Exception이 발생했을 때 해당 처리 루틴에는 그순간
의 CPSR값을 그대로 가져오는 셈이지요. 다만 시작할 때 해당 값을 SPSR
에 저장해 두었기 때문에 IRQ 처리루틴에서 수정이 된다고 해도, 복귀할
때 SPSR에서 CPSR값을 다시 가져오므로, 실행중이던 환경은 그대로 유지
가 되는 것입니다.
이렇듯 ARM7에서는 Exception처리에 있어 되도록이면 스택 사용을 최소
화하려는 노력을 엿볼 수 있습니다.
오늘 강좌 내용은 좀 어려웠던것 같습니다. 다른 CPU에는 없는 개념(?)을
설명하느라 그랬던것 같습니다.
더이상 길어지기 전에 오늘은 이만 줄이려 합니다.
다음 강좌에서는 Exception부분에서 좀 더 알아야 할 몇가지 사항을 간단히
언급하도록 하겠습니다.
----------------------------------------------------------------------
ARM7 강좌 [6] : Exception(2)
----------------------------------------------------------------------
* Exception Overview
Exception을 처음부터 완전히 이해 할 필요가 있다고는 생각하지 않습니
다. 대부분의 것들이 그러하듯 우선은 이런게 뭐다 라고 파악만 하고 있
다면, 정작 필요할 경우에 다시 자세히 살펴보아도 좋을 것입니다.
그런 취지에서 Exception을 바라본다면, ARM 7 에는 여섯가지의 CPU 동작
모드를 지원한다는 사실과, 차후 MMU 같은것에도 그 동작모드가 관여한다
는 것. 그리고 각 모드마다 스택을 따로 설정해 준다는 것... 등.
꼭 알아야 할 것이 있다면 IRQ나 FIQ 정도가 되겠지요. 흔히 말하는 인터
럽트 관련 부분이 바로 이 부분입니다. 실제 코딩을 할 경우에는 CPU에서
정해져 있는 IRQ, FIQ관련 레지스터를 설정하고, 해당 벡터 번지를 바꾸
는 정도... 그리고 초기화 시에 해당하는 스택 공간을 따로 잡아주는 정
도만 신경을 쓰면됩니다.
원래는 각 Exception 모드마다 종료방법이 각기 다름을 설명드리려고 했
는데, (구체적으로는 FIQ는 서비스 종료시에 SUBS pc,r14_fiq,#4)라는 명
령을 사용해야 합니다, 혹은 소프트웨어 인터럽트의 경우엔
MOVS pc,r14_svc 를 사용합니다.) 굳이 그런 내용까지 다룰 필요는 없을
듯 하다는 생각입니다. 필요한 경우 도큐먼트를 참조하면 자세히 나와 있
거든요... 참고로 그렇게 각각 경우에 따라 복귀 방법이 다른 이유는 추
측컨데 파이프라인 기능과 관련이 있는것 같습니다.
그러면, 다시 앞으로 돌아가서, Exception과 CPU동작모드의 연관성에 대
해 마저 얘기해 보려 합니다. CPU동작 모드는 일반적으로는 Exception 에
의하여 바뀌게 되고, User모드가 아니라면 프로그램에 의해 강제로 바꿀
수도 있습니다.
전에 살펴보았던 CPSR(스테이터스 레지스터)과 관련되어, CPSR의 모드비
트 부분에 현재 CPU의 동작모드를 나타내는 비트들이 있는데, 해당 비트
를 변경시킴으로서 프로그램에서 동작모드를 전환할 수 있습니다.
OS를 포팅할 경우 동작모드와 관련하여 메모리 보호기능 등도 구현될 수
있습니다.
마지막으로 몇가지 사항만 말씀드리고 오늘 강좌를 마치려 합니다.
우선, Exception간의 우선순위 문제인데, 기본적으로 ARM7은 IRQ, FIQ 를
지원하지 않습니다. 해당 인터럽트가 발생하면 CPU는 CPSR의 인터럽트 금
지 플래그를 설정합니다. 만약 도중에 인터럽트를 받고 싶다면 사용자가
해당 플래그를 클리어 해주어야 합니다. 또, 동시에 여러개의 Exception
이 발생한 경우라면 그 우선순위는 다음과 같습니다.
1) Reset (가장 높은 우선순위)
2) Data abort
3) FIQ
4) IRQ
5) Prefetch abort
6) Undefined Instruction, Software Interrupt
Exception 부분을 설명하다 보니 강좌가 자칫 너무 딱딱해지는 감이 있어
서 그냥 이쯤에서 마무리를 지으려 합니다.
다음 강좌부터는 좀더 구체적인 ARM7의 인스트럭션에 대해 다루겠습니다.
명령어가 몇개 되지 않기 때문에 3회 정도로 다룰 생각이구요.
그럼 다음 강좌에 뵙겠습니다.01C FIQ FIQ
----------------------------------------------------------------------
ARM7 강좌 [7] : Instruction Set(1)
----------------------------------------------------------------------
* ARM7 인스터럭션의 특징
AMR7은 32 Bit 코어입니다. 특징적인 것은 모든 명령어가 32Bit 하나의
Word로 구성된다는 것입니다. 8086의 경우엔 명령어에 따라 1바이트 명령
부터 5바이트 까지 있나요? 그런데, ARM7은 모든 명령어를 한 워드로 처
리 합니다. 일단은 명령어의 개수가 몇 안되고, 주소는 상대주소 방식을
사용하며, 심지어는 Immediate 상수값도 32비트 값은 그대로 넣을 수 없
습니다.
무슨 얘기냐면, 만약 r0 에 32비트 상수를 넣고 싶다면, 몇몇 예외를 제
외 하고는 메모리에 미리 넣어두고 해당 메모리를 상대 주소로 참조해서
얻어 와야 한다는 뜻입니다.
역시 장단점이 있겠지만, 장점으로는 모는 명령어를 같은 사이즈로 처리
함에 따라 파이프라인 구현이 용이하다는 점이 있습니다. 그리고 명령어
해석기를 설계할 경우 예외 처리부분이 없으므로, 쉽고 고속으로 처리할
수 있겠지요.
단점은 앞에서도 간단히 언급했지만 코딩시에 몇몇 제한이 따른다는 점입
니다. 상대 주소 지정 방식은, 이때 사용하는 옵셋이 24+2=26 비트 이므
로, 상대주소라고는 하지만 거의 불편이 없고, 다만 Immediate 오퍼랜드
를 지정할 경우에 좀 번거롭다는 점이 있습니다. 그러나 8비트의 해상도
를 가지는 오퍼랜드라면 한 워드 내에서 처리 가능합니다. 자세한 내용은
다시 말씀드리겠습니다.
ARM 인스터럭션의 다른 특징으로는 모든 명렁어를 조건적으로 실행시킬
수 있다는 것입니다. 저의 경우엔 이부분에서 대단히 감명을 받았는데요
예를 들어, 8086에서는 jz, jc 와 같은 점프 명령을 사용합니다. 그 의미
는 제로 플래그가 설정되어 있으면 점프를 해라, 혹은 캐리 플래그가 설
정되어 있으면 점프를 해라.. 라는 의미임을 아실 것입니다. 그냥 무조건
점프의 경우엔 jmp 를 쓰지요.
ARM의 경우엔 그런 플래그의 사용이 점프명령에 국한되지 않고, 예외 없
이 모든 명령어에 사용할 수 있습니다.
ex) BEQ jmp_1 ; Branch if Z flag set to jmp_1
MOVEQ r0,r1 ; r0 := r1 if Z flag set...
위의 경우를 보시면 jmp에 해당하는 B 명령 뿐만 아니라 MOV 와 같은 데
이터 전송명령에도 플래그 옵션을 사용했음을 볼 수 있습니다. 이런 기능
의 장점은 잠깐만 생각해 보아도 알 수 있습니다. 예를 들어 C 연산자 중
에 ? 연산자를 컴파일 한다고 생각해 봅시다.
ex) a=(b==c) ? d:e;
(편이상 변수를 레지스터로 바꾸어 생각하겠습니다.)
CMPS r2,r3
MOVEQ r1,r4
MOVNE r1,r5
아직 명령어를 안 다루었으므로 대충 의미는 추측해 보십시요. 8086이랑
대충은 비슷하니까 어려운 일은 아닐것입니다. r2와 r3를 비교해서, 그
결과가 같다면 r1에 r4를 넣고, 그렇지 않다면 r1에 r5를 넣는 코드입니
다. 만약 같은 일을 8086등에서 하려면 점프 명령이 한개 이상은 들어가
야 하겠죠.
다시한번 강조하지만 ARM7에서는 이와같은 조건 옵션을 모든(!) 명령어에
사용 가능합니다. 실제로 모든 OP 코드의 상위 4비트는 이런 조건옵션을
나타내는데 사용되는 비트입니다. 각조건에 사용되는 접미사 목록입니다.
0 EQ Z Set equal
1 NE Z Clear not equal
2 CS C Set unsigned higher or same
3 CC C Clear unsigned lower
4 MI N Set negative
5 PL M Clear positive or zero
6 VS V Set overflow
7 VC V Clear no overflow
8 HI C Set and Z Clear unsigned higher
9 LS C Clear or Z Set unsigned lower or same
10 GE N Set and V Set or greater or equal
N Clear and V Clear
11 LT N Set and V Clear or less than
N clear and V set
12 GT Z clear and greater than
ether N set and V set or
N Clear and V clear
13 LE Z Set or less than or equal
N set and V clear or
N clear and V set
14 AL always
15 NV never
뒷부분에 가서는 무지 복잡하죠? 저두 치면서 이걸 꼭 쳐야 할 필요가 있
을까 생각을 했습니다만, 이왕 시작한거.. 하면서 다 쳤군요. 자세하고
정확한 내용은 다른 문서를 참조하시길 바라고 여기서는 그냥 이런것들이
있구나 하는 정도만 알아두십시요.
다음으로 말씀드릴 명령어의 특징은 대부분의 명령어에 S 라는 접미사를
사용하여 플래그 레지스터에 영향을 줄지 여부를 결정할 수 있다는 것입
니다. 특히 연산명령을 수행할 때 'S'를 붙이면 해당 결과에 따라서 플래
그 값들이 변하게 되고, 붙이지 않으면 영향을 미치지 않도록 할 수 있습
니다. 8086에서는 연산의 결과에 따라 항상 플래그 값이 영향을 받죠? 여
기서는 받지 않게 할수도 있다는 점을 말씀드렸습니다. 자세한 내용은 명
령어의 세부사항을 참조해야 겠지요.
명령어의 특징을 말씀드리는 중인데, 앞으로도 오퍼랜드 사용 등에 대해
말씀드릴것이 많이 남아있네요... 그런데 분량은 점점 늘어나고...
ARM은 지금 말씀드리는 규칙들이 거의 예외없이 적용됩니다. 명령어가 간
단한 대신 옵션이 많거든요...그리고 지금 그 옵션 두가지를 말씀드렸구
요.
오늘은 그냥 끝내기는 서운하니까 점프 명령 하나만 말씀드리고 마치겠습
니다.
* Branch and Branch with link (B, BL)
--------------------------------------------------------------------
| Cond | 101 | L | |
--------------------------------------------------------------------
Cond 부분은 위에서 말씀드린 조건 옵션이구요, 101은 B 명령 코드입니다
L 부분은 1일 경우 BL 이 되는 것이고 0이면 B 명령입니다. B는 JMP 라고
생각하시면 되고, BL은 CALL로 생각하시면됩니다. 다만 BL의 경우엔 PC값
을 스택에 넣는것이 아니라 r14(lr)에 넣는다는 것이 차이가 있습니다.
나머지 하위 24비트가 Offset으로 사용되는데, ARM7은 모든 명령어들이
Word단위이므로 총 +/- 32메가 바이트 영역을 커버합니다.
좀 어수선한 느낌입니다만.. 오늘은 이만.
----------------------------------------------------------------------
ARM7 강좌 [8] : Instruction Set(2)
----------------------------------------------------------------------
이번 강좌에서는 데이터 프로세싱 명령에 대해 다루려 합니다. 해당 명령은
ARM7 의 50%정도에 해당하는 명령입니다. 실제 개수는 16개이고, 연산명령
과 비교명령, 비트연산명령, 데이터 전송 명령 등이 포함됩니다.
* Data Processing Instruction
데이터 전송명령의 형식은 다음과 같습니다.
----------------------------------------------------------------------
| Cond | 00 | I | OpCode | S | Rn | Rd | Operland 2 |
----------------------------------------------------------------------
4 2 1 4 1 4 4 12
전에 언급했듯이 모든 인스트럭션의 크기는 32 Bit 입니다. 위의 그림에
서 숫자는 해당 필드의 비트 수를 의미합니다.
1) <Cond> [31:28] 4 Bit
해당 명령의 조건 실행 플래그 입니다. 지난 강좌에서 언급했었던
부분인데, 모든 명령어에 포함되므로 데이터 프로세싱 명령에도 포함
됩니다.
혹시나 해서 다시 말씀드리는데, 해당 플래그를 통해 명령을 현재 플
래그 래지스터(CPSR)의 상태에 따라 실행 여부를 결정하는데 사용되는
플래그 입니다.
2) <I> [25] 1 Bit
Operland 2 로 지정되어 있는 부분이 Immediate Operand 인지 아닌지
여부를 나타내는 비트입니다. Immediate Operand라 함은, 예를 들어
8086에서 MOV AX,01234h 라고 했을 경우, 1234h 를 가리키는 말입니다.
자세한 내용은 Operland2를 설명하면서 자세히 다루겠습니다.
3) <OpCode> [24:21] 4 Bit
데이터 프로세싱 명령중 어떤 명령인지를 나타내는 필드입니다. 해당
필드와 명령어는 다음과 같습니다.
<OpCode> Instruction Description
-----------------------------------------------------
0000 AND Rd:=Op1 AND Op2
0001 EOR Rd:=Op1 XOR Op2
0010 SUB Rd:=Op1 - Op2
0011 RSB Rd:=Op2 - Op1
0100 ADD Rd:=Op1 + Op2
0101 ADC Rd:=Op1 + Op2 + C
0110 SBC Rd:=Op1 - Op2 + C - 1
0111 RSC Rd:=Op2 - Op1 + C - 1
1000 TST Op1 AND Op2 -> CPSR
1001 TEQ Op1 XOR Op2 -> CPSR
1010 CMP Op1 - Op2 -> CPSR
1011 CMN Op1 + Op2 -> CPSR
1100 ORR Rd:=Op1 OR Op2
1101 MOV Rd:=Op2
1110 BIC Rd:=Op1 AND (NOT Op2)
1111 MVN Rd:=NOT Op2
명령어들의 간단한 설명만으로도 어느정도는 이해할 수 있으리라 생각
합니다. 각각의 명령에 대해서는 자세히 다루지 않도록 하겠습니다.
나중에 예제를 보시고 이해할 정도라면 족하다고 생각합니다.
4) <S> [20] 1 Bit
S 비트가 1인 경우는 데이터 프로세싱 명령의 결과가 CPSR(플래그레지
스터)에 영향을 미칩니다. 즉, 0인 경우에는 CPSR은 변하지 않습니다.
5) <Rn> [19:16] 4 Bit
ARM 데이터 프로세싱 명령은 그 결과와 첫번째 오퍼랜드는 항상 레지
스터로 지정해야 합니다. Rn은 첫번째 오퍼랜드를 가리키는 것으로
위에서 Op1으로 표기한 것에 해당합니다. ARM에서 한번에 볼 수 있는
범용 레지스터는 sp, lr, pc 등을 포함해서 r0 에서 r15까지라고 말씀
드렸습니다. 즉, 4Bit를 통해 레지스터를 나타내게 됩니다.
해당 필드는 명령에 따라 사용되지 않기도 합니다. MOV나 MVN등이 이
에 해당합니다.
6) <Rd> [15:12] 4 Bit
오퍼레이션의 결과가 저장될 레지스터를 의미합니다. 역시 레지스터를
가리키므로 4비트를 사용하고 모든 명령에서 디폴트로 사용되는 필드
입니다. 말씀드렸듯이 ARM의 데이터 프로세싱 명령의 결과는 항상 레
지스터로 들어갑니다.
7) Operand 2 [11:0] 12 Bit
드디어 오늘의 가장 험난한 산인 Operand 2 필드까지 왔군요... 설명
드려야 할 부분이 좀 많거든요. 어떻게 설명을 드려야 할지, 막막하긴
하지만, 용기를 가지고 차근차근 설명해 보도록 하겠습니다.
* 데이터 프로세싱 명령의 Operand 2 필드
오퍼랜드 2 의 의미 자체는 별게 아닙니다. 아마도 다들 아시겠지만,ALU
에 연산명령을 내릴 경우 한쪽 입력은 오퍼랜드 1, 다른쪽은 오퍼랜드 2
그리고 결과가 나오고... 앞서 설명한 내용에 의거하면 다음과 같이 표현
할 수 있겠죠?
Op1(Rn) Operand 2
-------------- ---------
| | / /
| | / /
| | / /
| /
| ALU /
| /
| /
----------------
Rd
예를 들어 AND r1,r2,r3 라는 명령에서 Rd = r1 이고 Rn=r2 입니다. 그
리고 r3가 Operand2 에 해당하는 부분이 되겠죠. 의미는 r1=r2 & r3 라는
의미입니다.
여기서 설명하고자 하는 ARM7의 데이터 프로세싱 명령의 Operand2의 타입
은 두가지 종류가 있습니다. <I> 필드의 내용에 따라 구분이 되는데,
Immediate Operand 혹은 레지스터 Operand입니다.
1) Register Operand
<I> 필드가 0일 경우엔 Op2가 레지스터임을 의미합니다. 레지스터를
나타내기 위해서는 아시다시피 4비트만 있으면 되죠? 그런데 Op2를 위
한 비트 수는 총 12 비트입니다. 남는 군요...
구체적으로 레지스터 오퍼랜드2의 형식을 보여드리겠습니다.
------------------------------------------------
| Shift [11:4] | Rm [3:0] |
------------------------------------------------
위의 그림을 보시면 Rm이라고 레지스터를 지정하는 4비트가 포함되어
있습니다. 그러면 Shift 부분은 뭘까요?
강좌의 앞부분에서 언급했었나요? 무슨 쉬프터가 ALU의 한쪽에 달려있
다고... 결론적으로는 레지스터를 ALU로 그냥 집어넣는 것이 아니라
Shifter를 통해서 넣어주도록 되어 있습니다. 따라서... Shift라는 필
드는 (8비트죠?) 그런 역할을 해주는 것이겠군요. 그럼 왜 8비트일까
요? 여기서 다시한번 Shift 를 구체적으로 살펴보겠습니다.
우선 그전에 Shift 필드에는 Shift 회수를 지정하는 방법이 두가지가
있는데, 첫째는 Shift 필드안에 그 회수를 포함시키는 방법이고, 두번
째는 Shift 회수가 들어있는 레지스터를 Shift 필드 안에서 지정하는
방법입니다. 경우의 수가 자꾸 늘어 가는 군요... 해당 타입 두가지는
Shift 필드의 최 하위 비트인 4번 비트에 따라 결정됩니다. 다시 그림
을 그려보겠습니다.
--------------------- ---------------------
| count |type | 0 | | Rs | 0 |type | 1 |
--------------------- ---------------------
5 2 1 4 1 2 1
최 하위 비트의 값이 0이냐 1이냐에 따라 두가지로 구분이 되었습니다.
왼쪽의 경우가 직접 Shift 회수를 지정하는 방법으로, count 부분이
총 5 비트로서 그 값을 의미합니다. ARM7의 레지스터는 32비트이므로
5비트는 있어야 Shift 회수를 표현할 수 있겠지요.
그러면 Type은 뭘까요? 2비트인 Type의 의미는 다음과 같습니다.
00 : logical left (LSL)
01 : logical right (LSR)
10 : arithmetic right (ASR)
11 : rotate right (ROR)
그렇군요... 단순히 Shift라고 말씀드렸지만 실제로는 좌, 우, 부호의
여부와 Rotate까지 형식을 지정할 수가 있습니다.
(무지 복잡해지는 듯한 느낌입니다..^^)
오른쪽에 레지스터를 지정하는 방식은, 1비트가 남아서 0으로 처리한
것만 제외하고는 별 문제가 없겠죠?
원래는 여기서 쉬프트 방식 4가지에 대한 설명이 뒤를 이어야 겠지만.
이러다보면 한도 끝도 없을 것 같네요...
2) Immediate Operand
강좌를 정리하려다 생각하니 Immediate Operand를 설명 안했군요. 여기
까지는 해야할 것 같아서.... 쩝.
레지스터 오퍼랜드의 경우 총 12 비트 중에서 4비트는 레지스터를 지정
하고, 나머지 8비트는 해당 레지스터값을 쉬프트하는 방법을 지정하도
록 되어 있었습니다.
Immediate 오퍼랜드는 몇가지 문제가 있습니다. 32비트 레지스터에 값
을 써 넣고 싶은데 공간은 12비트 밖에는 없다는 것이지요. 8086등에서
야 그냥 여러바이트로 명령을 처리했었으니 그런 문제가 없었지만, ARM
에서는 이것 때문에 모든 명령이 32비트라는 규칙을 깰 수는 없었겠지
요. 다음은 구체적인 모양세입니다.
------------------------------------------------------------------
| Rotate [11:8] | Imm [7:0] |
------------------------------------------------------------------
아까랑 비슷한 모양이군요. 이번엔 Rotate 필드(4비트)가 있고, 또 8비
트의 Imm 필드가 있습니다. Imm은 말 그대로 Immediate Value를 넣는
공간입니다. 이 공간이 8비트라서, 결국 ARM7에서 어떤 상수값을 레지스
터로 전송하거나 할 경우 8비트 까지는 아무런 문제가 없이 넣울 수 있
습니다. 그러면 Rotate 필드의 하는 역할은 무었일까요?
좀 복잡한데요... ARM7문서에는 다음과 같이 써 있습니다.
... Immediate Operand rotate 필드는 부호없는 4비트 정수로서 8비트...
... Immediate 값에 Shift 오퍼레이션을 할 수 있도록 사용되는 값이...
... 다. rotate필드 *2 값 많큼 8Bit Immediate Value 값을 Right Ro-...
... tate 시킨다. 결국 8비트 값을 32비트로 확장시키는 역할을 하며...
... 이를 통해 자주 사용되는 많은 상수들을 사용가능하도록 한다.
8비트의 값이 ALU로 들어가기 전에 Shifter로 들어가면, 이미 32비트로
확장이 됩니다. 이후 그 값을 그냥 쓰면 8비트 영역만 표현할 수 있지만
Rotate필드값을 * 2 한만큼 Rotate Right 시킨다 그랬으니, ... 어떤 변
화가 생기겠죠?
오늘 분량이 좀 많았네요... 차근 차근... 담에 또 말씀드리죠.. 뭐.
몇가지 예를 들어 보이면서... 오늘 강좌를 정리할까 합니다.
ADDEQ r2,r4,r5
: 제로 플래그가 설정되어 있다면 r2=r4+r5
SUBS r4,r5,r7,LSR r2
: r4=r5-(r7>>r2) & effect CPSR
----------------------------------------------------------------------
ARM7 강좌 [9] : Instruction Set(3)
----------------------------------------------------------------------
지난번 강좌를 쓰고나서 이것 저것 생각을 해봤는데, 내용이 좀 어렵지 않
았나 싶네요. 인스터럭션의 코드를 가지고 접근하는 방식은 디지털쪽의 기
초지식과 어셈블리에 대한 보편적인 지식을 갖고 접근하는 방법이어서, 혹
그런 기본지식이 없으신 분들에게는 딱딱하고 어렵게 느껴졌을지도 모른다
는 생각을 혼자(?) 했습니다.
강좌에대한 피드백이 없어서... 쩝... 그냥 나름대로 생각하고 쓰고 있는
데요.. 이럴 경우엔 좀 어렵다 라든가... 방향이 틀린것 같다 라는 식의 의
견을 들을 수 있다면 강좌의 방향을 정하는데 도움이 될 것 같다는 생각을
했습니다.
그간 강좌를 보시고 ARM에 관한 몇가지 질문들을 주신 분들이 계신데요....
되도록이면 답변을 해드리려고 노력중이고, 또 그럼으로서 보람도 느낄 수
있는것 같습니다.
제 email 주소는 zartoven@secsm.org 입니다.강좌에 관련된 의견이나 질문
이 있으신 분들은 해당 주소로 질문을 주세요. 제가 어떤 사람인지에 대해
서도 말씀을 못드렸는데, 모 전자회사에서 RTOS 업무를 담당하고 있습니다.
아직까지는 주로 pSOS 관련업무를 하고 있구요... 처음에는 pSOS관련 강좌
를 운영해 볼까 생각도 해 봤지만, 과연 얼마나 많은 분들이 pSOS를 사용하
실런지 의문이 들어서 포기했습니다. 관련해서 제가 알려드릴 부분이 있다
면 아는 한도내에서 최대한 노력해 보겠습니다.
오늘은 안하던 사설을 길게 늘어놓았군요. 아무래도 지난 강좌에 다루었던
내용이 좀 부실했던 것 같아서, 오늘은 좀 다른 접근 방식으로 인스트럭션
에 대한 내용을 다루려고 합니다. 자, 그럼 시작하겠습니다.
오늘 다룰 내용은 주로 "The ARM RISC Chip. A Programmer's Guide"라는 책
의 내용을 위주로 하겠습니다.
1) MOV{cond}{S} Rd,Op2
어셈블리어에서 가장 기본적으로 사용되는 데이터 전송명령입니다. 해당
명령은 8086에서의 MOV, Z80이나 196에서의 에서의 LD 명령과 같은 역할
을 합니다. 다만 차이라면 ARM7에서의 MOV는 그 타겟이 되는 부분이 항
상 레지스터 라는 점입니다.
예를 들어 8086에서는 MOV AX,[BX] 의 형태와 MOV AX,BX 와 같은 명령
의 형태를 같은 MOV명령을 통해 해결합니다만, ARM에서의 MOV는 후자의
것만을 의미합니다. 즉, 레지스터나 Immediate 값 같은 것들을 레제스터
에 넣는 명령입니다.
전자의 경우와 같이 외부 메모리를 억세스하는 명령은 따로 있고, 분류
자체를 다르게 합니다.
제목에 써놓은 것은 MOV명령의 형식인데요. {cond}부분은 지난번 말씀드
렸던 실행 조건을 제한하는 옵션입니다. ARM7에서는 모든 명령어에 해당
옵션을 적용시킬 수 있다고 말씀드렸습니다. 구체적으로는 EQ, NE, 등등
의 2자 짜리 접미사 형태이고, 해당 조건에 맞도록 플래그 레지스터가
설정이 되어 있어야 MOV명령이 수행됩니다.
{S}옵션은 해당 명령의 결과가 플래그 레지스터에 영향을 미칠지 여부를
결정하는 옵션입니다. ARM에서의 MOV는 Data Processing 명령으로 분류
되어 Rd에 들어가는 값에 따라 플래그 레지스터가 영향을 받을 수 있습
니다.
하지만, 특별히 사용되는 경우가 있습니다. 좀 어려울런지 모르겠지만,
타겟 레지스터가 PC인 경우 S 옵션을 사용하면, Exception모드에서 보
통 상태로 빠져 나오는 역할을 하게됩니다. 지금 다루기는 좀 그렇구요
강좌의 마지막쯤 해서 한꺼번에 다시 다루겠습니다. 지금은 그러려니
하시길 바랍니다.
Rd는 타겟이 되는 레지스터 입니다. MOV명령의 타겟은 항상 레지스터이
어야 합니다. 물론 MOV 뿐만이 아니라 Data Processing 명령으로 분류
된 모든 명령들(지난 강좌에서 언급했던)이 다 그렇습니다.
Op2는 MOV명령에 의해 Rd로 들어갈 내용을 가리키는 오퍼랜드입니다.
지난 강좌에서 이것 저것 복잡하게 말씀드렸었는데요, Op2 부분에는 단
순히 레지스터가 들어갈 수도 있고, 어떤 immediate값이 들어갈 수도
있고... 또 Shift 오퍼레이션을 가한 레지스터 내용이 들어갈 수도 있
습니다. 예제를 통해 확인하시길 바랍니다.
Ex1) MOV r0,r1
: 단순히 r0:=r1 을 하는 명령입니다.
Ex2) MOV r0,#0
: r0에 상수 0을 넣는 명령입니다. ARM에서는 196에서와 같이 상
수에는 #을 붙여서 사용합니다. 또 진법 표현은 C 에서의 방법
을 사용합니다. 즉 MOV r0,#0x30 이런식으로 사용할 수도
있습니다. 혹은 &를 붙여서 16진수를 나타낼 수도 있습니다.
Ex3) MOV r0,#0xfc000003
: r0에 상수값 0xfc000003 을 넣는 명령입니다. 지난 강좌에서 말
씀드렸지만 해당 값은 8비트 값 0xFF를 32비트로 확장하고 오른
쪽으로 두번 Rotate 시킨 값입니다. 그래서 에러가 나지 않는
것이지요.
Ex4) MOV r0,r1,LSL #1
: 이 명령은 r0:= r1 <<1 을 수행하는 명령입니다. LSL은 logical
Shift Left 를 의미하는 키워드이고, Op2 부분에 위와 같은 형
식으로 올 수 있습니다.
Ex5) MOV r0,r1,LSR r2
: 이 명령은 r0:=r1 >> r2 에 해당하는 명령이고, LSR은 Logical
Shift Right를 의미합니다.
Ex6) MOV r0,r0,ASR #24
: 이 명령은 r0:=r0 >> 24 를 의미합니다. ASR은 Arithmetic Shi-
ft Right 를 의미하며 LSR과의 차이는 최 상위 비트가 1 인경우
새로 계속 해당 비트값을 유지시킨다는 것입니다.
Ex7) MOVS r0,r1,LSR #1 : C(flag) := r1[0]
MOVCC r0, #10 : if C=0 then r0:=10
MOVCS r0, #11 : if C=1 then r0:=11
Ex8) MOVS r0,r4 : if r4=0 then r0=0
MOVNE r0,#1 : else r0=1
첫번째 명령에서 r4값을 r0로 넣을 때 {S}옵션에 따라서 플래그
레지스터 값이 변화합니다. 다음 명령에서 NE 조건을 사용했기
때문에, 참고로 NE는 Not Equal, Z플래그가 0일 경우입니다., r4
값이 0이었다면 NE는 False가 되어 두번째 명령을 수행하지 않습
니다. 결과적으로는 r0에 0이 들어간 셈이지요. 만약 r4가 0이
아니었다면 두번째 명령이 수행되어서 r0에는 1이 들어갑니다.
오늘 강좌는 이것으로 정리하려 합니다. 다음에 뵙겠습니다.
----------------------------------------------------------------------
ARM7 강좌 [10] : Instruction Set(4)
----------------------------------------------------------------------
오늘 강좌에서는 Data Processing Instruction에 대해서 계속 이어나가도록
하겠습니다. 되도록이면 오늘 이부분을 다 커버하고 싶습니다만 해봐야 겠
지요. 지난 강좌에서 다루었던 내용중 오퍼랜드쪽 부분은 계속 겹치는 내용
이므로 의문이 생기시면 이전 강좌로 돌아가서 확인해 보시길 바랍니다.
1) MVN{cond}{S} Rd,Op2
해당 명령은 Rd:=NOT Operand2 의 의미를 가진 명령입니다. 기존 어셈블
러에서는 볼 수 없었던 낯설은 명령이네요. 기능은 써 있듯이 MOV처럼
값을 넣기는 넣는데 NOT를 해서 넣는 명령입니다. 이런 명령이 왜 있는
지에 대해서는 확실히 모르긴 몰라도, 아마도 ARM7에서 8비트Resolution
Immediate 오퍼랜드만 다룰 수 있기 때문인 듯 합니다. 해당 명령으로
어느정도 기능을 확장한다고 할까요?
바로 예제로 들어가겠습니다.
Ex1) MVN r0,#0 ; r0 := -1
: 사실 MVN의 용도로 위의 경우 밖에는 사용된걸 보지 못했습니다.
만약 MOV r0,#0xFFFFFFFF 이렇게 하면 에러가 발생합니다. 이것
은 누누히 설명드리지만 ARM7의 모든 명령이 32비트 한 워드이고
Immediate 오퍼랜드처리를 8비트 값을 Rotate시키는 방식으로 사
용하기 때문인데, MVN을 사용함으로서 해당 값을 넣을 수 있습니
다.
다른 부분은 MOV와 동일하므로 그다지 이슈가 될 것이 없을 듯 하군요.
2) ADD{cond}{S} Rd, Rn, Op2
ADC{cond}{S} Rd, Rn, Op2
더하기 명령입니다. 8086과 큰 차이는 오퍼랜드를 3개 지정한다는 것입
니다. Rd는 결과가 저장될 레지스터로, Data Processing 명령 모두는 그
결과가 레지스터(Rd)로 들어가야만 합니다. 첫번째 Rd가 결과가 저장 될
레지스터이고, 나머지 두개가 서로 더해질 오퍼랜드입니다. 두개의 오퍼
랜드 중 하나는 또 항상 레지스터여야만 합니다. Op2는 거듭 말씀드리지
만 Shifted Register 혹은 Rotated Immediate Value 중 하나입니다.
ADD와 ADC는 널리 사용되는 대로 더하기, 더하는데 캐리플래그랑 같이
더하기... 정도입니다.
Ex1) ADD r0,r0,#1 ; r0:=r0+1
Ex2) ADD r0,r1,r2 ; r0:=r1+r2
Ex3) ADDS r0,r1,r1, LSL #2 ; r0:=r1*5
: 위의 명령을 보면 ARM 명령어의 강력함을 알 수 있죠? 위 에서
Rd는 r0, Rn은 r1, Op2 부분이 r1,LSL #2 입니다. r1값 더하기
r1을 두번 쉬프트 한 값, 즉 r1*4값이므로 결과적으로는 *5가 되
겠지요... S 옵션이 사용되었으므로 플래그 레지스터에 영향을
미칩니다. 그러면? 위의 1번 2번 예제는 수행하더라도 플래그 레
지스터는 영향을 안받는다는 의미지요.. 사용하기에 따라서 강력
한 역할을 할 수 있을듯 합니다.
Ex4) in C
int addints(int a,int b)
{
int c;
c=a+b;
return c;
}
in ARM7 Assembly
ADD r0,r0,r1 ; r0:=r0+r1
MOV pc,lr ; return
사실 인수 전달에 관련된 코드가 더 들어가겠지만, 코어부분은 대
강 위와 같습니다.
3) SUB{cond}{S} Rd, Rn, Op2
SBC{cond}{S} Rd, Rn, Op2
RSB{cond}{S} Rd, Rn, Op2
RSC{cond}{S} Rd, Rn, Op2
위의 네 명령은 빼기 명령입니다. SUB와 SBC는 그런대로 알만 한데...
R로 시작하는 두개가 더 있네요. R은 감수(?) 와 피감수를 바꾸는 역할
을 합니다. 즉, SUB 명령이 Rd=Rn-Op2 라면 RSC는 Rd=Op2-Rn 입니다.
이런 명령이 왜 필요할 까요? 글세요... 우선 Op2가 Rn에 비해서 상대
적으로 유연성이 좀더 많아서일까요? 어떻든... 개념은 어렵지 않습니
다.
SBC와 RSC는 캐리플래그가 관련되어 있는 명령입니다. 그런데 명령 해
석을 보면 다음과 같이 나와 있네요.
SBC Rd, Rn, Op2 = Rd=Rn-Op2+Carry-1
아마도 8086에서의 캐리와는 좀 다른 모양입니다. 뺄셈을 했을 때 자리
내림이 발생을 하면 캐리가 클리어 되는 구조이군요. 아마도 2의 보수
연산을 하기 때문인듯 합니다. 즉 1을 빼고 싶은 경우 1의 2의 보수를
취해 더해주죠. 해당 값은 FFFFFFFF 이고, 대상이 0이 아니라면 더하기
를 통해 캐리가 발생하겠군요. 근데 원래 하고자 했던것이 뺄셈이었으
니까... 피감수가 0인 경우에 캐리가 발생하지 않았고, 나머지의 경우
에는 모두 캐리가 발생합니다. 기계적 사고방식에는 그게 맞나 봅니다.
어떻든 중요한건 뺄셈 연산을 통해 borrow가 발생한다면 Carry는 0이고
발생하지 않는다면 Carry는 1이 되는 것이죠. 따라서 SBC와 같은 명령
에서는 Carry를 오히려 더해주고 다시 1을 빼 줌으로써 8086 등에서 사
용되는것과 동일한 효과를 얻게 되는군요.
Ex) 64Bit 뺄셈
SUBS r4,r0,r2
SBC r5,r1,r3
: 이렇게 하면 [r5:r4]=[r1:r0]-[r3:r2] 가 되겠군요.
{S}옵션에 주의하시길 바랍니다.
4) AND{cond}{S} Rd, Rn, Op2
EOR{cond}{S} Rd, Rn, Op2
ORR{cond}{S} Rd, Rn, Op2
: 이번에는 Bit연산에 관련된 명령어들입니다. AND는 그대로 AND,EOR은
XOR쯤으로, ORR은 OR로 생각하시면 됩니다. B 명령을 제외하고는 웬
만한 명령어는 모두 3글자인데, 그래서 ORR로 표기하는 듯합니다. 역
시 오퍼랜드는 같은 의미입니다.
Ex1) AND r0,r0,#0xFF
: r0의 8비트만 남기는 명령입니다.
Ex2) ANDCSS r0,r1,r2,ASR r3
: 만약 캐리 플래그가 설정되어 있다면...(CS) r1 AND (r2>>r3) 정
도를 하는데, 해당 명령의 결과가 플래그 레지스터에 영향을 미
칩니다. ASR과 LSR의 차이는 ASR의 경우 최 상위 비트가 1이라면
해당 비트는 계속 1로 유지를 하는 것이죠.LSR이라면 새로 들어
오는 비트는 항상 0입니다. 이것은 음수를 2의 보수로 사용하는
시스템에서 필요한 방법입니다. 참 결과는 r0에 넣는군요.
Ex3) EORS r0,r0,r0
: 해당 명령을 수행하면 r0는 0이 될 것이고, N 플래그도 0이 되고
Z플래그는 1이 됩니다.
Ex4) MOV r0,#0xFF
ORR r0,r0,#0xFF00
: r0에 0xFFFF를 넣는 방법입니다.
5) BIC{cond}{S} Rd, Rn, Op2
: Rd := Rn AND (NOT Op2) 로 설명이 되어 있는 명령입니다. 별별 명령
이 다 있다는 생각이 드는군요. AND하기전에 NOT을 한번 해서 처리하
는 명령입니다. 의미는 비트를 클리어하는 것이구요, Op2에 지정한
비트가 0으로 지워지는 결과가 나타납니다.
Ex) BIC r0,r1,#3
: r0 := r1 and 0xFFFFFFFC 의 의미입니다.
6) CMP{cond} Rn, Op2
CMN{cond} Rn, Op2
: 비교 명령입니다. MOV, MVN처럼 인수가 2개인데요, 이번에는 Rd가 빠
졌습니다. CMP는 흔히 보던 그 CMP입니다. Rn에서 Op2를 빼 보는 명
령이죠. 아시다시피 레지스터값에는 영향을 미치지 않고 플래그 에만
영향을 미칩니다. 그러고보니 {S}옵션도 없네요... 이 명령들은 디폴
트로 {S}를 준 효과가 나타납니다. (일설에는 어셈블러가 그렇게 해
준다고 그러던데, 기계어 코드로는 S 옵션을 꺼놓은 CMP도 가능하지
않을까 싶네요..)
CMN은 좀 새롭군요. 이 명령은 CMP가 빼기를 하는데 반해, 두 오퍼랜
드를 더해 보는 명령입니다. 역시 생소한 개념인데요... 그럴 필요도
있을까요? 어떻든 CMP가 빼기를 해보는 거라면 CMN은 더하기를 해 보
는 명령어랍니다.
Ex1) CMP r2,#23
MOVEQ r2,#45
: 만약 r2가 23이라면 45를 넣어라...
Ex2) CMP r0,#0
CMPEQ r1,#0
CMPEQ r2,#0
CMPEQ r3,#0
MOVEQ r4,#12
: r0부터 r3까지 모두 0이라면 r4에 12를 넣는 명령입니다. 참 재
미 있는 구조라고 생각됩니다.
Ex3) CMN r1,r2
MOVEQ r0,#0
MVNNE r0,#1
: r0 = ((r1+r2)==0) ? 0:-1;
위에서 조건부 명령의 강력함을 느낄 수 있으신가요? 아니라면 다음을
한번 보시죠...
in C
while (a!=b) {
if (a>b) a-=b;
else b-=a;
}
in ASM with no conditional Instruction
gcd CMP a,b
JZ end
JNZ less_than
SUB a,a,b
JMP gcd
less_than
SUB b,b,a
JMP gcd
end
...
* ARM도 아니고 8086도 아니고... 명령어가 이상하게 되었네요..
대충 의미만 파악하시길..
in ARM7
gcd CMP a,b
SUBGT a,a,b
SUBLT b,b,a
BNE gcd
.... 직접 보시고.. 소감을...
7) TEQ{cond} Rn, Op2
TST{cond} Rn, Op2
: CMP와 거의 비슷한 구조를 갖는 명령입니다. 기능도 거의 유사합니다.
CMP가 -, CMN이 + 라면, TEQ는 XOR, TST는 AND 연산을 통해 같은 일
을 합니다. 하지만 특징이라면 Logical 연산이 일어날 경우 플래그중
에서 V 플래그(오버플로우 플래그)는 영향을 받지 않습니다. 이걸 잘
응용하면 다음과 같은 처리가 가능합니다.
Ex1) CMP r0,#31 ; test r0<=31 ?
TEQ r0,#127 ; test r0==127 ?
MOVLS r0,#'.' ; if either then r0='.'
Ex2) TST r1,#3 ; is r1 word aligned?
MOVEQ r0,#1 ; r0:=1 if so
MOVNE r0,#0 ; else r0:=0
지난번에 다루었던 MOV 명령까지를 합치면 총 16개의 명령을 설명드렸습니
다. 이로서 가장 비중이 큰(분량이 많은?) Data Processing 명령의 설명을
마쳤군요.
참고로 다루고 있는,혹은 앞으로 다룰 명령의 종류는 다음과 같습니다.
(1) Branch 명령
(2) Data Processing 명령
(3) PSR Transfer 명령
(4) Multiply 명령
(5) Single Data Transfer 명령
(6) Block Data Transfer 명령
(7) Swap 명령
(8) SWI 명령
이밖에도 코프로세서 관련 명령이 있기는 하지만... 그정도까지는 좀 무리
인 듯 싶습니다.
위에 써 놓은 것을 보니 무척 많아 보이는데요, 막상 살펴보면 분류당 1개
-2개 정도 의 명령밖에는 없습니다.
자.. 그럼 오늘 강좌는 여기에서 줄이겠습니다.
----------------------------------------------------------------------
ARM7 강좌 [11] : Instruction Set(5)
----------------------------------------------------------------------
* PSR Transfer 명령
기억하실런지 모르겠지만 PSR이란 Program Status Register 로서 플래그
비트와 Control 비트들로 구성된 레지스터입니다. 해당 레지스터의 값을
일반 레지스터로 옮기거나 반대의 일을 하는 명령이 PSR Transfer 명령입
니다.
PSR은 32비트 레지스터입니다. CPSR과 SPSR 5개를 합쳐서 총 6개가 있습
니다. 여기서 SPSR 은 Exception모드에 따라 여분으로 존재하는 PSR을 말
합니다. 실행 모드에 따라서 유저가 접근할 수 있는 PSR은 한개, 혹은 2
개로 제한됩니다. 예를 들어 유저모드(보통모드)에서는 CPSR에만 접근 할
수 있고, IRQ모드에서는 CPSR과 SPSR_irq 에 접근할 수 있습니다.
여기서 잠깐 지난강좌의 내용을 떠올려 보죠. CPSR이라고 함은 일반적인
플래그 레지스터라고 생각하시면됩니다. 그런데, ARM7에서는 6개의 동작
모드가 있고, Exception(IRQ, FIQ, ABORT 등)에 의해 동작 모드가 전환됩
니다. 각 동작모드에 따라서 몇몇 레지스터들이 교체되고, 이 덕분에 각
모드별로 스택을 따로 관리할 수 있는 기능이 제공됩니다. Exception
Call 에 따르는 수행번지 저장도 스택을 통해 하지 않고 r14(lr) 을 통해
수행합니다. 플래그 레지스터 역시 Exception에 따라 스택에 저장하지 않
아도 되도록 하는 기능을 제공해 주는데, 이런 역할을 하는 것이 SPSR입
니다. SPSR은 총 5개가 있습니다. 유저모드를 제외하고 나머지 5개의 동
작모드마다 하나씩 존재하는데요...
예를 들어 IRQ가 걸렸다고 하면, 우선 CPU동작모드 IRQ 모드로 바뀌고 이
에 따라 r13_irq, r14_irq 로 레지스터 2개가 대치됩니다. 다음 r14_irq
에 기존의 pc(r15)값을 저장합니다. 다음 지정된 벡터로 이동하겠죠...
이때 플래그레지스터, 즉 CPSR의 값도 보전할 필요가 있죠. 그래서 하는
일이 CPSR값을 pc와 비슷한 메커니즘으로 SPSR_irq로 넣어두는 것입니다.
r13_irq와는 좀 차이가 있죠... r13과 같은 범용 레지스터들은 각 수행모
드 별로 그 값이 계속 유지가 됩니다만, SPSR이나 r14는 Exception시에
기존 레지스터 값의 보관을 위해 사용되는 버퍼 역할을 합니다.
어떻든간에... 오늘 설명할 명령어는 두가지 입니다. 사실 그다지 쓰일일
은 없고, CPU동작모드를 임의로 설정하거나, 현재 동작모드를 확인하기
위해서 사용되는 경우가 있습니다.
1) MRS{cond} Rd,<psr> : Transfer PSR contents to a register
MSR{cond} <psr>,Rm : Transfer register contents to PSR
MSR{cond} <psrf>,Rm : Transfer register contents to PSR
flag bits only
MRS명령과 MSR명령의 의미가 헛갈릴 수도 있는데요, M을 Move로, R을레
지스터로, S를 PSF로 파악하면, MRS의 경우엔 Move Reg,PSR 이정도로
생각할 수 있습니다. 즉, 레지스터에 PSR값을 넣는 명령이죠. MSR의 경
우엔 반대로 생각 할 수 있습니다.
참고로 CPSR의 컨트롤비트를 바꾸면 CPU의 동작모드를 임의로 설정할
수 있습니다만, USER모드에서는 해당 기능을 사용할 수 없습니다.
Ex1) MSR CPSR_all,r0
: 해당 명령이 USER모드에서 수행되었다면 Control Bit들은 영향을
받지 않고 Flag Bits[31:28]만 영향을 받습니다.
만약 USER모드를 제외한 다른 모드에서 수행되었다면 CPSR의 모든
비트들이 변화하게 됩니다.
Ex2) MSR CPSR_flg,r0
: CPSR에 접미사 _flg를 붙여주어서 모드에 상관없이 Flag 비트들만
영향을 받도록 합니다.
Ex3) MRS r0,CPSR
: CPU동작모드에 상관없이 CPSR의 모든 비트들을 r0로 복사합니다.
Ex4) MSR SPSR_all,r0
: r0의 값을 SPSR의 모든 비트에 반영합니다. 해당 명령은 USER모드
에서는 수행 불가능합니다. USER모드에서는 접근 가능한 SPSR자체
가 없기 때문입니다.
Ex5) MSR SPSR_flg,#0xC0000000
: SPSR의 N,Z플래그를 세트하고 C,V플래그를 클리어하는 명령입니다.
위와 같이 MSR명령을 Flag비트에 제한을 두어 사용할 경우엔 Imm-
ediate 값을 사용할 수 있다고 합니다.
오늘 강좌는 간단하게 마치려고 합니다. 오랜만의 강좌라 기대를 많이 하신
분들이 혹(?) 계시다면 죄송하구요... 요즘들어 주변상황이 좀 어수선해서
조만간 다시 올리도록 하겠습니다.
----------------------------------------------------------------------
ARM7 강좌 [12] : Instruction Set(6)
----------------------------------------------------------------------
정말 오랜만에 강좌를 쓰는군요. 생활에 여유가 좀 있어서 강좌를 시작했는
데 예상보다 강좌가 길어지고 더불어 점점 다른 일들이 생겨서 요즘에는 통
시간을 낼 수가 없었습니다.
혹... 강좌를 기다리신 분이 계시다면 죄송하다는 말씀을 드려야 겠군요.
아무래도 강좌를 빨리 정리해야겠다는 생각이 듭니다. 자꾸 늘어지니까, 저
도 부담스럽고... 읽으시는 분들에게도 폐를 끼치는 것 같아서...
남은 부분에 대해서는 최대한 핵심만 얘기하려 합니다.
사실 명령어 하나하나에 대해 일일히 설명한다는 것이... 뭐 그다지 의미있
는 일 같지도 않고, 이쯤까지 왔다면 대충 어떤 명령어들이 있는지만 파악
하시고, 나중에 필요하실 때 데이터시트 찾아보시면 될것 같아요...
정리를 해보자면... 이제 말씀드릴 명령은
곱하기 명령(MUL,MLA),
데이터 전송 명령(LDR, STR),
블럭데이터 전송명령(LDM, STM) 그리고
기타 명령(SWP, SWI)
정도 입니다. Coprocessor 명령은 생략하도록 하고, 명령이 끝나면 실전 케
이스로 간단한 예제 설명을 하나 드리려고 하고, 마지막으로 스트롱암의 스
펙 정도를 간단히 언급하겠습니다.
남은 부분이 앞으로 몇번에 걸쳐서 매듭지어질지는 해봐야 겠지만, 최대한
스피디한 진행을 하려 합니다.
차후에 기회가 다으면 MMU 부분같은 것들을 짧게 짧게 다룰 수도 있겠지요.
자... 이제 시작하겠습니다.
* 곱하기 명령(MUL, MLA)
ARM7에서의 곱하기 명령은 크게 두종류가 있습니다. 하나는 그냥 곱하는
것이고, 다른 하나는 곱해서 더하는 것입니다. ^^ 명료하죠?
1) MUL{cond}{S} Rd,Rm,Rs
cond 부분은 해당 명령의 실행 조건입니다. S 플래그는 결과가 플래그
레지스터에 영향을 미칠지의 여부라고 계속 말씀드렸었죠?
다음으로 레지스터 3개를 지정하도록 되어있는데, Rd는 결과가 저장될
레지스터이고, Rm과 Rs는 곱해질 두개의 레지스터입니다. 보셨듯이 이
명령에서는 레지스터만을 사용해야 합니다.
Ex) MUL R1,R2,R3 ; R1:=R2*R3
# 참고로 곱하기의 결과가 32비트를 넘는다면, 하위 32비트만 결과 레
지스터에 남습니다.
2) MLA{cond}{S} Rd,Rm,Rs,Rn
위와 비슷합니다만, 이번에는 레지스터가 4개입니다. 단순 명료하게
의미를 말씀드리면...
Rd := Rm * Rs + Rn 의 의미입니다.
* Single Data Transfer (LDR, STR)
해당 명령은 레지스터와 외부 메모리와의 데이터 전송을 담당하는 명령입
니다. 무척 사용빈도가 높은 명령입니다. 86에서는 MOV하나로 레지스터간
의 데이터 전송과, 외부메모리와의 데이터 전송의 두가지 목적으로 사용
하지만, ARM7 에서는 구분이 되어있습니다.
즉, MOV명령은 레지스터간의 전송명령으로 분류도 데이터 처리명령으로
분류되고, 데이터 전송명령으로는 LDR과 STR이 있습니다.
여기에 사용되는 옵션이 많은데요, 우선, LDR은 로드라는 의미이므로 외
부 메모리로부터 레지스터로 데이터를 읽어오는 명령이고, STR은 반대의
기능을 하는 명령입니다.
- 명령 형식
LDR{cond}{B} Rd, address{!} Rd:= contents of address
LDR{cond}{B} Rd, =expression Rd:= expression
STR{cond}{B} Rd, address{!} contents of address := Rd
LDR과 STR은 Single Data 전송 명령입니다. 비슷한 명령으로 LDM, STM은
여러개의 레지스터 내용을 전송할 수 있는 명령입니다. 이밖에 SWP라는
스왑 명령이 있는데, 해당 5개의 명령만이 외부 메모리와 레지스터간의
전송을 가능하게 하는 명령입니다.
LDR과 STR의 경우 전송 단위를 바이트, 혹은 워드(32Bit)단위로 수행 할
수 있습니다. 바이트 단위 전송의 경우 해당 레지스터의 어떤 부분이 사
용될지의 여부는 해당 프로세서의 Endian 에 달려 있습니다. 또, 워드 전
송 명령을 사용할 경우, 메모리 어드레스는 Word align이 되어야 합니다.
다음 표는 LDR과 STR에서 사용하는 전송 모드를 나타낸 것입니다.
--------------------------------------------------------------------
Mode Effective address Indexing
--------------------------------------------------------------------
[Rn] Rn none
[Rn,+- expression] Rn +- expression Pre-indexed
[Rn,+- Rm] Rn +- Rm Pre-indexed
[Rn,+- Rm, shift cnt] Rn+-(Rm shifted by cnt) Pre-indexed
[Rn],+-expression Rn Post-indexed
[Rn],+-Rm Rn Post-indexed
[Rn],+-Rm,shift cnt Rn Post-indexed
--------------------------------------------------------------------
# Rn : base 주소를 가지고 있는 레지스터
Rm : r15를 제외한 레지스터(옵셋), 부호값 사용
expression : -4095 - +4096 범위의 Immediate 값(12Bit)
shift : LSL, LSR, ASR, ROR, RRX
cnt : 1..31 사이의 값.
상당히 복잡한 내용입니다. 표에서 Mode 부분이 실제 어셈블러에서 사용하
는 명령의 형식이라고 보시면 됩니다. 각 모드별로 예제를 들어서 설명하
도록 하죠.
1) Pre-Indexed Addressing Mode
이 모드에서는 Rn을 베이스 주소로 사용합니다. 여기에 더해서 옵셋을
지정하거나, 혹은 지정하지 않을 수 있습니다. 옵셋을 사용할 경우에는
해당 옵셋을 베이스 주소에서 더하도록 하거나 뺄 수 있는데, 위의 표에
서 +, - 기호가 그것을 의미합니다.
옵셋은 부호가 있는 12Bit Immediate값을 사용하거나 레지스터를 지정해
서 해당 레지스터의 내용으로 사용할 수 있습니다. 또한 레지스터를 옵
셋으로 사용하는 경우에는 Shift 시켜서 적용시킬 수 있습니다. 관련 내
용을 다시 확인하고 싶으신 분들은 데이터 전송명령의 오퍼랜드 2 에 대
한 설명을 다시 확인하시길 바랍니다.
Ex) LDR r0,[r1] ; r1을 베이스로 사용하고 옵셋은 지정하
지 않는 형태입니다. r0에 r1을 번지로
하는 워드(4바이트)를 읽어드립니다.
LDR r0,[r1,#132] ; 이번에는 옵셋으로 132를 지정한 형태입
니다.
STR r0,[r1,r2] ; 베이스는 r1, 옵셋은 r2를 사용한 형태
입니다. 즉 *(r1+r2)=r0 와 같은 의미..
LDR r0,[r1,r2,LSL #2] ; 베이스 r1, 옵셋은 r2<<2 의 형태.
이번에는 Write-Back 기능에 대해서 알아보겠습니다. LDR명령의 경우 옵
션으로 Write-Back 을 지정할 수 있는데, 지정할 경우 원래 베이스에 옵
셋을 더한 값을 다시 베이스 레지스터로 넣는 기능을 합니다. 제 생각에
는 이 기능이 C에서 ++와 같은 의미라 생각되는데요... 글세 쓰기 나름
이겠지요. 다음은 예제입니다.
Ex)
1: LDR r0,=table_end
2: LDR r1,=table
3:
4: MOV r2,#0
5:loop STR r2,[r0,#-4]!
6:
7: ADD r2,r2,#1
8: CMP r0,r1
9: BNE loop
10:
11: ...
12:
13: ALIGN
14:table % table_length*4
15:table_end
예제가 좀 길군요. 주의해서 보실 부분은 5번 라인입니다. 해당 명령
은 STR r2,[r0,#-4]! 이죠... r2를 r0를 베이스로 삼고 옵셋으로
-4값을 사용했군요. r0가 가리키는 포인터가 실제 버퍼로 사용할 공
간이 끝난 바로 다음을 가리키고 있으므로 -4를 하면 마지막 워드 엔
트리 포인트가 됩니다. 그리고 주의하실점은 ! 를 사용한 것인데요..
이것이 바로 Write-Back기능입니다. 위의 설명에 나와있듯이 베이스
값(여기서는 r0가 되겠군요...)을 갱신하는 것인데요...
예를 들어 1000번지부터 2개의 entry를 가정한다면, table은 1000 이
될 것이고 table_end는 1008 번지가 될 것입니다. 이때 STR명령에서
1008을 베이스로 -4를 옵셋으로 설정했으므로 실제로 r2값은 1004 번
지부터 4바이트에 기록이 될 것입니다. 이후 Write-Back 옵션이 적용
되어 해당 명령이 끝나면 r0값은 1004로 (1008-4) 바뀌게 됩니다.
참... 여기서 Pre-Index Mode이기 때문에 실제 주소를 구할 때 옵셋
을 먼저 빼 주었군요... 아무쪼록 이해 하셨기를 바라며... 다음으로
넘어가렵니다.
2) Post-Indexed Addressing Mode
Post인덱스 모드의 경우에는 Pre인덱스 모드에 비해 Effective Address
는 항상 Rn, 즉 베이스 어드레스를 나타내는 레지스터의 값입니다. 그
리고 한가지 주의하실 점은 Post인덱스 모드의 경우엔 따로 !를 사용하
지 않더라도 디폴트로 Write-Back 모드가 사용됩니다. 그렇겠죠? Post
인데 Write-Back이 안된다면... 옵셋을 사용할 이유가 없군요...
Ex) LDR r0,[r1],r2 ; 대괄호의 사용이 Pre 인덱스의 경우와
다릅니다. 실제 수행되는 것은 r0에다
r1을 주소로 하여 값을 읽어오고 다시
r1에는 r2를 더해주는 일을 합니다.
STR r0,[r1],#20 ; [r1]:=r0, r1:=r1+20
1: LDR r0,=table
2: LDR r1,=table_end
3:
4: MOV r2,#0
5:loop STR r2,[r0], #4
6:
7: ADD r2,r2,#1
8: CMP r0,r1
9: BNE loop
10:
11: ...
12:
13: ALIGN
14:table % table_length*4
15:table_end
마지막 예제는 위에서 나왔던 예제와 비슷하니 잘 분석해 보시길
바랍니다.
3) Relative Addressing Mode
해당 Addressing 모드는 어셈블러가 적절히 지원하여 변환해 주는 모드
라고 생각하시면 됩니다.
Ex) LDR r5,ThreeCubed
...
ThreeCubed DCD 27
위와 같은 경우 실제로는 LDR r5,[PC,#constant] 형태의 코드로 번역
해 줍니다. 즉 PC를 베이스로 삼아서 코드를 만드는 것이지요. 만약
해당 심볼이 지정하는 범위가 너무 커서 상수로 지정할 수 없다면 어
셈블을 할 때 에러를 내게 됩니다.
또 많이 사용되는 표현으로 다음과 같은 표현이 있습니다.
Ex) LDR r0,=0x12345678
사실은 위의 예에서도 사용했었는데요... 이 경우 어셈블러가 해당 상
수값을 특정 공간에 모아서 삽입 해 주고 (이공간을 Literal Pool이라
하는군요) 역시 마찬가지로 PC를 베이스로 해서 명령코드를 만듭니다.
자.. 오늘은 이만 쓰렵니다. 사실 열두번째 강좌는 쓰기시작한지 몇 주만에
끝내게 되는군요... 중간중간 계속 일이 생겨서. 미뤄두고 있다가, 메일로
강좌를 재촉하시는 분들이 계셔서..(흑.. 감동)
암튼.. 다음강좌에 뵙도록 하겠습니다.
----------------------------------------------------------------------
ARM7 강좌 [13] : Instruction Set(7)
----------------------------------------------------------------------
* Block Data Transfer 명령(LDM,STM)
해당 명령은 개인적인 생각으로 참 독특하다고 생각합니다. 지난 강좌에
서 다루었던 LDR, STR과 마찬가지로 실제 메모리에 레지스터의 내용을 전
달 하거나, 전달 받을 수 있는 명령입니다. ARM7에서는 이런 명령이 몇
안되죠...
LDR명령이 메모리 번지의 내용을 지정된 레지스터로 가져오는 명령이라면
LDM은 가져오긴 하는데, 여러개의 레지스터의 내용을 한큐에 가져오는 명
령입니다. 가장 많이 사용되는 경우는 스택 연산인것 같습니다. 전에 말
씀드렸었지만, ARM7에는 Push, Pop 명령이 없습니다. 대신 LDR이나 STR을
쓸 수도 있겠고... 또 LDM이나 STM을 쓸 수도 있죠... 후자 쪽이 더 많이
사용되는 듯 합니다.
1) <LDM|STM>{cond}mode Rn{!},{reg_list}{^}
위 명령에서 {cond}는 늘 보아오던 명령어 실행 조건입니다. Rn은 전송
에 사용될 베이스 번지를 지정하는 레지스터입니다. !를 붙이면 Wrte
Back 기능이죠... LDR과 STR에서 다루었습니다. 자세한 내용은 뒤에서
언급하도록 하겠습니다.
{reg_list} 부분은 전송하거나 전송받을 레지스터의 목록을 나타내는
부분입니다. 예를 들어 1000번지에 r1,r2,r3를 저장하고 싶다 했을 경
우에, 일단 1000번지 값을 어떤 레지스터에 넣어두고... 여기서는 그
레지스터를 r13이라고 하죠, 그러면 Rn은 r13이 되는 거구요,
{reg_list}는 {r1,r2,r3} 이 되는 것입니다. mode 라고 되어있는 부분
은 여러개의 레지스터를 메모리에 넣거나 가져올 때 어떤 방식으로 동
작할지를 지정하는 접미사입니다. 이 접미사 종류가 8가지가 있는데요.
무지하게 복잡해 보입니다. 일단은 각 요소의 의미만 간단하게 정리하
고, 다음으로 넘어가죠.
마지막으로 {^}부분은... 글세요 잘 이해가 안되는 부분입니다만...
제가 보는 책과 데이터 시트에서 예제가 나와 있지 않군요. 그냥 문서
의 내용을 그대로 적어보겠습니다.
{^} if present set S bit to load the CPSR along with the PC, or
force transfer of user bank when in privileged mode...(???)
자... 그럼 이제 본격적으로 설명에 들어가겠습니다.
먼저 1단계, LDM 과 STM의 의미 입니다.
LDM : 베이스 레지스터(Rn)로 지정된 번지에서 레지스터 목록으로 지
정된 각 레지스터의 내용을 읽어들이는 명령.
STM : LDM과 반대.
여기까지는 별 무리가 없으리라 생각합니다. 혹시 이 명령을 8086등에
있는 블럭 데이타 전송명령 등과 혼동하지 않으시길 바랍니다. 어렴풋이
기억하는데, 8086등에는 메모리에서 메모리로 블럭 전송을 할 수 있는
명령이 있죠... 또는 특정 길이만큼 메모리를 어떤 값으로 설정하는 블
럭 설정 명령도 있었던 듯 합니다.
ARM7의 LDM과 STM은 블럭 전송이 아니라 Multiple Register 전송입니다.
쉽게 생각하면
push ax
push bx
push cx
push dx
가 8086형태라고 할 때, ARM7에서 Single 데이터 전송 명령을 사용하면
STR r0,[sp],#4
STR r1,[sp],#4
STR r3,[sp],#4
STR r4,[sp],#4
쯤이 되겠고, 또 Multiple 전송명령을 사용하면,
STMEA sp!,{r0,r1,r2,r4}
제가 방금 적어본 것이라 맞는 것인지 확신은 없습니다만... 그냥 개
념이 이렇다는 것만 파악하셨으면 합니다.
그러면 이제 2단계, {Reg_List}를 자세히 다루어 보죠... 위의 예에서
나와있듯이 중괄호 사이에 전송 대상이 되는 레지스터를 넣어주면 됩
니다. 그렇다면 몇개까지 가능한 것일까요? ARM7에서 한시점에 사용할
수 있는 레지스터의 개수는 r0에서 r15까지 총 16개죠..
LDM이나 STM명령에서 지정할 수 있는 레지스터의 개수는 최대 16개 입
니다. 즉, 한 명령으로 모든 레지스터를 저장하거나, 가져올 수 있다
는 의미입니다.
참 재미있는 사실은, LDM명령의 니모닉상에 16비트의 공간이 있어서
각 비트가 레지스터 r0-r15와 1:1로 대응이 된다는 사실입니다. 따라
서 {reg_list}에는 어떠한 레지스터의 조합도 올 수 있습니다. 감동 !
그리고 어셈블러의 문제겠지만, {r0,r2} 이런 형식 뿐만 아니라,
{r0-r5} 와 같은 형식, {r0-r3,r6-r7} 이런 형식도 사용할 수 있습니
다.
마지막으로 확인할 것은, {r3,r2,r1} 이렇게 썼을 때와 {r1,r2,r3} 이
렇게 썼을 경우, 메모리에 저장되는 순서가 다를까요.. 아닐까요....
말씀드렸듯이 16비트의 비트필드가 존재해서 각각 레지스터와 1:1대응
이 된다고 하였으니... 소스코드에서 어떤 형식을 쓰든... 니모닉으로
변환될 때는 그 순서는 아무 의미가 없겠지요.. 결국 같다는 말입니다.
자... 이번에는 3단계입니다. 동작 모드!!!
위의 STM명령에서 제가 STMEA라고 명령을 적었습니다. EA가 동작모드
를 지정하는 부분입니다. 이와 같은 키워드가 8가지가 있고, 동작모드
는 4가지가 있습니다.
먼저 4가지의 동작모드를 말씀드리겠습니다.
A) Post-Increment Addressing
여기서 동작모드는 여러개의 레지스터값을 메모리로(혹은 로부터)
전송할 경우 해당 메모리 번지를 증가시키면서 저장할지, 혹은 감
소시키면서 저장할지를 지정하는 것과, 증/감을 하는데, 저장하기
전에 증/감을 할지, 아니면 저장하고 나서 증/감을 할지를 지정하
는 것을 의미합니다.
처음 설명할 동작모드는 저장 이후 증가하는 방식입니다.
예를 들어 R10에 0x1000이 들어있다고 가정하고 R10을 베이스레지
스터로 사용해서 {r1,r2}를 저장한다면, Post-Increment모드에서는,
1. 0x1000 번지에 r1이 저장된다.
2. Base 번지값이 0x1004로 증가한다.
3. 0x1004 번지에 r2가 저장된다.
4. Base 번지값은 0x1008로 증가한다.
만약 !를 사용했다면 r10의 값은 0x1008이 될 것입니다.
B) Pre-Increment Addressing
말 그대로 먼저 증가하고 다음에 저장하는 동작 모드입니다.
위와 같은 조건을 가정해 봅시다.
1. Base 번지값이 0x1004로 증가한다.
2. 0x1004번지에 r1이 저장된다.
3. Base 번지값이 0x1008로 증가한다.
4. 0x1008번지에 r2가 저장된다.
역시 !를 사용했다면 r10의 값은 0x1008이 됩니다.
C) Post-Decrement Addressing
이번에는 베이스 번지가 감소하는 경우죠. 좀 특이한 것은, 감소
모드로 저장(로드)을 할 경우 아까는 레지스터번호가 빠른 것부터
저장하거나 불러들였는데, 이번에는 거꾸로라는 것입니다. 결과적
으로, 메모리에 저장되는 레지스터의 순서는 항상 동일하다는 것
이죠... 마찬가지로 같은 조건에서 예제를 들겠습니다.
1. 0x1000번지에 r2가 저장된다.(!!! r1이 아니라 r2)
2. Base번지값이 0x0FFC로 감소된다.
3. 0x0FFC번지에 r1이 저장된다.
4. Base번지값이 0x0FF8로 감소된다.
만약 !를 사용했다면 r10의 값은 0xFF8이 된다.
D) Pre-Decrement Addressing
1. Base번지값이 0x0FFC로 감소된다.
2. 0x0FFC번지에 r2가 저장된다.
3. Base번지값이 0x0FF8로 감소된다.
4. 0x0FF8번지에 r1이 저장된다.
만약 !를 사용했다면 r10의 값은 0xFF8이 된다.
여기까지 4개의 동작모드를 설명했습니다.
동작모드를 나타내는 키워드는 8개인데요... 각각의 동작모드에 대해서
스택처럼 사용할 경우, 혹은 아닐 경우 2가지로 나누어서 나타내기 때
문입니다.
다음 표는 각 동작모드에 대한 명령어입니다.
==================================================================
동작 Stack Other
------------------------------------------------------------------
pre increment load LDMED LDMIB
post increment load LDMFD LDMIA
pre decrement load LDMEA LDMDB
post decrement load LDMFA LDMDA
pre increment store STMFA STMIB
post increment store STMEA STMIA
pre decrement store STMFD STMDB
post decrement store STMED STMDA
==================================================================
Stack인 경우와 아닌경우 키워드가 다른 것은, 단지 유저의 편이를위한
배려라고 생각됩니다. 즉, 키워드를 LDMED로 썼을 경우나 LDMIB로 썼을
경우, 동작상에 차이는 없는 듯 합니다.
키워드를 무작정 붙인것 같지는 않구요... 먼저 Other의 키워드를 살피
면, I는 increment를 의미하구요.. D는 decrement겠죠.. 그리고 B는
Before를, A는 After를 의미합니다.
그러므로 만약 LDMDA 는 post decrement 모드를 의미하는 것이죠....
Stack의 경우엔, E는 Empty를 F는 Full을 의미한답니다. 스택을 구현하
는 경우 현재 sp가 가리키는 번지의 내용이 차있는지, 비어있는지를 의
미한다고 보시면 될 듯 합니다. 무슨얘기냐면... 만약 Post 모드를 사
용한다면, 스택을 구현할 경우, 어떤 내용을 넣고 다음에 번지를 증/감
하므로 결국 어떤 시점에서 스택포인터가 가리키는 번지는 비어있게 됩
니다. 이 경우 Empty가 되겠죠...
Load의 경우엔 Empty 형태의 스택이라면 sp가 가리키는 공간에 아무 내
용도 없으므로 먼저 sp를 변화시키고 데이터를 가져와야겠죠.. 그래서
Load는 Pre가 Empty 와 대응이 됩니다. 하지만 반대로 Store의 경우엔
Empty 형태의 스택을 위해서는 먼저 데이터를 넣고 sp를 변화시켜야 합
니다. 그렇다면 post모드가 Empty와 대응이 되겠군요..!!
Full은 더이상 말 안해도 되리라 믿습니다.
다음으로 D는 Decending, A는 Ascending을 의미합니다. 이것은 스택이
거꾸로 커지는지 아니면 반대인지와 관련이 있습니다. 8086에서는 Push
를 하면 sp값이 작아지죠? 그렇다면 decending Stack이라고 볼 수 있습
니다. push와 STM이 대응되므로 STM의 Decrement 모드는 D 라는 키워드
를 사용했군요... Pop의 경우는 LDM과 대응되고 decending stack에서
Pop을 할경우 sp값은 증가되어야 겠죠... 그래서 LDM에서는 increment
모드가 D입니다.
A는 반대이겠죠... 결국 스택관련 명령에서는 LDM이나 STM에서 같은 접
미사를 사용하면 되는 것입니다. 물론 동작 방식은 LDM과 STM에서 각기
다르지만요...
자.. 이제 예제를 하나 보이고 오늘 강좌를 정리하려 합니다.
STMED sp!,{r0-r3,r14}
BL somewhere
LDMED sp!,{r0-r3,r15}
첫번째 명령에 STMED는 Empty Decending Stack Operation이므로 실제
로는 post-decrement 동작모드를 의미하죠.. sp(r13)가 가리키는 번지
에 r0,r1,r3,r14를 저장합니다. BL로 이 루틴에 들어왔다면 r14에 복
귀 번지가 들어가 있다는것을 감안하십시요..
BL에서 뭔가 처리를 하고, 마지막으로 LDMED명령에서 레지스터를 복구
합니다. 이번에는 pre-Increment 동작모드입니다.
한가지 주의하실 점은 r14대신에 r15로 복구를 시켰다는 것입니다.
ARM7에서는 ret명령 대신 mov r15,r14 를 사용한다고 말씀드렸었죠...
LDMED 명령에서 레지스터 복구와 서브루틴 복귀를 동시에 처리하는 부
분입니다.
자... 오늘 강좌는 이렇게 정리할까 합니다. 거의 1달만에 강좌를 썼군요.
그동안 메일이나 게시판을 통해서 질문과 격려를 보내주신 분들에게... 죄
송하다는 말씀을 드려야 겠군요...
차일피일 미루다보니..쩝.
이제 강좌도 종반을 향해 달리고 있습니다. 아마도 2회 정도면 계획했던 모
두가 끝이 날것 같군요... 다음 강좌를 기약하며 이만 줄이겠습니다.
----------------------------------------------------------------------
ARM7 강좌 [14] : Instruction Set(8)
----------------------------------------------------------------------
오늘 다룰 명령은 SWP와 SWI두가지 입니다. Co - Process 명령을 제외하면
이 명령이 마지막이겠군요... 코프로세서는 다루지 않을 생각이니... 참 홀
가분한 느낌입니다.
1. Single Data Swap : <SWP>{cond}{B} Rd,Rm,[Rn]
레지스터를 3개 지정하도록 되어 있습니다. 실제 동작은
Rd:=[Rn], [Rn]:=Rm 이 한번에 일어나는 명령입니다. 여기서 한번이라는
말은 한클럭을 의미하는 것이 아니라, 명령 도중에 인터럽트 등에 의해
중단되지 않고 계속 이루어진다는 것입니다. 그리고 B 접미사는 계속 보
아 왔듯이 워드 Operation이 아니라 Byte Operation을 의미합니다.
예제를 보죠.
SWP r0,r1,[r2]
; r0:=[r2], [r2]:=r1 입니다.
SWPB r2,r3,[r4]
; r2:=[r4], [r4]:=r3 입니다. 다만 B가 붙었으므로
Bit 0에서 7까지만 영향을 미칩니다
SWPEQ r0,r0,[r1]
; Flag의 상태를 확인하여 r0와 [r1]의 내용을 바꾸는
형태입니다. 보셨듯이 Rd와 Rm이 같을 수도 있군요.
한가지 더 언급하고 싶은것은 SWP를 세마포어 구현에 사용하는 방법입니
다. 어떤 문서에선가 SWP명령이 세마포어를 구현하는데 유용하다고 읽었
는데... 처음에는 이해가 안되더군요.. 한참 뒤에 이해할 수 있었습니다.
인터럽트를 금지시키지 않고 Semaphore 연산을 할 수 있다는 것이 SWP명
령의 강점입니다. 여기서 Semaphore를 설명드리긴 좀 그러니, 간단히 핵
심만 말씀드리고... 이해하실 분은 하시고... 안해도 별 수 없겠죠.
보통 세마포어의 p()연산을 구현하는 순서로, 먼저 세마포어 변수를 읽
어오고, 다음에 비교를 하죠. 그 값이 0보다 크다면 감소를 시켜 다시
Write합니다. Test and Set 연산이라고도 하던데요...
SWP명령에 적용시키려면... [Rn]부분이 변수가 되야겠군요. 그러면 Rd에
는 SWP명령을 통해 세마포어 변수값이 들어올 테구요.. 물론 세마포어변
수의 상태를 알지 못하므로 어떤 값이 들어올런지는 모릅니다. 따라서
이 단계에서는 세마포어 변수에 어떤값을 다시 Write해야 할런지도 모릅
니다.
핵심은 변수에 Write되는 값을 무조건 0으로 설정한다는 것이죠. 즉...
r3가 Semaphore 변수의 주소를 가리키고 있다고 하고, r2의 값은 0이라
고 한다면,
SWP r1,r2,[r3]
와 같은 명령으로 처리할 수 있습니다. 위의 명령을 통해 원래 세마포어
변수의 값이 r1으로 로드됩니다. 0보다 큰지의 여부는 이제부터 비교해
야 겠지요... 한가지 특이한 것은 세마포어 값을 읽어옴과 동시에 0을
넣어주었다는 것입니다. SWP명령의 특성상 읽어오는 동작과 0을 넣는 동
작 사이에는 인터럽트 등이 걸릴 수 없습니다.
이제, r1의 세마포어 값을 비교하는 부분으로 넘어가면 되는데, 이 와중
에 인터럽트가 걸리고 다른 타스크가 세마포어 변수를 Access하려고 하
더라도 0이 들어 있으니 자연히 대기상태로 인식되어 더이상 진행을 하
지 못하게 될 것입니다.
이밖에도 v()연산에서도 뭔가 더 해주어야 겠지만...
(괜한 얘기를 꺼냈나 하는 후회가 엄습하는 중입니다...^^)
2. Software Interrupt : SWI{cond} <expression>
SWI명령은 소프트웨어 인터럽트 명령입니다. 8086에는 INT 명령이 있죠?
Exception 파트를 보시면 언급이 있었습니다.
SWI명령이 걸리면 동작모드가 변화합니다. Supervisor 상태로 진입을 하
게 됩니다. 이런 특성 때문에 pSOS의 경우는 System Call의 진입방법으
로 사용합니다.
명령의 형식을 보시면 <expression>부분이 있는데, 무슨 역할을 하는 것
일까요? 8086계열 처럼 INT 21H 또는 INT 10H 이런 식으로 인수를 주는
것일까요? 8086이야 Interrupt 벡터를 지정하는 것이었지만... ARM7에는
해당 Vector는 고정이 되어 있습니다.(Software Exception 한가지로)...
CPU는 expression에 대한 아무런 일도 하지 않습니다. 실제 명령어 구조
를 보면 총 32비트 중 상위 4비트는 조건 Flag에 사용되고, 다음 4비트
가 모두 1111 이면 SWI명령으로 판단됩니다. 이후 24비트는 실제로는 무
시되는 내용입니다만...
위와 같이 써주면 expression의 내용이 SWI명령의 Low 24Bit부분에 인코
딩 됩니다. 하지만 말씀 드렸듯이 ARM7은 SWI명령의 Low 25Bit내용이 뭐
든 간에 동일하게 동작합니다.
그럼 왜 그렇게 쓰는걸까요?
예제를 보면 SWI명령을 만나면 소프트웨어 Exception Handler로 이동하
고 복귀번지는 r14_svc로 저장이 됩니다. 그런데 핸들러 부분에서 복귀
번지를 이용하여 해당 명령을 직접 읽어다가 Low 24 Bit 부분을 인수로
해석해서 사용할 수 있는 것입니다.
물론 이런 일들은 ARM7이 해주는 것이 아니라 유저가 핸들러에서 직접
프로그램 하는 것이죠.
다음은 핸들러 부분의 예제입니다.
STMFD r13,{r0-r2,r14}
LDR r0,[r14,#-4]
BIC r0,r0,#0xFF000000
...
위에서 보시면 결국 r0에 SWI명령의 low 24Bit가 얻어지죠.
오늘 강좌까지... 길고 길었던... 정말 길었던 ARM Instruction 부분을 끝
냈습니다.
계획했던 분량은 3회 였는데... 결국 8회분량으로 늘어나고 말았군요.
이것저것 후회가 많았던 부분이었습니다.
이렇게 저렇게 숙제하듯이 여기까지 해치우고는...
다음엔 뭘 써야할까... 고민을 하게 되는군요.
뭐가 되었든 다음 강좌로 ARM7 강좌를 정리하겠습니다.
(마음의 준비를...^^)
그럼 이만.
[출처] [펌] Arm7 강좌|작성자 제제
ARM7TDMI 레퍼런스 매뉴얼을 살펴보면 다음과 같이 칩코어의 블럭다이어그램을 찾을 수 있다.

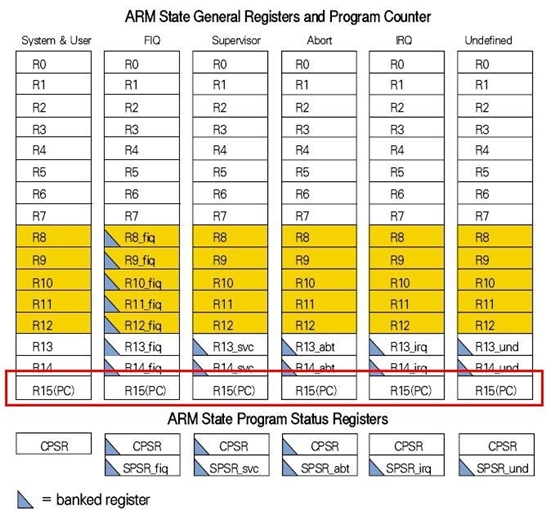
위 그림에서 좌측부분을 보면 디바이스가 프로그램메모리에 접근하기 위해 PC(프로그램 카운터) 정보를 레지스터로부터 가져옴을 볼 수 있는데, 이로부터 resolve하는 어드레스의 크기는 A31:0의 총 32비트임을 보여준다. 즉, SAM7S가 인식하는 메모리의 어드레스 공간은 총 32비트(약 4.3GB)로 구성됨을 알 수 있다. 또한, PC는 32비트의 주소값을 저장해야 하므로, 아래의 그림에서 ARM7TDMI 코어의 동작모드(총 7가지)에 관계없이 레지스터15(R15)를 PC를 위해 사용한다.
SAM7S는 폰노이만 구조로서, 코어에 내장된 물리적 메모리(플래시 및 SRAM)와 각종 I/O 주변장치등을 매모리맵 I/O 방식(Memory Mapped I/O)으로 맵핑시켜 두었다. (아래 그림 참고)

우선 위의 그림의 좌측에서와 같이, 32비트의 어드레스 공간은 크게 3개의 영역으로 나뉘어져 있다. 하위 256MB는 물리적 메모리를 위한 영역으로 할당되어 있고, 상위 256MB는 주변장치를 위한 I/O 공간으로 할당되어 있다. 이들 사이의 3.5GB 정도의 공간은 미정의상태로서 사용되지 않는다.
여기서 하위 256MB의 물리적메모리를 위한 공간을 다시 자세히 살펴보면, 3개의 1MB 영역과 253MB의 미사용영역으로 이루어져 있음을 알 수 있다.(위 그림에서 우측 참고) 여기서, SAM7S의 프로그램메모리(플래시)는 0x10_0000 번지부터 맵핑되어 있으며, 데이터메모리(SRAM)는 0x20_0000 번지부터 맵핑되어 있다. 플래시와 SRAM의 공간은 각각 1MB의 영역만큼 할당되어 있으나, 플래시메모리와 SRAM의 용량은 디바이스마다 그 크기가 정해져 있기 때문에 실제 사용되는 공간은 디바이스의 메모리 용량에 의해 결정된다. (예컨데, SAM7S256의 경우 플래시메모리의 크기가 256KB이므로 256KB의 공간만큼만 사용가능)
디바이스가 리셋이 되면 PC는 0x0000_0000 번지로 점프하므로 이 곳은 아무런 메모리도 할당되어 있지 않아 왠지 모순이 되는 것 같다. 그러나, SAM7S에는 메모리 리맵핑(Memory Re-mapping) 기능이 제공되고 있어, 디폴트로 0x10_0000 번지의 플래시영역이 0x00_0000 번지에 리맵핑되어 있다. 따라서, 리셋이 되면 SAM7S는 플래시메모리의 내용을 읽으면서 부팅이 된다. 반면에, MC_RCR이란 레지스터의 RCB비트를 1로 세팅하면 재배치 명령(Remmap Command)이 실행되어 0x20_0000 번지의 SRAM영역이 0x00_0000 번지로 리맵핑되어 SRAM의 내용을 읽으면서 부팅이된다.
SAM7S의 플래시메모리는 Single Plane으로 구성되어 있기 때문에, 플래시메모리의 내용을 실행하면서 플래시-라이트를 할 수는 없다. 때문에, SAMBA와 같은 경우 이 리맵핑 기능을 이용하여 SRAM영역으로 SAMBA 코드를 복사한 뒤 SRAM영역에서 부팅하여 플래시메모리에 펌웨어를 라이팅하게 된다.
--------------------------------------------------------------------------------------
요즘 떠오르는 MCU 중의 하나 ARM7의 메모리 구조 입니다.
이번에도 오실로 스코프를 하려 했다가, 오실로 스코프가 주제가 아닌데 너무 도배를 하는 것 같아서
ARM7을 블로깅 하게 되었습니다.
위 글 중에서 중요한 것은 그림 입니다.
첫번째 그림의 경우에는 기본적인 흐름도를 나타내주고요.
두번째 그림의 경우에는 시스템의 상태별 레지스터 구조도를 알려줍니다.
참고로 썸상태의 레지스터 구조도는 그림이 없어서 참조하지 못했습니다.
마지막 그림은 플래쉬 메모리의 구조입니다.
이 세가지 그림을 잘 이해하신다면 arm7의 큰 그림은 보실 줄 알게 되는 것 입니다.
자세한 사항은 데이터 시트를 보시면 알 수 있으실 겁니다.
혹, 데이터 시트를 찾으신다면 저에게 연락주세요.^^
|
오실로스코프의 대역폭
|
1. 오실로스코프 아날로그 대역폭(Analog Bandwidth)은 입력되는 정현파의 진폭이 -3dB
(대략 30%) 저하되는 지점의 주파수로 정의 합니다.

2. 오실로스코프의 대역폭별 50 MHz 구형파 신호의 재생

3. 구형파나 펄스파와 같이 빠른 상승 또는 하강 시간을 갖는 신호를 측정시 다량의 고주파
성분을 포함하고 있어 신호의 반복 주기만을 감안한 스코프 대역폭 선택은 의미가 없을 수
있습니다. 따라서, 신호의 주파수 보다 높은 대역폭을 갖는 스코프를 사용하여야 합니다.
* 오실로스코프의 신호대비 낮은 대역폭으로 인한 영향
- 신호의 상승/하강 시간이 길어진다.
- 신호의 진폭을 감소 시킨다.
* 오실로스코프의 대역폭 계산법
디지탈 오실로스코프를 구성하는 시스템들은 대부분 아날로그 오실로스코프와 같지만, 데이타 처
오실로스코프의 성능에 따라 샘플점의 추가적인 처리를 할 수 있으며, 이런 처리과정을 통해 화면
기본적으로 디지탈 오실로스코프도 아날로그 오실로스코프에서와 같이 수직부, 수평부, 동기 세팅
샘플링 방법이란 디지탈 오실로스코프에서 샘플점을 얻는 방법을 말합니다. 디지탈 오실 로스코프
■ 실시간 샘플링 모드 : 신호에서 한번에 몇 개의 샘플들을 잡은 후 보간법
(interpolation)을 사용하는 모드입니다. 이 때 보간법은 몇개의 점들을 연결해서 예
상되는 파형을 그려내는 처리 기술입니다.
■ 등가시간 샘플링 모드 : 신호가 계속 반복되고 있는 동안에 일정 시간 간격으로 샘플들을 모아서 파형이 형성되는 모드입니다. 즉 반복되는 신호들에서 시간축의 값을
달리하면서 얻은 샘플점으로 한 주기의 파형을 합성하는 것입니다.
2-3-4 보간법을 사용한 실시간 샘플링(Real-Time sampling)
디지탈 오실로스코프는 표준 샘플링 방법으로서 실시간 샘플링을 사용합니다. 실시간 샘플링에서는 신호가 발생할 때 가능한 많은 샘플을 추출합니다.(그림 9) 그러므로 단발현상이나 과도신호가 들어올 때는 실시간 샘플링을 해야 합니다.
디지탈 오실로스코프는 신호가 빠를 경우, 한 번에 단지 몇개의 샘플만을 잡기 때문에 보간법을 사용해서 파형을 완성해야 합니다. 보간법은 간단히 말해 점들을 연결하는 방법입 니다. 선형 보간법(Linear interpolation)은 샘플점들을 직선으로 연결하며, 정현 보간법 (Sine Interpolation)은 곡선으로 연결합니다. (그림 10 참조) (SINx)/x 보간법은 컴팩트 디스크 플레이어에 사용되는 오버샘플링(Oversampling)과 유사한 수학처리 과정이며, 정현 보간법을 수행하면서, 실제 획득한 샘플들 사이에 계산에 따라 점들을 추가하는 것입니다.
이러한 처리를 통해서 매 사이클마다 잡는 몇 개의 샘플로도 신호를 정확하게 화면에 나타 낼 수 있습니다.
2-3-5.등가 시간 샘플링(Equivalent-Time sampling)
디지탈 오실로스코프에서는 매우 빠르게 반복되는 신호를 잡을 경우에 등가시간 샘플링 을 사용합니다. 등가 시간 샘플링은 파형이 반복될 때마다 몇 개의 샘플을 잡아그것을 모아서 파형을 구성합니다. (그림 11) 파형은 불들이 하나 하나 순서대로 켜지는 것처럼 느리게 형성되는 것을 볼 수 있습니다. 등가 시간 샘플링 중 순차(sequential) 샘플링에서 는 점들이 좌에서 우로 연속적으로 나타나며, 램덤
오실로 스코프는 하드웨어 제작에 있어서 가장 중요한 장비중의 하나입니다.
요즘 나오는 하드웨어들은 JTAG을 이용해서 디버깅을 많이 할 수 있지만,
그래도 어느정도의 한계점이 있습니다.
소프트웨어의 경우 특별한 일이 없다면 특정 디버깅 툴을 통하여 디버깅을 할 수 있고,
마지막으로는 어셈코드를 직접 보면서 디버깅을 할 수 있습니다.
하지만 하드웨어의 경우에는 변수들의 범위가 코딩 뿐만 아니라 전선연결, 반도체의 문제 또는 모듈의 문제등
정말 다양한 버그들이 꼬옥~숨어있어서 오실로스코프가 없고, 디버깅 툴로 디버깅이 안된다면 속수무책입니다.^^
위에서 알려주는 정보는 그 오실로 스코프에서
샘플링 하는 방법. 핀 아웃에서 어떤 식으로 신호가 나오는데,
그 신호를 어떤 식으로 측정을 해서 사용자에게 알려줄텐데, 그 어떤 식에 대해서 알려주는 것 입니다.
이것이 중요한 이유는 핀에서 나오는 신호는 수백메가 헤르츠 이지만,
사람이 눈으로 확인 할 수 있는 정보는 아무리 빨라도 초당 100개 이하가 되니,,,
수백메가 헤르츠의 정보를 사람의 눈에 어떤 식으로 종합하여 보여주느냐 또한 그 수백메가의 정보를 어떻게 효율적으로
오실로스코프의 장바구니에 담는가가 포인트가 되겠습니다.
사진 링크가 제대로 안되어서,,,ㅡㅡ; 첨부파일로 올립니다.
고거 위치 변경은 할 줄을 몰라서.ㅠㅠ
1. 1999년에는
비 정기적이고 예상 할 수 없는 이벤트들은 풀기 어려운 과제를 남기곤 합니다. 저는 최근 저전력 데이터 수집 디바이스를 설계하면서 이러한 글리치를 마주치게됩니다. 이 무선 계측시스템은 주파수확산 라디오 송수신기(그림 1)로 주고받는 원격 센서의 그룹으로 구성되어 집니다. 시스템에 취합된 데이터는 컴퓨터에 연결된 네트워크 제어 유닛으로 재취합됩니다. 시스템은 매 60초 마다 파워업 상태를 트리거하기 위해 저전력 클럭칩에 인터럽트 핀을 사용합니다.
그림 1. 무선 계측시스템의 개념도. 스코프에서 하나의 아날로그 입력에서 MCU상의 power-up를 모니털링하고 또다른 하나는 송수신기를 피드하는 캐리어 감지 신호를 모니터링. - 첫번째 사진 입니다.
이벤트 사이에 클럭과 보조 로직은 전류(대략 50 μA)를 흐르게 하는 유일한 장치입니다. 클럭으로부터 트리거를 받으면 모토롤라 68HC11K1 마이크로 컨트롤러는 파워를 올리고 온도 데이터를 수집하고 무선 송수신기의 활성화를 기다립니다. 무선 송수신기에서 데이터 리쿼스트를 받으면 MCU는 온도 데이터를 전송합니다. 문제의 글리치는 60초 사이의 구간에서 시스템이 무변화의 상태로 간주하여 발생되곤 합니다. 이런 비정상을 찾아내고 분석하기위해서 저는 피크 검출 기능을 갖는 딥메모리(1 Mbyte)의 디지털오실로스코프를 사용했습니다. 글리치가 비정기적으로 발생하여 처음에는 스코프의 타임베이스를 60 초의 전체 시퀀스를 잡기위해 10s/div으로 맞추었습니다. 피크 검출 기능이 없었으면 가장 좁은 이벤트는 이 타임베이스 설정에서 검출이 불가능하였을 것입니다. 그러나 그림.2에서 처럼 시스템에서 글리치가 잘 잡히고 잘 보여집니다. 피크 검출은 클럭 이벤트 이후 대략 15초 후에 발생하는 이상한 뭔가를 보여줍니다.
시스템에서 비정상적인 것을 인지하고 딥메모리 스코프에서 쉽게 줌하여 글리치를 더 자세하게 분석 할 수 있었습니다. 1 MB의 스코프 파형 메모리 10 s/div의 타임베이스 설정으로 초기 파형포착은 이후 10 ms/div으로 확대(Figure 3)하여 볼때에도 파형을 자세하게 분석하기에 충분하였습니다.
그림 2. 10 s/div의 타임베이스 설정에 피크 검출 기능을 사용하는 최초 측정.
두번 째 사진 입니다.
그림 3. 글리치가 보이면 더 빠른 타임베이스로 확대하여 필요한 부분을 자세히 관측
세번 째 사진 입니다.
2. 요즘
MegaZoom III 기술은 애질런트가 1996년에 처음 소개한 빠르면서도 긴 메모리 구조의 3세대 입니다. 고해상도의 디스플레이 시스템을 갖는 빠르고 긴 메모리를 조합하여 전보다 더 쉽게 파악하기 어려운 비정상의 신호를 잡습니다.
마지막 사진을 보시면 됩니다.^^;;;
긴 메모리는 높은 샘플링에서도 긴 시간을 볼 수 있도록합니다. 이는 앨리어싱없이도 변조 신호를 관측하고 긴 시스템 부트업 시퀀스를 분석하고 느리고/긴(혼재) 신호들을 더 깊이있게 줌하고 주파수 영역에서는 훌륭한 주파수 분해능을 제공합니다.




[출처] 오실로스코프 측정을 위한 더 좋은 8가지 힌트 - 1|작성자 노바
오실로 스코프를 만들기 위해서 기본적인 개념들을 정리하고 있습니다.^^
1. DSO의 구조
디지탈 오실로스코프는 크게 나누어서 입력부, A/D변환부, 메모리부, 타이밍 발생부, 제어부, 표시부로 나눌 수 있다.
입력부는 일반적인 아날로그 오실로스코프와 거의 동일한 구조로 되어 있고 A/D변환, 메모리부, 타이밍 발생부 및 제어부는 컴퓨터와 유사한 구조로 되어 있고, 표시부는 TV 또는 컴퓨터 모니터와 유사한 방식 및 아날로그 오실로스코프와 같은 방식이다.
디지탈 오실로스코프의 기본적인 성능은 A/D 변환부, 메모리부, 표시부에 달려 있다. A/D 변환부는 측정하는 신호의 분해능, 측정가능 주파수에 영향을 주고, 메모리부 및 표시부는 신호의 표시품질, 측정시간 등에 영향을 준다.
제어부는 가각의 제품마다 고유의 기능을 하는 측정항목 등에 연결이 된다.
2. DSO의 원리
그러면 신호의 변환 원리에 대하여 알아보자. 아날로그 신호은 연속적인 신호이지만 디지탈은 구간구간을 끊어서 측정하여야만 한다. 따라서 한점 한점을 디지탈(숫자)로 바꾸어서 메모리에 넣을 필요성이 생긴다. 디지탈로 변호나을 하기 위해서는 최대에서 최소를 몇 구간으로 할 것인가를 결정해야 한다. 예를 들어 1Vpeak-peak의 전압을 측정하기 위하여 100개로 나눌 것인가, 1000개로 나눌 것인가를 결정한다.
이것은 결국 A/D 컨버터의 비트수에 좌우가 된다. 만약 8Bit의 A/D CONVERTER라면 256개로 나눠지고 10Bit라면 1024개로 나눠지게 되는 것이다. 이것은 수직 분해능이라고 부른다.
위의 예를 분해능으로 바꾸어 표현을 하면 8Bit는 1V/256=3.9mV의 분해능이 10Bit는 1V/1024=0.98mV라는 분해능이 나온다. 이것을 수직 분해능이라고 한다. 수직 분해능이 높을 수록 파형의 재생 효과가 우수하다.
다음은 위에 설명된 분해능으로 측정을 하고 다음 측정할 때 까지의 시간을 샘플 주기라고 하는 데 역수를 취하여 주파수로 변환을 하면 샘플링 스피드라고 한다. 측정할 주기(Time Base)를 최대로 하였을 때 샘플링 스피드가 최대로 되는 데 이때의 주파수를 최대 샘플링 스피드라고 한다.
간혹 선택을 할 때 어느 측정 주기(Time Base)라도 최대 샘플링 스피드로 측정하는 것으로 알고 있는 데 샘플링 스피는 측정 주기(Time Base)에 따라서 변한다. 즉 측정주기가 길어질수록 샘플링 스피드는 높아지게 되어 있다.
다음은 수평분해능에 대하여 알아보도록 한다. 수평분해능은 메모리와 중요한 관계가 있다. 먼저 측정메모리와 실제로 표시되는 메모리의 양이 같은 경우를 알아보자.
이해를 쉽게하기 위하여 측정주기 (Time Base)를 1mS/Div에 두었다고 가정을 하고 표시 메모리가 500개인 경우 수평 전체칸(10칸)이 500개이므로 1Div의 표시 메모리 갯수는 50개로 1mS에 50개의 측정분해능을 가지는 것이다.
따라서 샘플링주파수는 1mS/50=20uS=50KHz이다. 표시 메모리가 10,000개인 경우를 가정을 하면 1Div의 메모리 갯수는 1,000개이므로 샘플링 주파수는 1mS/1000=1MHz가 된다.
측정 가능한 단발 파형의 주파수는 샘플링 주파수에 관계되므로 실제 측정가능 주파수는 샘플링 주파수의 약 1/3로 된다. 따라서 표시 메모리가 500개인 경우 50KHz/3=17KHz의 단발 파형을 측정할 수 있고, 표시 메모리가 10,000개인 경우는 1MHz/3=333KHz의 단발 파형을 측정할 수가 있다. 따라서 동일한 측정주기(Time Base)인 1mS에서도 표시 메모리에 따라서 17KHz, 333KHz라는 큰 차이가 나게 되는 것이다.
3. 샘플링 방법
다음은 샘플링 방법에 대하여 알아보도록 하자. 샘플링은 실시간과 등가시간으로 크게 나뉠 수가 있다.
- 실시간(Real Time) 샘플링
일정한 시간 간격으로 측정을 하여 하나의 화면을 구성한다. 단발 파형이나 연속 파형 양쪽을 측정할 수 있는 반면, A/D 변환 능력의 한계 때문에 최대 샘플링 스피드의 1/3정도가 최대 측정 주파수로 된다.
측정 주기가 낮은 경우에는 표시메모리에 의해 최대 측정 주파수가 결정된다.
- 등가시간(Equivalent Time) 샘플링
이 방법은 측정주기를 일정 갯수로 나누어서 나뉘어진 갯수에 의한 샘플링 스피드에 의하여 측정을 하는 데 한번 측정한 후 약간의 시간차를 두고 다시 측정을 한후 한 화면이 이루어지면 측정한 값을 재배열하여 화면을 표시한다.
즉, 1.5.9.13.2.6.10.14.3.7.11.15.4.8.12.16과 같은 화면 배열이 된다.
따라서 낮은 샘플링 주파수로도 높은 신호를 측정할 수 있는 반면에 연속신호만이 측정가능하고 단발현상이나 불연속 신호는 측정이 불가능하다는 단점이 있다. 이상과 같이 두가지 방식이 있으나 대부분의 DSO는 위의 두가지 샘플링 방법을 채용하고 있다. 즉 낮은 측정주기를 설정하면 실시간 샘플링을 하고 높은 측정주기를 설정하면 등가시간 샘플링을 하도록 자동설정 또는 수동설정을 하도록 하고 있다. 다만 규격서에는 실시간 샘플링에 의한 측정 가능 주파수가 낮으므로 등가시간 샘플링에 의한 측정 가능 주파수만을 기재하는 경우가 있으므로 목적에 맞추어 세밀한 검토를 할 필요성이 있다.
4. 표시 방식
측정된 신호를 표시하는 방식으로는 크게 두가지로 나뉘어질 수가 있다.
-전자 편향방식 (Raster Scan CRT)
일반적인 TV나 모니커와 같은 방식의 표시장치로서 표시를 다양하게 할 수가 있고 신호나 표시를 칼라로 처리를 할수 있는 장점이 있다.
그러나 Raster Scan CRT의 구조적인 분해능 (400X400, 640X480, 1024X768) 이상은 표시를 할 수가 없으므로 표시되는 신호의 품질이 상당히 떨어진다.
1024*7658의 분해능을 가진 CRT를 채용하더라도 실제표시되는 양은 70% 수준 밖에 안되므로 약 700 포인트 정도의 분해능으로 표시가 된다. 결과적으로 느리게 변하는 (사인파 같이) 신호를 분석하는데는 별로 지장이 없지만 날카로운 Peak 파형과 같은 것은 제대로 표시를 할 수 없으므로 표시품질이 상당히 낮아진다.
또한 CRT 주변화로 (특히 DY)에서 나오는 상당한 양의 노이즈로 인하여 수신기 등 노이즈에 민감한 기기를 측정할 수 없다는 단점이 있다.
그러나 다양한 정보를 표시할 수 있고 낮은 제조 원가로 인하여 많은 제조회사들이 채택하고 있다.
-정전 편향방식
아날로그 오실로스코프와 동일한 CRT로서 전압에 의하여 표시위치를 제어하므로 CRT의 구조적인 분해능은 제한이 없으므로 상당한 분해능까지표시가 가능하다. 따라서 10,000포인트 정도로 표시를 하게되면 아날로그 오실로스코프와 같은 정도로 표시가 가능하여 날카로운 Peak파형이나 잔잔한 노이즈 등을 정확히 분석을 할 수 있는 장점이 있다. 그러나 파형을 재생하기 위해서는 D/A Converter를 채용하여야 하므로 제조원가가 높아지고 신호의 칼라처리가 불가능하다는 단점이 있다.
5. 표시 방법
측정된 신호를 표시하는 방법은 Dot표시, 직전보간, 사인 보간 등 세가지로 나뉘어질 수가 있다.
-Dot 표시
측정된 신호를 측정점 위치에 점으로 표시를 한다. 점으로 표시되는 관계로 한눈에 알아보기 힘이 들고 측정점이 일정 갯수 이하로 떨어지면 파형을 알아 볼 수가 없게 된다. 그러므로 측정 분해능을 알아볼 수가 없게 된다. 그러므로 측정 분해능을 알아볼 경우가 아니면 사용을 하지 않는다. 즉, 이기능을 이용하여 DSO의 분해능을 알아볼 수가 있다. 높은 주파수의 파형을 측정할 때 Dpt 표시 상태로 두고 급격하게 변하는 부분을 관찰하면 Dot가 보인다. 이때 Dot가 보이는 양이 많으면 분해능이 높은 것이고 적으면 분해능이 낮은 것이다. 실제로 분해능이 낮은 DSO는 Dot표시와 Line표시가 많은 차이를 나타내나 분해능이 높은 DSO는 별로 차이를 느끼지 못한다.
- Line 표시
측정점과 측정점 사이를 직선으로 연결을 한다. 따라서 한 주기당 10개 이상의 측정점이 있어야 파형의 형태를 인식할 수 있다. 이 방법은 단발 현상이나 불연속 파형을 측정할 때 주로 사용한다.
- 사인 표시
측정점과 측정점 사이를 사인공식에 의한 곡선으로 연결을 한다. 따라서 측정점이 불충분할 경우라도 어느 정도까지는 재새잉 가능하다. 그러나 사인 파형을 측정할 경우에만 제대로 표시가 되고 단발 파형이나 불연속 파형에 적용하면 왜곡된 파형으로 표시될 수도 있다.
6. 표시 모드
- Normal 모드
한 화면의 측정이 끝나면 화면에 표시를 하여준다. 이 때 화면에 표시되는 주기는 메모리, 제어부에 따라서 큰 차이를 보인다. 일반적인 DSO는 아날로그 오실로스코프에 비하여 현저한 속도차이를 보이나 최근 들어서 여러가지 기술의 발전에 의해 일반적인 DSO가 50 ~100mS나 15mS까지의 제품도 개발이 되어서 초당 62화면을 표시할 수가 있다.
-Peak 모드
디지탈로 변환을 하는 관계로 측정점과 측정점 사이에 큰 신호가 있을 경우 측정이 불가능해지는 것을 막기 위하여 한번 측정을 한후 다음 측정점 이전에 큰 신호가 있을 경우 이 신호를 다음 측정점까지 유지(Peak Detecter에 의하여)를 하고 있다가 다음 측정점에서 이 신호를 측정을 한다.
일반적으로 Peak 측정의 최대값과 최소값이 동시에 측정된다.
-Roll 모드
낮은 주기로 측정을 하느 경우 한 화면이 측정이 된 후 표시가 되면 상당한 시간이 지나야 하므로 측정되는 순간순간을 볼 수 있도록 하는 모드이다.
또한 Peak Detect 모드를 병용하면 느린 측정에도 높은 주파수 성분도 측정이 가능하다. 실제 화면 표시는 Chart Recorder와 같이 동작을 하므로 느린 주기로 느리게 변하는 신호를 분석하기에는 최적인 모드이다. DSO만이 가질 수 있는 독특한 모드이다.
- 기 타
그 이외에 Average, X-Y, 가감산, 미적분, TV의 4~8 Field의 선택표시, DC Offset 기능, Dual Window 등의 다양한 기능들이 선보이고 있다.
[출처] 디지털 오실로스코프의 구조 및 원리|작성자 제니
-------------------------------------------------------------------------------------------------
오실로 스코프를 만들기 위한 이론 모음 중입니다.

